【Transformer 论文精读】……Swin Transformer……(Hierarchical Vision Transformer using Shifted Windows)
文章目录
- 一、Abstract(摘要)
- 二、Introduction(引言)
- 三、Related Work(相关工作)
- 四、Method(方法)
-
- 1.Patch Merging模块
- 2.W-MSA模块
- 3.SW-MSA、masked MSA模块
- 五、Conclusion(结论)
- 六、小总结
论文题目: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文下载地址: https://arxiv.org/pdf/2103.14030.pdf
论文用的是2021 8月17日的版本。
Swin Transformer是ICCV 2021的最佳论文,这一篇论文是继Vit之后的Transformer在CV领域的巅峰之作。
在paperwithcode上可以看到,SwinV2版本已经将coco数据集的精确度刷到了63.1%,而卷积系列还在50%+。Swin很可能引领之后的CV领域。
这是基于Vit的一篇论文,可以看一下我之前的Vit阅读笔记:
- Vit阅读笔记
一、Abstract(摘要)
作者在摘要中说他提出了一个Swin Transformer的模型,可以当backbone。
之前在Vit的结尾,Vit的作者说他的Vit模型并不能用于全部的CV领域工作,留了一些分割啊等等任务给后人,所以Swin作者摘要中就直接说他的Swin墨西哥可以当backbone,算是填补了Vit留下的坑吧。
紧接着作者提出了将Transformer从NLP搬到CV面临的关键问题:
- 一个是尺度问题,图片里包含的信息很多,可能有蚂蚁大小,也可能有高楼大小的不同尺度。
- 另一个就是图片分辨率(resolution )太大了,如果以像素点为单位,则计算量爆炸,序列长度爆炸,所以之前Vit提出了patch方案,或小窗口+自注意力等,都是为了解决序列长度问题。
为了解决这两个问题,作者提出了一个叫 Hierarchical Transformer的模型,使用shifted windows(移动窗口)的方法。
随后作者说到移动窗口的好处,这好处当然就是解决了上面的两个问题,因为是变成了更小的窗口,所以序列长度问题得到解决,因为自注意力在一个小窗口内计算,所以计算复杂度直线下降,且通过移动使得相邻的窗口之间有了联系,整合了各个尺度的信息。
感觉这滑动窗口式的操作有点CNN感受野那味了,如果不是看到了Swin的实验结果,我还以为是那个学术机构在水论文,这是直接给CNN感受野套壳啊,哈哈,不过Swin的这个实验结果,基本霸榜了很多数据集,所以这里只能说是抽取了CNN的部分优点拿过来用了。
二、Introduction(引言)
引言的前两段又是凑字数凑格式的话,就将了一下Alex引领的CNN主导CV领域的事,一直以来都是挤牙膏式的发展,没什么大突破,作者意在完全抛弃CNN,创建一个新的模型方法,但是Vit已经把这个事干了,但是Vit并不是所有的CV领域都可以做,所以这篇论文的作者要填Vit的坑,让Transformer在所有的CV领域 比如分割等都可以做。
第三段作者开始介绍她的模型,给了一张图:
这里的模型和过程在后续的method里会详细说。

右边就是Vit的图,分成16 * 16的小patch,图里写的16x就是16倍下采样率,Vit始终在整个图上进行自注意力,并且没有多尺度特征。
左边就是本篇论文图了,我们知道,对于CV的下游任务,比如密集的检测和分割,融合底层和高层的特征信息对结果有较显著提升,大多数使用了FPN技术,FPN就是多层联级金字塔,使用了bottom-up与top-down方法,融合了底层和高层的特征,解决了语义鸿沟问题,详细:FPN论文笔记。
Swin不同于Vit,Vit是在整个图上自注意力,而Swin是在每一个小格子里自自注意力。
Swin解决多尺度的方法也很简单,一开始是4倍下采样率,然后是8倍.16倍。也就是说,每次会融合相邻的4个patch变成一个大的patch,这个大patch感受野可以感受到之前四个小patch的特征,从而抓住了多尺寸的特征。
有了多尺寸的特征图,给FPN就可以做检测了,给U-NET就可以做分割了,所以作者说他的模型可以做骨干网络back-bone。
第四段作者开始讲他Swin的移动窗口操作,看一下作者给的图:

图里每一个小方块就是一个patch(4 * 4),每一个红框就是一个窗口,本论文中一个红色窗口里有49个小patch。
原本每一个红色窗口里的小patch和其他红色窗口里的patch是没有互动的,而当红色窗口移动后,原本不属于一个红色窗口里的patch可以互动了,也就是因为移动,使得不同patch移动到一个红色窗口里了,这样再自注意力,看似是窗口内的局部注意力,实际上通过移动后就近似于全局注意力了。
引言的最后作者展望了一下Transformer的大一统结局。
三、Related Work(相关工作)
又是车轱辘话来回说,先介绍了传统的CNN和变体,然后又介绍了一下之前Transformer中自注意力的工作,没什么可看的,下一章!
四、Method(方法)
这一章就是模型的详细介绍了。
作者给出了模型总览图:

在Swim这篇论文中的patch是4 * 4 不是Vit里的16 * 16了。
这里很多的参数维度变换就不说了,主要是搞懂里面的各个模块。
几个模块:
- Swim Transformer Block
- Patch Merging
其中 Transformer Block的图论文中也给出来了:

其中LN和MLP之前都学过了,就一个W-MSA和SW-MSA需要看一下。
所以实际上Swim模型就三个模块要学习:
- Patch Merging
- W-MAS
- SW-MSA
下面逐一来看。
1.Patch Merging模块
相当于CNN里的池化操作。
在网上找了张图便于理解, 图源:bilibili:霹雳吧拉Wz

这个图画的很清晰,
- 第一步先提取每个2 * 2 相同位置的patch放到一起,这里就是隔点采样,或者理解成空洞卷积?
- 然后在深度方向进行拼接。
- 最后经过LN层,然后再线性层(1*1卷积)。
- 最终得到的长宽缩减一半,深度扩大一倍。
2.W-MSA模块
Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。
在用一次这个图:

在计算自注意力的时候,Vit是在全局上做自注意力,也就是每个patch两两之间都要做计算,比如有1234一共四个Patch,则12,13,14,23,24,34这样两两之间做计算。
这样就带来一个问题,随着图片的增大,这个计算量是爆炸的。
所以Swin就分成好几个大的块(左边红色的窗口),自注意力在每个大的块之内进行,块之间的patch是没有交互的,这样就大大降低了计算复杂度。这就是W-MSA。
在论文中作者有给出公式对比两种自注意力的复杂度,就不看公式了,两者相差几十甚至上百倍,记个结论算了哈哈。
3.SW-MSA、masked MSA模块
Shifted Windows Multi-Head Self-Attention (SW-MSA)。
上面的W-MSA虽然解决了计算量的问题,但是也引入了一个新的问题,就是各个红框的大patch(窗口)之间的小patch没办法交互了,损失了一定的全局建模能力。所以为了弥补这个缺陷,提出了SW-MSA模块。
再看一下论文中给的那个移动的图:
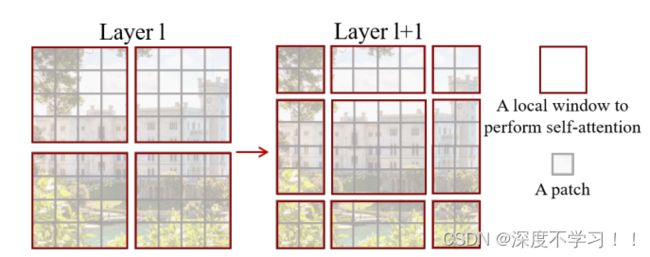
乍一看不是很好理解,看一下下面的过程。
移动过程看图:
图源还是bilibili霹雳巴拉
原始:

向右,向下移动两个单位:

这样进行移动,就弥补了W-MSA里的缺陷,可以融合不同Windows里的patch信息了。
这样又出现了一个新的问题:
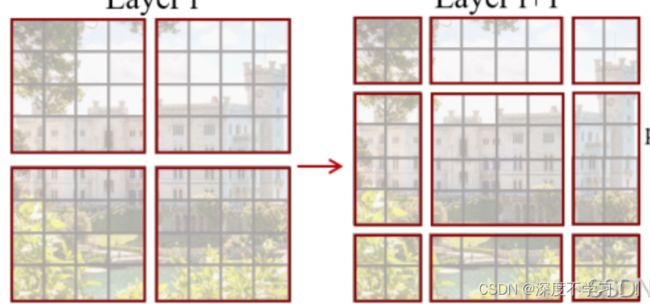
原来是四个Windows,移动之后变成9个Windows,那就要在这新的9个Windows上做自注意力,这无疑是拆东墙补西墙的操作,计算量又增加了。
作者提出了弥补方法:

在网上找了个比较好理解的过程图,继续偷图哈哈。
我严重怀疑作者的思路是玩七巧板的来的~~~~
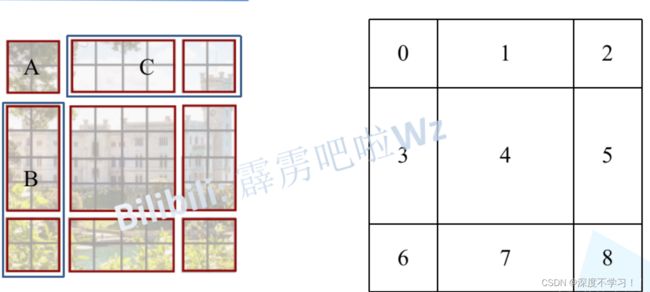
将移动后的区域标号,A对应0,C对应1+2,B对应3+6.
开始变换,将区域A,C移动到最下方:

再将BA区域移动到最右边:
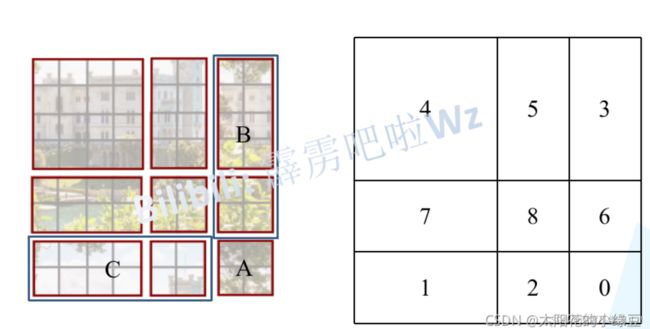
可以看到当现在移动完成之后,左上角的红色框window就是4 * 4的,右边B和中间的一个小长条组合变成 4 * 4(5和3区域),左下角两个躺着的长方形组成4 * 4 (1和7区域).右小角四个小2 * 2 组成4 * 4 (8.2.6.0区域)。这样一来就又是4个4 * 4 的window,跟移动之前的window是一样的。
但是这样又引来一个问题就是 原本的3和5区域不是挨着的,不在一块。但是现在3和5强行组成一个windos,在这个windos里做自注意力会出问题。
作者又提出一个模块来解决这个问题就是 masked MSA即带蒙板mask的MSA。 关于masked MSA计算过程,我看了一边不是特别理解,就是上述的两个区域3和5分别计算,在计算的过程将其中一个区域的权重值-100,然后softmax之后就变成0了,这样就分割开两个区域了。(这里其实没太搞懂,这样的话计算量应该是线性增加了一些,并不是和移动之前的一样吧?我没太想深究,感觉可以直接记结论。)
全部计算完成后要将数据挪回原来的位置上。
五、Conclusion(结论)
结论按照惯例继续车轱辘话来回说,作者提出了一种层级式的Transformer模型,叫做Swim Transformer,计算复杂度很低,与输入模型呈线性增长,已经是SOTA了,作者希望Swim在多模态方面出现更多更好的工作。
第二段作者说Swim的最主要贡献是提出移动窗口(shifted window)的自注意力,对很多CV下游任务很有帮助,但是这个模块没有放到NLP上,那就违背了他开始说的模型大一统的理念,所以作者后面的工作想将移动窗口的工作放到NLP上。
六、小总结
- 将层次性、局部性和平移不变性等先验引入Transformer网络结构设计。
- Swim并没有像Vit那样使用cls token。
- 加入了类似于CNN池化层的操作 Patch Merging。
- 主要贡献是提出了 Shifted Windows 移动窗口的自注意力模型。
- 因为提出的移动窗口,从而使Swim可以彻底的应用在CV的各个领域中了,Swim可以作为back bone主干网络。
- 移动窗口和相对位置编码对分类任务提升效果不显著,对下游任务,分割检测等提升效果显著。
Swim在CV领域大杀四方啊,感觉以后论文都免不了和Swim进行比较了。