跟踪算法总结
目前业内公认效果比较好的跟踪算法:
Deep-sort和FairMOT,二者主要区别在于:FairMOT是一个集成检测、跟踪的端到端算法,检测部分基于centerNet,跟踪部分类似deep-sort。
个人认为跟踪算法性能的优劣取决于两方面:(1)检测器的性能;(2)跟踪策略。
常用的检测网络:
单阶检测:
(1)YOLOv3/YOLOv4;
(2)centerNet;
(3)RefineDet;
两阶检测:
(1)faster-Rcnn
对比FairMOT和yolov4+deep_sort的实际效果:
(1)运行帧率:前者fps=10,后者fps=30;
(2)id:前者35,后者17
跟踪主流算法分类

(1)SDE;
(2)Two-stage
(3)JDF
1、SDE(Separate Detection and Embedding)
tracking by detection 。
该类范式因为通俗易懂,且表现出了不俗的追踪精度,在2015年到2018年,一度成为MOT的主流范式。该范式首先通过检测器(detector)检测出画面中物体所在的检测框,然后根据物体检测框移动的规律(运动特征)和检测框中物体的外观特征(通常通过一个ReID网络抽取一个低维的向量,叫做embedding向量)来进行前后帧同一物体的匹配,从而实现多目标追踪。
该类范式将MOT分为了两步,即
物体检测
特征提取与物体关联
该类方法检测与特征提取是分开的,所以又被称为SDE
SDE存在的最大缺点就是速度慢,因为将物体检测和(外观)特征提取分开,检测速度自然就下去了。
2、Two-stage
联合检测器和嵌入学习的一种选择是采用FasterR-CNN框架,这是一种两级检测器:
(1)第一个阶段,区域优先网络(RPN),与FasterR-CNN保持相同,并输出检测到的边界框;
(2)第二阶段,Fast R-CNN通过用度量学习监督取代分类监督来转化为嵌入学习模型。
(3)两阶段共享算法Track R-CNN 就是对 Mask R-CNN 进行扩展,使用 roi-pool 从共享的特征图中获取候选框所对应的图像特征,并通过一个轻量的网络针对每一个候选框同时进行:1)检测框回归与分类;2)前景 mask回归;3)Re-ID 特征回归
3、JDE(Joint Learning of Detection and Embedding)
主要由两部分组成(1)检测模型----用于目标定位(2)appearance embedding模型----用于数据关联。分别执行两个模型会降低时间效率。
将appearance embedding 模型合并到单个检测器中,以便该模型可以同时输出检测结果和相应的embedding。这样,该系统被表述为一个多任务学习问题:存在多个任务,即锚点分类,边界框回归和嵌入学习; 并自动对单个损失进行加权。
JDE的目的是在单次前向传播中同时输出目标的位置和外观嵌入。假定有一个数据集{I,B,Y},I表示图像帧,B表示此帧中k个目标的边界框注释,y表示部分身份标签标注,其中-1表示目标没有身份标签。 JDE的目的是输出预测的边界框B和外观嵌入F,其中F中的D表示嵌入的维度。应满足以下两个目标。

第一个目标要求模型能够准确检测目标。
第二个目标是要求外观嵌入具有以下特性。连续帧中相同身份的检测框之间的距离应小于不同身份之间的距离。距离度量d(·)可以是欧式距离或余弦距离。 从技术上讲,如果两个目标都得到满足,那么即使是简单的关联策略,例如匈牙利算法,也会产生良好的跟踪结果。
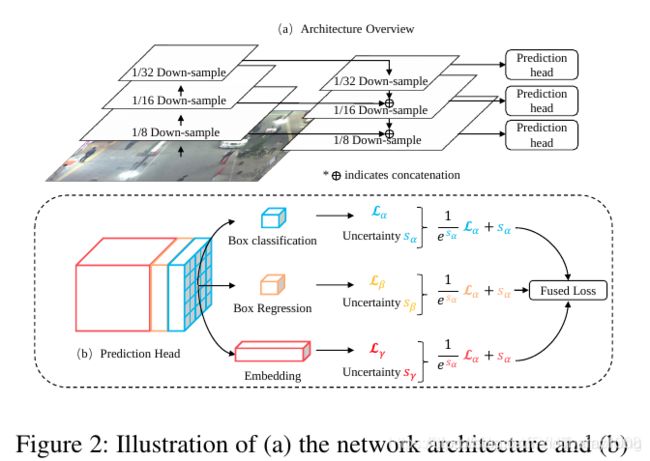
输入视频帧首先经过骨干网络分别获得三个尺度的特征图(1/32、1/16、 1/8的下采样率),然后,通过 skip connection 对具有最小大小(也是语义上最强的特征)的特征图进行上采样并与第二小的比例尺上的特征图相融合,其他比例尺也是如此。最后,将预测头添加到所有三个比例的融合特征图上。预测头由几个堆叠的卷积层组成,并输出一个大小为(6A + D)×H×W的密集预测图,其中A是分配给该比例的锚模板的数量,D是嵌入的维度 。
密集预测图分为三个部分(任务):
1.检测框的分类结果:2A×H×W (A=4)
2.检测框的回归系数:4A×H×W
3.密集嵌入图: D×H×W
(1)Learning to Detect
检测分支类似于标准RPN,这里做出了两个修改。首先,我们根据数量,比例和长宽比重新设计锚,以适应目标,即本例中的行人。根据共同的先验,所有锚点的长宽比均设置为1:3。锚点模板的数量设置为12,使得每个尺度的A = 4,锚点的尺度(宽度)范围为11-512。其次,我们注意到为用于前景/背景分配的双重阈值选择适当的值很重要。通过可视化,我们确定IOU> 0.5 w.r.t. ground truth 大致确保了前景,这与通用对象检测中的通用设置一致。另一方面,IOU <0.4 w.r.t.的框 在我们的案例中,ground truth 应被视为背景,而不是一般情况下的0.3。
(2)Learning Appearance Embeddings
第二个目标是度量学习问题,即学习一个嵌入空间,其中相同身份的实例彼此靠近,而不同身份的实例相距甚远。
为了稳定训练过程并加快融合,(Sohn 2016)提出了在triplet loss的平滑上限上进行优化的建议

(3)Automatic Loss Balancing
JDE中每个预测头的学习目标可以建模为多任务学习问题。联合目标可以表示为每个尺度和每个组成部分的加权线性损失总和。
我们采用(Kendall,Gal和Cipolla 2018)提出的针对任务权重的自动学习方案,采用了任务无关的不确定性概念。 形式上,具有自动损失平衡的学习目标写为

(4)Online Association
在这里我们介绍一种简单快速的在线关联策略,以与JDE结合使用。
对于给定的视频,JDE模型处理每个帧并输出边框和相应的外观嵌入。 因此,我们计算观测值的嵌入与之前存在的轨迹池中的嵌入之间的关联矩阵。 使用匈牙利算法将观测分配给轨迹。 卡尔曼滤波器用于平滑轨迹并预测先前轨迹在当前帧中的位置。如果所分配的观测值在空间上与预测位置相距太远,则该分配将被拒绝。然后,对一个跟踪器的嵌入进行如下更新,如果没有任何观察值分配给Tracklet,则将该Tracklet标记为丢失;如果丢失的时间大于给定的阈值,则标记为已丢失的跟踪,将从当前的跟踪池中删除;或者将在分配步骤中重新找到。
(Deep-Sort)
存在的问题
(1)它效仿 “one-stage” 物体检测器的思路,去掉了 roi-pool 层,但它依然保留了 anchor 的概念,因此也就依然存在多个(不完美匹配的)anchor 对应一个物体的情况。
(2)一个更严重的问题是同一个 anchor(相似的图像区域)可能会对应不同的人,假如一张图像中有两个相邻的人,并且存在一个 anchor 和这两个物体的交集都很大,在前后两个不同的时刻,因为人或相机微小的运动,可能导致该 anchor 需要输出截然不同的身份标识,从而在很大程度上增加了网络学习的难度。
FairMOT
(应该也属于一种JDE)
(1)以 CenterNet 为基础,加入 Re-ID 分支,提出了 FairMOT 方法,使其能够同时进行物体检测和跟踪。
(2)简单来讲,FairMOT 会对每一个像素进行预测,预测其是否是物体的中心、物体的大小和以其为中心的图像区域的 Re-ID 特征。
(3)检测和跟踪两个任务都是以“当前像素”为中心,所以不存在对齐的问题,也不存在严重的顾此失彼的不公平问题,这也是称这个方法为 FairMOT 的原因。

(1)主干网络
采用ResNet-34 作为主干网络,以便在准确性和速度之间取得良好的平衡。为了适应不同规模的对象,将深层聚合(DLA)的一种变体应用于主干网。与原始DLA 不同,它在低层聚合和低层聚合之间具有更多的跳跃连接,类似于特征金字塔网络(FPN)。此外,上采样模块中的所有卷积层都由可变形的卷积层代替,以便它们可以根据对象的尺寸和姿势动态调整感受野。 这些修改也有助于减轻对齐问题。
(2)物体检测分支
本方法中将目标检测视为高分辨率特征图上基于中心的包围盒回归任务。特别是,将三个并行回归头(regression heads)附加到主干网络以分别估计热图,对象中心偏移和边界框大小。 通过对主干网络的输出特征图应用3×3卷积(具有256个通道)来实现每个回归头(head),然后通过1×1卷积层生成最终目标。
1)Heatmap Head
这个head负责估计对象中心的位置。这里采用基于热图的表示法,热图的尺寸为1×H×W。 随着热图中位置和对象中心之间的距离,响应呈指数衰减。
2)Center Offset Head
该head负责更精确地定位对象。ReID功能与对象中心的对齐精准度对于性能至关重要。3)Box Size Head
该部分负责估计每个锚点位置的目标边界框的高度和宽度,与Re-ID功能没有直接关系,但是定位精度将影响对象检测性能的评估。
