学习Python,像Excel一样使用pandas
欢迎关注微信公众号:excelwork
一直以来,Excel一直作为一个高效的数据展示、处理、分析的工具被我们使用,但随着处理量增大,不可避免的遇到长时间等待响应或干脆“未响应 ”。因此,我们需要找到替代工具来避免此类问题,Python中的pandas是如何像Excel一样处理数据呢。
”。因此,我们需要找到替代工具来避免此类问题,Python中的pandas是如何像Excel一样处理数据呢。
先构造示例数据(python3):
import pandas as pddata=pd.DataFrame([{2,5,6,7,8},(2,5,6,7,8),[12,31,4,5,6],range(11,111,20),range(9,23,3)],columns=['col_a','col_b','col_c','col_d','col_e'],index=['row_1','row_2','row_3','row_4','row_5'])
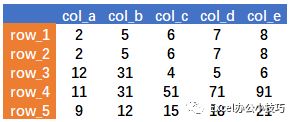
一、数据筛选、替换
1.1 数据筛选
我们通常使用去除重复项功能,目的就在于此,pandas中使用drop_duplicates函数实现,参数默认情况下是保留重复值中的一个,或者keep='first'。
print(data[data['col_a']>2])#或者print(data[data.loc[:,'col_a']>2])

可以看到,col_a列数值大于2的数据已经被筛选出来了。
1.2 数据替换
1.2.1 一对一替换
pandas有replace函数,可直接使用。
print(data.replace(2,111))#或者data.loc[data['col_a']==2,'col_a']=222print(data)
![]()
可以看到,col_a列数值等于2的数据被替换成了111。
1.2.2 多对多替换
或者,我们也可以批量替换。
比如将等于2的,替换为222,等于5的替换为555,两个列表个数相同,会按对应的顺序替换;
print(data.replace([2,5],[222,555]))
1.2.3 多对一替换
如果个数不同,替换后的值不能使用列表,要替换的值可以使用列表;
print(data.replace([2,5,6],222))
1.2.4 整列替换
对整列数据批量替换成同一值;直接赋值即可。
data['col_a']=123print(data)

二、删除重复项
2.1 重复值保留一个
我们通常使用去除重复项功能,目的就在于此,pandas中使用drop_duplicates函数实现,参数默认情况下是保留重复值中的一个,或者keep='first'。
print(data.drop_duplicates(keep='first'))![]()
可以看到,row_2行数据被删除,保留了row_1行数据。
2.2 重复值全部删除
方法适用于不需要保留出现重复数据记录的场景,通常我们在excel里很能直接点击操作处理,不过在pandas中仍使用drop_duplicates函数实现,只需要将keep=False即可。
print(data.drop_duplicates(keep=False))
可以看到,row_1~2两行数据都被删除,只保留了没重复的row_3~5行数据。
2.3 只保留重复值
存在这样的场景,我们需要拿到重复的数据,分析是由于什么场景导致的分析。好,我们继续使用drop_duplicates函数,只多了一步构造:
-
先根据keep=False得到剔除重复值的数据集(输出row_3~5);
-
再使用append将重复值保留一个的dataframe(即将不重复数据集构造成有重复值的数据集,输出row_3~5+row_1+row_3~5)
-
最后去重,就会将原来不重复的数据剔除了(输出row_1)
print(data.drop_duplicates(keep='first'))
可以看到,row_2行数据被删除,保留了row_1行数据。
三、排序
3.1 根据某一字段升降序
排序函数直接使用sort_values,通过by选择排序依据的字段,根据参数ascending判别是升序还是降序。下面数据集通过col_a列数值大小升序:
print(data.sort_values(by='col_a',ascending=True))![]()
3.2 根据多字段升降序
通过col_a列数值升序,col_c列降序,可使用列表存放。
print(data.sort_values(by=['col_a','col_c'],ascending=[True,False]))
四、数据透视表
像Excel的透视表一样透视数据,pandas里有个强大的函数pivot_table,我们同样可以选择行标签和列字段列表,选择需要的函数类型。
先添加两列,再根据两列字段分组:
data['newindex']=['test1','test2','test3','test2','test1']data['newcate']=['cate1','cate2','cate2','cate2','cate1']print(pd.pivot_table(data,index=['newcate','newindex'],aggfunc='count',values=['col_a','col_b','col_c','col_d','col_e']))

五、数据列名修改
修改列名,使用rename函数,传入字典,可进行一个或多个列同时更名;
data.rename(columns={'col_a':'列a','col_b':'列b'},inplace=True)print(data)

如果替换失败想提示一下,则使用error='raise',来抛出异常。比如对col_bb进行更名,但没有此列,则抛出异常
data.rename(columns={'col_a':'列a','col_bb':'列b'},inplace=True,error='raise')print(data)
TypeError: rename() got an unexpected keyword argument "error"