机器学习初探:(四)逻辑回归之二分类
(四)逻辑回归 - 二分类

图片出处
文章目录
- (四)逻辑回归 - 二分类
-
- 逻辑回归(Logistic Regression)
-
- 为什么需要逻辑回归?
- 逻辑回归损失函数
- 从计算图的角度理解梯度下降算法
-
- 什么是计算图(Computation Graph)
- 逻辑回归梯度下降算法
- 逻辑回归二分类实例
- 小结
- 参考资料
在 机器学习初探:(一)机器学习绪论一文中,我们介绍了机器学习的基本类型。其中, 有监督学习问题又可分为两类:回归和分类。在前面的文章中,我们讨论了如何使用线性模型进行回归学习,包括预测餐厅利润额、预测房价。在这类问题中,我们根据训练集中的一系列特征,试着 推测出一系列连续值属性,比如利润、房价。那么,要做分类任务该怎么办?我们还可以使用线性回归来解决吗?
先来回顾一下什么是分类问题。它的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。典型的分类问题包括:邮件是否为垃圾邮件、股票是涨还是跌、肿瘤是恶性还是良性等等。分类在计算机科学中具有广泛的应用,从医学图像分析到信用卡欺诈检测,包括语音识别,生物分类,手写体识别,地统计学和药物发现等。
回顾:分类和回归最大的区别在于,我们在试着推测出几个离散值(类别)属性。
我们以一个例子来说明,学生申请大学,学校需要对学生的学习成绩、综合素质等进行评估。评估结果为两种:未被录取(以 0 表示),被录取(以 1 表示)。假设一种简单的情况,Z 校所有申请者都需参加两门考试,根据这两门考试的成绩决定是否发放录取通知书。目前,Z 校收集了所有历史申请人的成绩以及录取结果的信息(如下表),试图构建一个分类模型,可以根据考试成绩预测某一申请人是否会被录取1…
| 观测值 # | 科目一成绩( X 1 X_1 X1) | 科目二成绩( X 2 X_2 X2) | 是否录取( Y Y Y) |
|---|---|---|---|
| 1 | 34 | 78 | 0 |
| 2 | 30 | 43 | 0 |
| 3 | 35 | 72 | 0 |
| 4 | 60 | 86 | 1 |
| … | … | … | |
| 100 | 74 | 89 | 1 |
逻辑回归(Logistic Regression)
为什么需要逻辑回归?
以上的例子是一个二分类任务,其输出标记有两种(即 0 和 1),而线性回归模型产生的预测值 Z = Θ T X Z = \Theta^T X Z=ΘTX 是实值,可能大于 1,也可能小于 0,显然无法直接用于分类问题。那么该怎么办呢?答案蕴涵在下式中:只需找到一个单调可微函数将线性回归模型的预测值映射到分类任务的真实标记 y y y 上2。
有单调可微函数 g ( ⋅ ) g(\cdot) g(⋅) ,令:
y = h Θ ( x ) = g ( Θ T X ) y = h_{\Theta}(x) = g(\Theta^T X) y=hΘ(x)=g(ΘTX)
我们希望 0 ≤ h Θ ( x ) ≤ 1 0\le h_{\Theta}(x) \le 1 0≤hΘ(x)≤1,Sigmoid 函数即可以用作上式中的 g ( ⋅ ) g(\cdot) g(⋅)(Sigmoid 函数形式如图 1 所示),见下式:
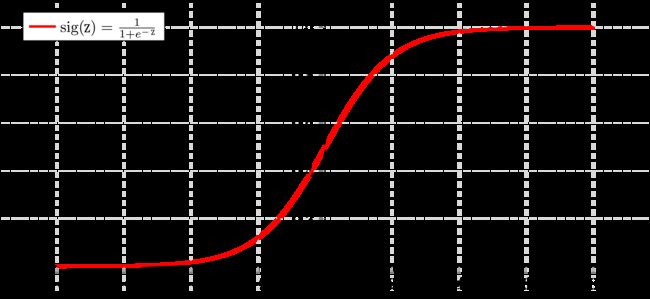
Sigmoid 函数将 z z z 值转化为一个介于 0 和 1 之间的 y y y 值,将Sigmoid函数作为 g ( ⋅ ) g(\cdot) g(⋅) 代入 h Θ ( x ) = g ( Θ T X ) h_{\Theta}(x) = g(\Theta ^T X) hΘ(x)=g(ΘTX) 中,得到:
h Θ ( x ) = 1 1 + e − Θ T X h_\Theta(x) = \frac{1}{1+e^{-\Theta^T X}} hΘ(x)=1+e−ΘTX1
上式对应的模型称为“逻辑回归”(Logistic Regression)。
逻辑回归的预测值 h Θ ( x ) h_\Theta(x) hΘ(x) 为介于 0 和 1之间的值,其可以理解为,在给定的输入 x x x 的取值下,该例的标签 y = 1 y = 1 y=1 的概率。 比如,在本节开篇的例子中,若模型预测值 h Θ ( x ) = 0.7 h_\Theta(x) = 0.7 hΘ(x)=0.7,其表示,基于该名学生的考试成绩,其被录取的概率为 70%。
假设,当 h Θ ( x ) ≥ 0.5 h_\Theta(x) \ge 0.5 hΘ(x)≥0.5 (即,概率值大于50%) 时,预测 y = 1 y = 1 y=1;当 h Θ ( x ) < 0.5 h_\Theta(x) < 0.5 hΘ(x)<0.5 (即,概率值小于50%) 时,预测 y = 0 y = 0 y=0。对应到图1中,即:
y = { 1 , Θ T X ≥ 0 0 , Θ T X < 0 y = \left\{\begin{matrix} 1, \quad \Theta^T X \ge 0\\ 0, \quad \Theta^T X < 0 \end{matrix}\right. y={1,ΘTX≥00,ΘTX<0
其中, Θ T X = 0 \Theta^TX = 0 ΘTX=0 即为区分两个类别的决策边界(Decision Boundary)!
逻辑回归模型的基本形式: h Θ ( x ) = 1 1 + e − Θ T X h_\Theta(x) = \frac{1}{1+e^{-\Theta^T X}} hΘ(x)=1+e−ΘTX1
因而,利用Logistic回归进行分类的主要思想是:根据现有数据对决策边界线建立回归公式,以此进行分类。特别需注意到,虽然它的名字是“回归”,但实际却是一种分类学习方法。这里的“回归”一词源于最佳拟合,表示要找出最佳拟合参数集3。
逻辑回归损失函数
先来回顾一下,我们用到的一些表达式:
-
训练集包括 m m m 个训练样本: { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( m ) , y ( m ) ) } \left\{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(m)},y^{(m)})\right\} {(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
-
每个训练样本: x = [ x 0 x 1 x 2 ⋮ x n ] ∈ R n + 1 x = \begin{bmatrix} x_0\\ x_1 \\ x_2\\ \vdots\\ x_n\\ \end{bmatrix} \in \R^{n+1} x=⎣⎢⎢⎢⎢⎢⎡x0x1x2⋮xn⎦⎥⎥⎥⎥⎥⎤∈Rn+1 ,其中 x 0 = 1 x_0 = 1 x0=1, y ∈ { 0 , 1 } y \in \left \{0,1\right\} y∈{0,1}
-
模型假设: y ^ = h θ ( x ) = 1 1 + e − Θ T x \hat{y} = h_\theta(x) = \frac{1}{1+e^{-\Theta ^T x}} y^=hθ(x)=1+e−ΘTx1, 其中 y ^ \hat{y} y^ 表示 y y y 的预测值
那么,如何找到最佳参数 Θ \Theta Θ 呢?和线性回归问题一样,我们需要定义一个损失函数,来衡量每组参数下模型的预测准确度,从而选出预测效果最好的那组参数。先以只有一个样本的情况为例,逻辑回归的预测误差 Loss( L L L)定义为:
L ( y ^ , y ) = − [ y l o g ( y ^ ) + ( 1 − y ) l o g ( 1 − y ^ ) ] L(\hat{y},y) = -\left[ylog(\hat{y}) + (1-y)log(1-\hat{y})\right] L(y^,y)=−[ylog(y^)+(1−y)log(1−y^)]
这个式子代表什么呢?我们来分别看一下 y = 1 y = 1 y=1 (样本标签为1)和 y = 0 y = 0 y=0 (样本标签为0)两种情况:
如果 y = 1 y = 1 y=1: L ( y ^ , y ) = − l o g ( y ^ ) L(\hat{y},y) = - log(\hat{y}) L(y^,y)=−log(y^), 即预测值 y ^ \hat{y} y^ 趋近于0时, L L L 趋近于无穷大, y ^ \hat{y} y^ 趋近于1时, L L L 趋近于0。
如果 y = 0 y = 0 y=0: L ( y ^ , y ) = − l o g ( 1 − y ^ ) L(\hat{y},y) = - log(1-\hat{y}) L(y^,y)=−log(1−y^), 即预测值 y ^ \hat{y} y^ 趋近于1时, L L L 趋近于无穷大, y ^ \hat{y} y^ 趋近于0时, L L L 趋近于0。
对于一般的有 m m m 个样本的情况,损失函数(Cost function)的形式如下:
J ( Θ ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( y ^ ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − y ^ ( i ) ) ] \begin{aligned} J(\Theta) &= \frac{1}{m} \sum_{i=1}^{m} L(\hat{y}^{(i)},y^{(i)})\\ & = -\frac{1}{m} \sum_{i=1}^{m}[ y^{(i)}log(\hat{y}^{(i)}) + (1-y^{(i)})log(1-\hat{y}^{(i)})] \end{aligned} J(Θ)=m1i=1∑mL(y^(i),y(i))=−m1i=1∑m[y(i)log(y^(i))+(1−y(i))log(1−y^(i))]
与线性回归问题一样,最优参数 Θ \Theta Θ 可以使得损失函数 J ( Θ ) J(\Theta) J(Θ) 最小化:
min Θ J ( Θ ) \min_{\Theta} J(\Theta) ΘminJ(Θ)
求得上述最优参数取值之后,对于一个新的样本 x x x, 我们基于此求得 h Θ ( x ) h_\Theta(x) hΘ(x) 值,用于预测新样本的类别(或属于某一类别的概率):
h Θ ( x ) = 1 1 + e − Θ T x h_\Theta(x) = \frac{1}{1+e ^{-\Theta^T x}} hΘ(x)=1+e−ΘTx1
从计算图的角度理解梯度下降算法
和线性回归问题一样,逻辑回归也可通过梯度下降(Gradient Descent)算法来最小化 J ( Θ ) J(\Theta) J(Θ)。
梯度下降算法更新参数的一般形式为(同时更新所有参数 θ j \theta_j θj):
θ j : = θ j − α δ δ θ j J ( Θ ) \theta_j := \theta_j - \alpha \frac{\delta}{\delta \theta_j} J(\Theta) θj:=θj−αδθjδJ(Θ)
什么是计算图(Computation Graph)
如何求得偏导数 δ δ θ j J ( Θ ) \frac{\delta}{\delta \theta_j} J(\Theta) δθjδJ(Θ) 是梯度下降算法的关键。为了更好理解梯度下降算法,我们通过计算图来说明4。
计算图被定义为有向图,其中节点对应于数学运算。 计算图是表达和评估数学表达式的一种方式。
例如,对于有两个特征变量的逻辑回归,假设只有一个样本,即:
z = θ 0 + θ 1 x 1 + θ 2 x 2 y ^ = h θ ( x ) = σ ( z ) L ( y ^ , y ) = − y l o g ( y ^ ) − ( 1 − y ) l o g ( 1 − y ^ ) \begin{aligned} z &= \theta_0 + \theta_1 x_1 + \theta_2 x_2\\ \hat{y} &= h_\theta(x) = \sigma(z) \\ L(\hat{y},y) & = -ylog(\hat{y}) - (1-y)log(1-\hat{y}) \end{aligned} zy^L(y^,y)=θ0+θ1x1+θ2x2=hθ(x)=σ(z)=−ylog(y^)−(1−y)log(1−y^)
其中, σ ( z ) \sigma(z) σ(z) 代表sigmoid函数。
以上 L ( y ^ , y ) L(\hat{y},y) L(y^,y) 的计算过程表示为计算图即为下图 2:
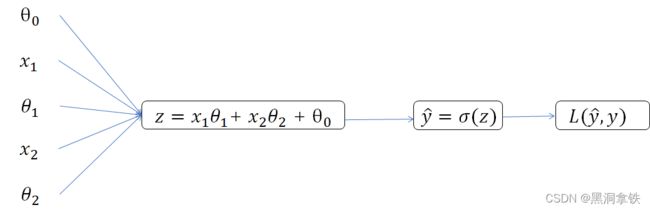
接下来,按照相反的方向(即如下图 3 中红色箭头所示方向)来计算 L ( y ^ , y ) L(\hat{y},y) L(y^,y) 关于 θ i \theta_i θi 的偏导数 δ θ i \delta\theta_i δθi。计算过程使用了复合函数求导的链式法则 (欲了解详情可参见链接:复合函数求导链式法则5),比如,计算 L L L 关于 z z z 的偏导数 δ L δ z \frac{\delta L}{\delta z} δzδL (即,由 L ( y ^ , y ) → y ^ = σ ( z ) L(\hat{y},y) \rarr \hat{y} = \sigma(z) L(y^,y)→y^=σ(z))的过程如下:
δ L ( y ^ , y ) δ z = δ L ( y ^ , y ) δ y ^ × δ y ^ δ z \frac{\delta L(\hat{y},y)}{\delta z} = \frac{\delta L(\hat{y},y)}{\delta \hat{y}} \times \frac{\delta \hat{y}}{\delta z} δzδL(y^,y)=δy^δL(y^,y)×δzδy^
此外,图 3 中的计算使用到了 log函数、Sigmoid 函数,以及函数和、积的求导法则,在此篇中不过多介绍,感兴趣的可以参阅:初等函数求导法则6 自行查阅,看看你能否计算出以下的结果呢?
其余反向传导过程依此类推,直至到输入端,即可得到:
δ θ 0 = δ z = y ^ − y = h θ ( x ) − y δ θ 1 = x 1 ⋅ δ z δ θ 2 = x 2 ⋅ δ z \begin{aligned} \delta \theta_{0} &= \delta z = \hat{y} -y = h_\theta(x) -y\\ \delta \theta_{1} &= x_1 \cdot \delta z\\ \delta \theta_{2} &= x_2 \cdot \delta z \end{aligned} δθ0δθ1δθ2=δz=y^−y=hθ(x)−y=x1⋅δz=x2⋅δz
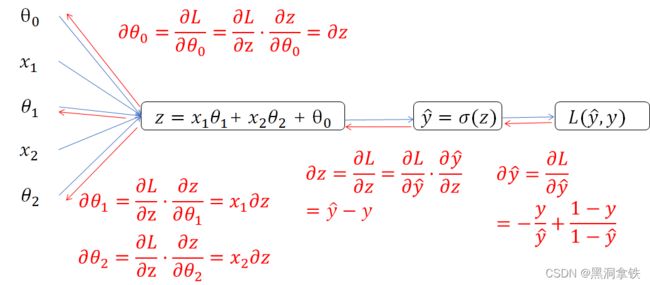
逻辑回归梯度下降算法
以上,我们详细介绍了在只有一个样本的情况下,如何通过计算图辅助我们理解偏导数 δ δ θ j J ( Θ ) \frac{\delta}{\delta \theta_j} J(\Theta) δθjδJ(Θ) 的计算过程。对于更一般的情况,即有 m m m 个样本的情况,偏导数的计算公式如下:
δ δ θ j J ( Θ ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x j ( i ) \frac{\delta}{\delta \theta_j} J(\Theta) = \frac{1}{m} \sum_{i=1}^{m}(h_\theta(x^{(i)}) - y^{(i)}) \cdot x^{(i)}_j δθjδJ(Θ)=m1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
逻辑回归梯度下降算法的形式如下(在每次迭代过程中,同时更新所有 θ j \theta_j θj,学习率为 α \alpha α):
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x j ( i ) \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m (h_\theta (x^{(i)}) - y^{(i)}) \cdot x^{(i)}_j\\ θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))⋅xj(i)
仔细观察一下,上式和线性回归梯度下降算法更新参数的表达式是类似的!只不过,在此式中 h θ ( x ) h_\theta(x) hθ(x) 的表达式变了 ,即 h θ ( x ( i ) ) = σ ( Θ T x ( i ) ) h_\theta(x^{(i)}) = \sigma(\Theta^T x^{(i)}) hθ(x(i))=σ(ΘTx(i))。
逻辑回归二分类实例
有了上述的知识储备,我们来具体看一下,如何通过逻辑回归训练一个学生录取概率的预测模型。
在开始执行任何算法之前,如果可能的话,一般的做法是先直观地了解一下数据的分布情况。在下图 4 中,横纵轴分别为科目一(Exam 1 score)、科目二的考试成绩(Exam 2 score),其中蓝色点代表被录取的学生,红色点代表未被录取的学生。逻辑回归要解决的就是找到一条分界线,区分上述两类样本。
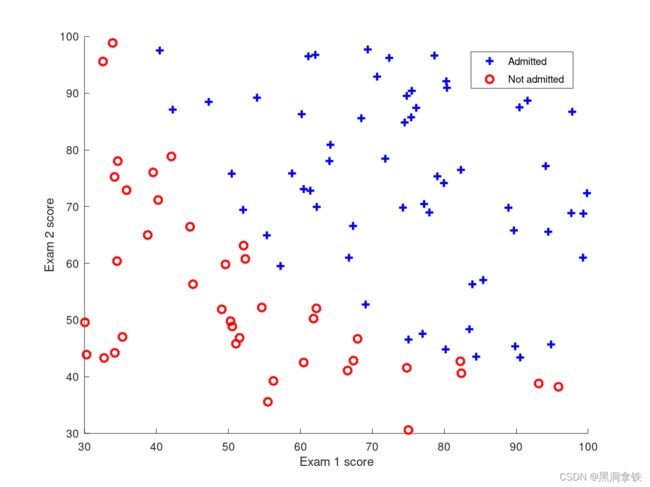
类似于线性回归,你采用逻辑回归算法构建了函数假设 h θ ( x ) h_\theta(x) hθ(x)、定义了损失函数 J ( Θ ) J(\Theta) J(Θ),并应用梯度下降算法寻找最小化 J ( Θ ) J(\Theta) J(Θ) 的参数组合 Θ \Theta Θ。算法最终优化得到的 Θ \Theta Θ 值组合为,{ θ 0 , θ 1 , θ 2 \theta_0, \theta_1, \theta_2 θ0,θ1,θ2} = {-25.161, -0.206, -0.201},即:
h θ ( x ) = σ ( − 25.161 − 0.206 E x a m _ 1 s c o r e − 0.201 E x a m _ 2 s c o r e ) h_\theta(x) = \sigma(-25.161 - 0.206 Exam\_1 score - 0.201 Exam\_2score) hθ(x)=σ(−25.161−0.206Exam_1score−0.201Exam_2score)
其中, − 25.161 − 0.206 E x a m _ 1 s c o r e − 0.201 E x a m _ 2 s c o r e = 0 -25.161 - 0.206 Exam\_1 score - 0.201 Exam\_2score = 0 −25.161−0.206Exam_1score−0.201Exam_2score=0 即为区分是否录取的决策边界,即为下图 5 中的黄色直线。

接下来,我们就可以使用训练好的模型来预测特定的学生是否会被录取。比如,某学生科目一、科目二考试成绩分别为 45 分和 85 分,计算得到其录取概率为 0.776,即 h ( 45 , 85 ) = σ ( − 25.161 − 0.206 × 45 − 0.201 × 85 ) = σ ( 1.194 ) ≈ 0.776 h({45,85}) = \sigma(-25.161 - 0.206\times45 - 0.201 \times 85) = \sigma(1.194) \approx 0.776 h(45,85)=σ(−25.161−0.206×45−0.201×85)=σ(1.194)≈0.776。
那么,以上得到的是一个理想的决策边界吗?从图中可以直观地看到,在这样的决策边界下,边界附近的一些点并没有被正确地分类。如果统计一下训练样本中被正确分类的样本所占的比例,可以得到我们构建的分类器的准确率为 89%,显然还有提升空间。
为什么我们构建的分类器效果不够理想呢?从上图 5 中可以看到,红蓝点之间的分界更近似于一条曲线,而我们构建的分类器是一个线性的分类器,其决策边界是一条直线(因为我们只使用了输入特征 x x x 的一次项)。为了得到一个非线性的决策边界,我们可以尝试:
1, 类似于在线性回归模型中介绍的方法,可以通过构建输入特征的多项式项来刻画非线性关系,比如加入 x 1 2 x_1^2 x12, x 1 x 2 x_1x_2 x1x2, x 2 \sqrt{x_2} x2 … 当然,具体加入哪些项,还需根据模型最终效果来决定。
2, 使用更复杂的模型,比如神经网络,关于构建非线性分类器的部分,我们将在后续的文章中介绍。
小结
在此篇文章中,我们主要介绍了以下三点内容:
1, 逻辑回归是一种分类算法,其基于现有数据对不同类别间的决策边界线建立回归公式,以此区分不同类别。
2, 相比于线性回归,逻辑回归通过 Sigmoid 函数将模型预测值映射至 0 和 1 之间,其输出表示样本属于某一类别的概率。
3, 同样可以通过梯度下降算法求得最优参数 Θ \Theta Θ 以最小化逻辑回归损失函数 J ( Θ ) J(\Theta) J(Θ),计算图可以帮助理解梯度的计算过程。
Logistic回归优点:
- 不仅能预测出“类别”,还可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用。
- 计算代价不高,易于理解和实现。
缺点:
- 拟合效果欠佳,分类精度可能不高。
参考资料
数据来自吴恩达机器学习课程 ↩︎
周志华. 机器学习[M]. 清华大学出版社, 2016. ↩︎
Harrington P. 机器学习实战[J]. 人民邮电出版社, 北京, 2013. ↩︎
吴恩达. Deep learning and neural network. ↩︎
复合函数求导链式法则. ↩︎
初等函数求导法则. ↩︎