机器学习入门
机器学习入门
1基本概念
机器学习是什么
让计算机从数据中进行自动学习,得到某种知识或规律。
将其转换为决策模型,然后将其用于未来的预测
数据集
指一组样本构成的集合。一般将数据集分为两部分:训练集和测试集。
训练集中的样本是用来训练模型,而测试集中的样本是用来检验模型好坏。
学习与训练
不断找到最优模型(最优的从输入x映射到输出y的关系)
2算法的类型
2.1有监督学习
概念
如果机器学习的目标是建模样本的特征 和标签 之间的关系,并且训练集中每个样本都有标签,那么这类机器学习称为监督学习。(无监督学习则没有标签)
根据标签类型的不同,监督学习又可以分为回归问题、分类问题、结构化学习。
回归问题
利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模。
回归问题的输出是连续值。比如未来几年预测房屋价格的走势,价格是一个连续的值。
(回归问题通常有一元线性回归和多元线性回归,通常用最小二乘法解决)
分类问题
分类问题的输出是离散值。分类问题根据其类别数量又可分为二分类多分类问题。
如猫狗识别例子就是一个二分类的问题,因为它输出的结果不是猫就是狗。
典型分类算法–KNN(k近邻算法)
核心思想:根据你的“邻居”来推断出你的类别
原理:当预测一个新的值x的时候,选择它距离最近的k个点,这k个点中属于哪个类别的点最多,x就属于哪个类别
结构化学习
2.2无监督学习
概念
无监督学习是指从不包含目标标签的训练样本中自动学习到一些有价值的信息。
典型的无监督学习问题有聚类、 密度估计、特征学习、降维等。其中聚类和降维比较常用。
聚类
聚类就是按照某个特定标准把一个数据集分割成不同的类或簇。
最经典的就是k-means算法聚类。
k-means算法聚类
流程
1.随机地选择k个点,每个点代表一个簇的中心;
2.将其他所有对象根据其与各簇中心的距离,将它赋给最近的簇;
3.重新计算每个簇的平均值,更新为新的簇中心;不断重复2、3,直到准则函数收敛。
降维
在减少数据集中特征数量的同时,避免丢失太多信息并保持/改进模型性能。
其中最常用的一种算法就是PCA, 也称主成分分析法。
2.3强化学习
3损失函数
概念
损失函数是一种衡量模型与数据吻合程度的算法,测量实际测量值和预测值之间差距。
损失函数的值越高预测就越错误,损失函数值越低则预测越接近真实值。
损失函数是一个非负实数函数。不同的损失函数适合运用于不同的模型中。
01损失函数
最直观的损失函数:表现模型在训练集上的错误率
当预测值和真实值相等时,结果为0,否则为1
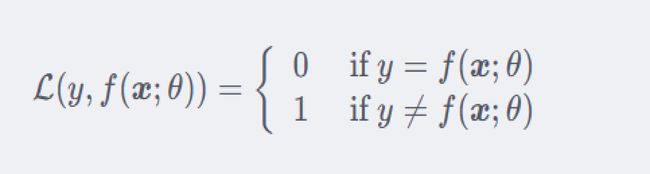
直观显示错误,但是无法展示误差多少,因为只要误差就是1
平方损失函数
常用在预测标签为实数值的任务中,一般不适用于分类问题。

指预测值与实际值差的平方
能够使用梯度下降法优化
平方:当预测值距离真实值越远时,平方损失函数的惩罚力度越大,因此对异常值更敏感
交叉熵损失函数
对于两个概率分布,一般可以用交叉熵来衡量它们的差异
在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
几乎每次都和sigmoid(或softmax)函数一起出现
4欠拟合和过拟合
概念
欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。(模型过于简单)
过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。(模型过于复杂)
合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
原因及方法
1.欠拟合原因以及解决办法
原因:学习到数据的特征过少
解决办法:增加数据的特征数量
2.过拟合原因以及解决办法
原因:原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决办法:正则化
5算法优化方法
梯度下降法
在机器学习中,最简单、常用的优化算法就是梯度下降法,我们可以不断往负梯度的方向搜索(也就是导数或者偏导数的相反方向),直到达到最低点。
梯度下降可以理解为:你想要下山,此时最快的下山方式就是找到四周最陡峭的地方,沿这个方向下山,一直执行这个策略,在第N个循环后,就到达山的最低处。

损失函数的迭代公式为
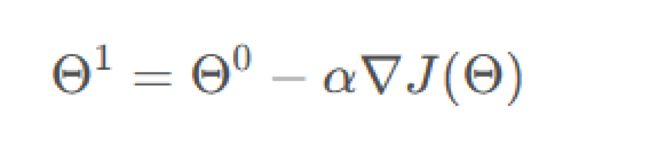
为搜索步长.在机器学习中,一般称为学习率。
学习率的大小是很有讲究的,如果学习率太小,要很慢才能到达最低点;学习率太大,很容易错过最低点。
通常这个学习率是不断调整的,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回振荡。