WWW2022 | 基于领域增强的图对比协同过滤方法+代码实践
嘿,记得给“机器学习与推荐算法”添加星标
今天跟大家分享一篇将对比学习应用于图协同过滤方法的文章,该论文发表于WWW2022会议上。其主要思想是在图神经网络协同过滤方法上应用了两种领域类型的对比学习方法,分别是显式的结构领域和隐式的语义间的领域,相比于随机采样的对比学习方式,其挖掘了用户或者物品的邻居关系并开发了对比学习在推荐系统上的潜力,实验表明该方法在多个数据集上取得了良好的推荐性能。

论文:https://arxiv.org/abs/2202.06200
代码:https://github.com/RUCAIBox/NCL/blob/master/ncl.py
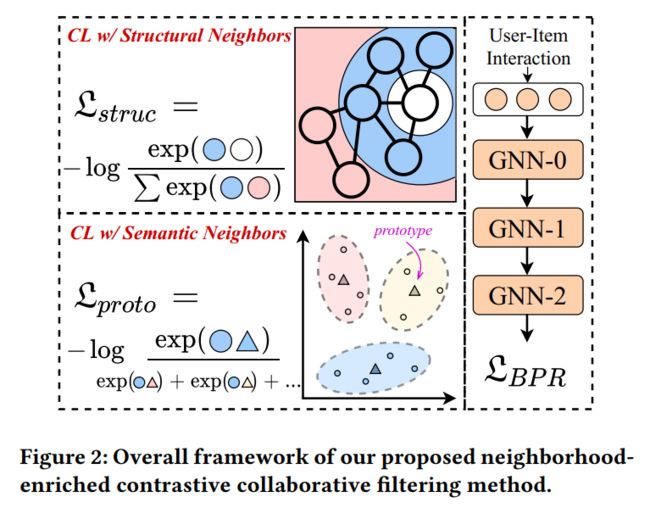
近年来,图协同过滤方法得到了非常广泛的关注。虽然可以实现较好的推荐性能,但其仍然存在数据稀疏等问题。为了缓解数据稀疏问题,常见的做法是在图协同过滤方法的基础上引用对比学习。然而,当前主流的基于对比学习的图协同过滤方法主要通过随机采样的方式来构建对比对,但这样的方式忽略了用户或者物品间的邻居关系,因此不能将对比学习推荐方法的威力发挥到极致。基于此,该文提出了一种邻域增强的对比学习推荐方法NCL。
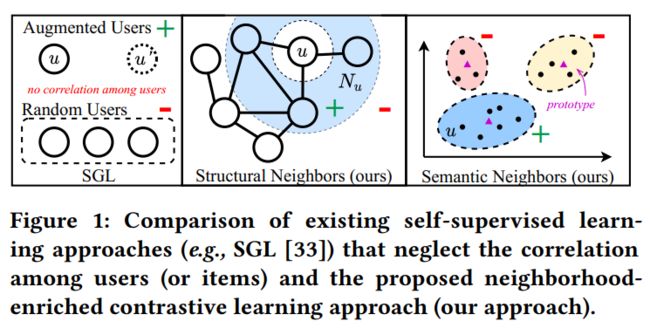
其可以显式的将潜在的邻域信息建模在对比对中。其中本文从图结构和语义空间中引用了两种具体的邻域对比对,即结构对比对(structure contrastive pair)和语义对比对(semantic contrastive pair),更加直观的图示可见图1。对于结构对比对,主要是从交互图中提取的,其将当前用户以及当前用户的邻居当做正对比对。对于语义对比对,主要是在Embedding空间中将当前用户的Embedding与所在的簇中心Embedding当做正样本。
该方法将LightGCN作为backbone,通常经过propagate和readout过程来生成用户和物品的特征表示,具体的公式如下:
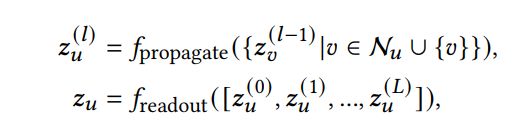
其中表示第层用户的特征表示,表示用户的邻居,表示GNN的层数,表示用户的初始Embedding。聚合了该用户和其邻居在第层的特征表示。整合了层的特征表示以此来获得对于用户在多阶邻居上的语义特征表示,常见的readout操作比如last-layer only、concatenation以及weighted sum等。物品的特征表示具有类似的上述过程。
该方法在聚合的过程中丢弃了非线性变换、特征转换以及自连接,所以对于用户和物品的特征聚合形式如下:
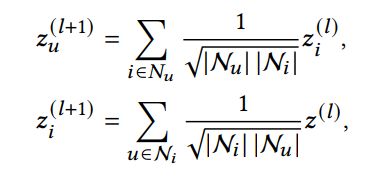
all_embeddings = self.get_ego_embeddings()
embeddings_list = [all_embeddings]
for layer_idx in range(max(self.n_layers, self.hyper_layers * 2)):
all_embeddings = torch.sparse.mm(self.norm_adj_mat, all_embeddings)
embeddings_list.append(all_embeddings)该方法在生成最终的第层表示时采用加权求和(weighted sum)的方法,具体形式如下:
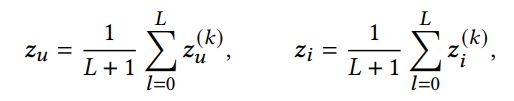
lightgcn_all_embeddings = torch.stack(
embeddings_list[: self.n_layers + 1], dim=1
)
lightgcn_all_embeddings = torch.mean(lightgcn_all_embeddings, dim=1)当获得用户和物品的特征表示后采用内积的方式进行推荐,即。
def predict(self, interaction):
user = interaction[self.USER_ID]
item = interaction[self.ITEM_ID]
user_all_embeddings, item_all_embeddings, embeddings_list = self.forward()
u_embeddings = user_all_embeddings[user]
i_embeddings = item_all_embeddings[item]
scores = torch.mul(u_embeddings, i_embeddings).sum(dim=1)
return scores然后采用BPR损失进行监督式训练。
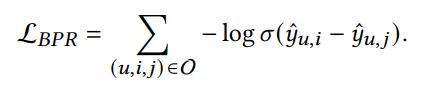
gamma = 1e-10
pos_score = torch.randn(3, requires_grad=True)
neg_score = torch.randn(3, requires_grad=True)
loss = -torch.log(gamma + torch.sigmoid(pos_score - neg_score)).mean()通过优化BPR损失可以对用户和物品之间的交互进行建模。然而,用户(或物品)内的高阶邻居关系对于推荐也是有价值的。例如,用户更有可能购买与邻居相同的产品。接下来将介绍本文所提出的两个对比学习对,以捕捉用户和物品的潜在邻居关系。具体的示意图如下图所示。
基于结构邻域的对比学习
为了充分利用对比学习的优势,首先将每个用户(或物品)与其显式的结构邻居进行对比,然后再通过GNN进行聚合得到最终的表示。其中,基本GNN模型的第层的输出表示每个节点跳结构邻居的加权和,因此可以利用其偶数跳的输出来表示该节点的结构领域。具体而言,我们将用户自身的嵌入和偶数层GNN的相应输出的嵌入视为正对比对。基于InfoNCE损失来进行优化,具体如下所示:
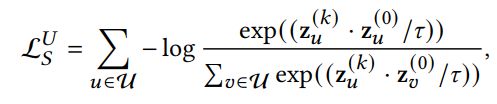
其中,表示GNN模型层的输出,也就是用户的阶邻居的表示,当然得是偶数。表示当前用户的特征表示。同理物品侧的对比损失如下:
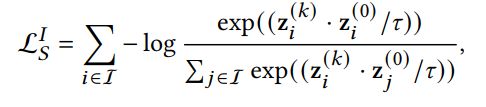
def ssl_layer_loss(self, current_embedding, previous_embedding, user, item):
current_user_embeddings, current_item_embeddings = torch.split(
current_embedding, [self.n_users, self.n_items]
)
previous_user_embeddings_all, previous_item_embeddings_all = torch.split(
previous_embedding, [self.n_users, self.n_items]
)
current_user_embeddings = current_user_embeddings[user]
previous_user_embeddings = previous_user_embeddings_all[user]
norm_user_emb1 = F.normalize(current_user_embeddings)
norm_user_emb2 = F.normalize(previous_user_embeddings)
norm_all_user_emb = F.normalize(previous_user_embeddings_all)
pos_score_user = torch.mul(norm_user_emb1, norm_user_emb2).sum(dim=1)
ttl_score_user = torch.matmul(norm_user_emb1, norm_all_user_emb.transpose(0, 1))
pos_score_user = torch.exp(pos_score_user / self.ssl_temp)
ttl_score_user = torch.exp(ttl_score_user / self.ssl_temp).sum(dim=1)
ssl_loss_user = -torch.log(pos_score_user / ttl_score_user).sum()
current_item_embeddings = current_item_embeddings[item]
previous_item_embeddings = previous_item_embeddings_all[item]
norm_item_emb1 = F.normalize(current_item_embeddings)
norm_item_emb2 = F.normalize(previous_item_embeddings)
norm_all_item_emb = F.normalize(previous_item_embeddings_all)
pos_score_item = torch.mul(norm_item_emb1, norm_item_emb2).sum(dim=1)
ttl_score_item = torch.matmul(norm_item_emb1, norm_all_item_emb.transpose(0, 1))
pos_score_item = torch.exp(pos_score_item / self.ssl_temp)
ttl_score_item = torch.exp(ttl_score_item / self.ssl_temp).sum(dim=1)
ssl_loss_item = -torch.log(pos_score_item / ttl_score_item).sum()
ssl_loss = self.ssl_reg * (ssl_loss_user + self.alpha * ssl_loss_item)
return ssl_loss基于语义邻域的对比学习
基于结构领域的对比对显式地建模了由交互图定义的邻居。然而,结构对比损失对用户/物品的同质邻居一视同仁,这不可避免地将噪声信息引入到对比对中为了减轻这种印象,本文考虑将语义空间的领域信息引用对比学习中。具体的,通过学习每个用户和物品的潜在原型(prototype)来构造语义邻居。基于这一思想,进一步提出了原型对比目标,以探索潜在的语义邻居,并将其纳入对比学习中,以更好地捕捉协同过滤中用户和物品的语义特征。特别是,相似的用户/物品往往落在相邻的嵌入空间中,原型是指一组语义邻居的集群的中心。因此,本文将聚类算法应用于用户和物品的嵌入,以获得用户或物品的原型。由于该过程不能进行端到端优化,所以使用EM算法学习所提出的原型对比目标。形式上,GNN模型的目标是最大化以下对数似然函数:
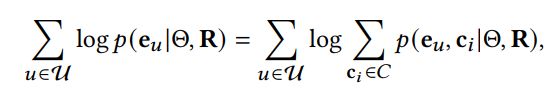
其中,表示模型参数,表示交互矩阵,表示用户的原型,表示当前用户的向量表示。
def e_step(self):
user_embeddings = self.user_embedding.weight.detach().cpu().numpy()
item_embeddings = self.item_embedding.weight.detach().cpu().numpy()
self.user_centroids, self.user_2cluster = self.run_kmeans(user_embeddings)
self.item_centroids, self.item_2cluster = self.run_kmeans(item_embeddings)
def run_kmeans(self, x):
"""Run K-means algorithm to get k clusters of the input tensor x"""
import faiss
kmeans = faiss.Kmeans(d=self.latent_dim, k=self.k, gpu=True)
kmeans.train(x)
cluster_cents = kmeans.centroids
_, I = kmeans.index.search(x, 1)
# convert to cuda Tensors for broadcast
centroids = torch.Tensor(cluster_cents).to(self.device)
centroids = F.normalize(centroids, p=2, dim=1)
node2cluster = torch.LongTensor(I).squeeze().to(self.device)
return centroids, node2cluster然后再根据用户当前的向量表示以及原型进行优化,因此基于原型对比对的InfoNCF损失如下:
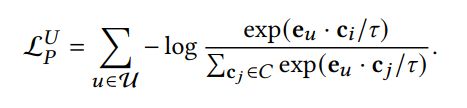
其中,表示用户的原型,其是通过K-means聚类算法来计算得出的,一共有个聚类中心。同理物品侧的损失函数如下:
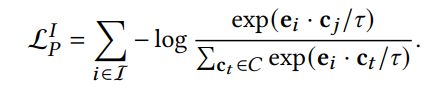
def ProtoNCE_loss(self, node_embedding, user, item):
user_embeddings_all, item_embeddings_all = torch.split(
node_embedding, [self.n_users, self.n_items]
)
user_embeddings = user_embeddings_all[user] # [B, e]
norm_user_embeddings = F.normalize(user_embeddings)
user2cluster = self.user_2cluster[user] # [B,]
user2centroids = self.user_centroids[user2cluster] # [B, e]
pos_score_user = torch.mul(norm_user_embeddings, user2centroids).sum(dim=1)
pos_score_user = torch.exp(pos_score_user / self.ssl_temp)
ttl_score_user = torch.matmul(
norm_user_embeddings, self.user_centroids.transpose(0, 1)
)
ttl_score_user = torch.exp(ttl_score_user / self.ssl_temp).sum(dim=1)
proto_nce_loss_user = -torch.log(pos_score_user / ttl_score_user).sum()
item_embeddings = item_embeddings_all[item]
norm_item_embeddings = F.normalize(item_embeddings)
item2cluster = self.item_2cluster[item] # [B, ]
item2centroids = self.item_centroids[item2cluster] # [B, e]
pos_score_item = torch.mul(norm_item_embeddings, item2centroids).sum(dim=1)
pos_score_item = torch.exp(pos_score_item / self.ssl_temp)
ttl_score_item = torch.matmul(
norm_item_embeddings, self.item_centroids.transpose(0, 1)
)
ttl_score_item = torch.exp(ttl_score_item / self.ssl_temp).sum(dim=1)
proto_nce_loss_item = -torch.log(pos_score_item / ttl_score_item).sum()
proto_nce_loss = self.proto_reg * (proto_nce_loss_user + proto_nce_loss_item)
return proto_nce_loss最终通过将以上损失函数进行相加然后通过Adama优化算法进行优化,值得注意的是,在计算原型的过程中不是端到端的,因此需要EM算法来交替更新用户和物品的特征向量以及它们的原型向量。
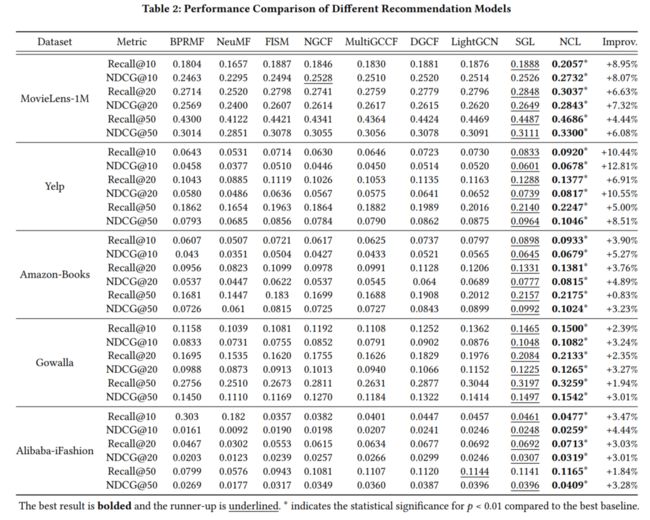
最后该算法在5个数据集上对比了8种方法,实验结果表明所提组件在图协同过滤方法上的优越性。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
论文周报 | 推荐系统领域最新研究进展
深度推荐系统调参技巧总结
CCF推荐列表重磅更新, RecSys升级成为B类会议, 中国科学: 信息科学成为A类期刊...
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
喜欢的话点个在看吧