【CVPR2020】Meshed-Memory Transformer for Image Captioning
【CVPR2020】Meshed-Memory Transformer for Image Captioning
附: 论文下载地址
论文主要贡献
- 图像区域及其关系以多层次方式进行编码,其中考虑了低层次和高层次关系。当对这些关系建模时,该模型可以通过使用持久记忆向量来学习和编码先验知识。
- 句子的生成采用多层次结构,利用低层次和高层次的视觉关系,而不是只有视觉模态的单一输入。这是通过学习的门控机制实现的,该机制对每个阶段的多级贡献进行加权。
引言
图像描述是用自然语言描述图像的视觉内容的任务。因此,它需要一种算法来理解和建模视觉元素和文本元素之间的关系,并生成一个输出单词序列。这通常是通过循环神经网络模型来解决的,其中语言的顺序本质是用rnn或lstm的循环关系来建模的,为了建立图像区域、单词和最终标签之间的关系模型,常常在递归中加入附加注意力或图形样结构。
在最近出现的fully attentive models中循环关系被抛弃,而使用self-attention,在集合和序列建模性能方面提供了独特的机会,此外,此设置还提供了新颖的架构建模功能,因为注意力操作符首次以多层和可扩展的方式使用。然而,图像描述的多模态本质要求特定的架构,不同于那些用于理解单一模态的架构。
虽然基于Transformer的体系结构代表了序列建模任务(如机器翻译和语言理解)的最新水平。然而,它们对图像描述等多模态上下文的适用性仍然有待探索。作者提出了 M 2 M^2 M2 ,一个用于图像描述的带存储器的网状Transformer。该体系结构改进了图像编码和语言生成步骤:它结合学习到的先验知识学习图像区域之间关系的多层次表示,并在解码阶段使用网状连接来挖掘低级和高级特征。

论文方法( M 2 M^2 M2 Transformer)
整个模型分为编码器和解码器模块,编码器负责处理输入图像的区域并设计它们之间的关系,解码器从每个编码层的输出中逐字读取并输出描述。文字和图像级特征之间的模态内和跨模态的交互都是通过缩放点积注意力来建模的,而不使用递归。注意力操作基于三个向量:Q,K,V。根据Q和K向量之间的相似度分布,计算V向量的加权和,表示如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V Attention(Q,K,V)=softmax(\frac {QK^T} {\sqrt{d}})V Attention(Q,K,V)=softmax(dQKT)V其中Q,K,V都是由向量组成的矩阵,具有相同的维度。
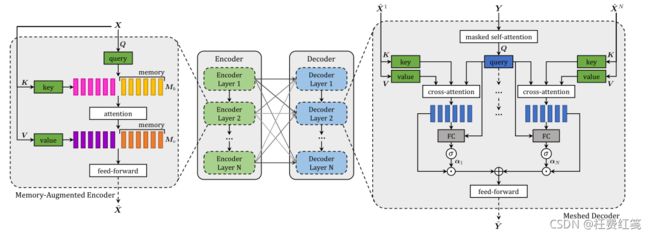
记忆增强编码器(Memory-Augmented Encoder)
给定从输入图像中提取的一组图像区域X,可通过transformer中使用的self-attention operato获得X的置换不变编码。在这种情况下,Q,K,V通过线性投影输入特征获得的,基本运算可以定义为: S ( X ) = A t t e n t i o n ( W q X , W k X , W v X ) S(X)=Attention(W_qX,W_kX,W_vX) S(X)=Attention(WqX,WkX,WvX)其中 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv是可学习权重矩阵,输出的是一组新的元素S(X),与X有相同的基数,X中的每个元素都替换为值的加权和。
值得注意的是,注意力权重仅取决于输入集本身的线性投影之间的成对相似性,因此,self-attention operator可以被看作是一种用于编码输入集当中成对关系的方法。当使用图像区域(或图像区域衍生的特征)作为输入集时,S(·)可以自然地对理解输入图像所需要的区域之间的成对关系进行编码,然后再进行描述。
然而,self-attention有一个重大的局限性,因为一切都仅仅依赖于成对的相似性,self-attention不能对图像区域之间的关系建立先验知识模型。例如,给定一个编码人和一个编码篮球的区域,在没有任何先验知识的情况下,很难推断出球员或打球的概念。同样,给定编码鸡蛋和烤面包的区域,可以很容易地利用关系的先验知识推断出图片描述的是早餐。
记忆增强注意力层(Memory-Augmented Attention)
为了克服self-attention的局限性,作者提出了一个记忆增强注意力,将用于自我注意的K和V的集合被扩展为可以编码先验信息的额外的“槽”。为了强调先验信息不应依赖于输入输入集,K和V定义为简单的可学习向量,可以直接通过SGD更新。形式上定义为:
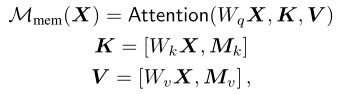 其中 M k , M v M_k,M_v Mk,Mv是 n m n_m nm行的可学习矩阵,添加可学习的K和V可以通过注意力检索到X中尚未嵌入的已学习的知识,同时并没有改变查询集。
其中 M k , M v M_k,M_v Mk,Mv是 n m n_m nm行的可学习矩阵,添加可学习的K和V可以通过注意力检索到X中尚未嵌入的已学习的知识,同时并没有改变查询集。
像self-attention一样,记忆增强注意力也可以以多头方式运用。在这种情况下,记忆增强注意操作是反复的,可以为每个头使用不同的投影矩阵 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv 和不同的可学习记忆槽 M k , M v M_k,M_v Mk,Mv,然后,我们将不同头的结果连接起来,并应用线性投影。
残差连接和规范层(residual connection and layer norm )
作者将记忆增强嵌入到一个类似transformer的层中,记忆增强注意力的输出被应用到由两个具有单一非线性的仿射变换组成的位置前馈层中,这两个仿射变换独立地应用于集合的每个元素,可表示为:
F ( X ) i = U σ ( V X i + b ) + c F(X)_i=U\sigma(VX_i+b)+c F(X)i=Uσ(VXi+b)+c其中 X i X_i Xi表示输入集的第i个向量, F ( X ) i F(X)_i F(X)i表示输出集的第i个向量, σ ( ⋅ ) \sigma(·) σ(⋅)是ReLU激活函数, V V V和 U U U是可学习的权重矩阵, b b b和 c c c是偏置项。
每一个子组件(记忆增强注意力和位置前馈层)被封装在残差连接和layer norm层中,所以编码层完整定义表示为: Z = A d d N o r m ( M m e n ( X ) ) Z=AddNorm(M_{men}(X)) Z=AddNorm(Mmen(X)) X ~ = A d d N o r m ( F ( Z ) ) \tilde{X}=AddNorm(F(Z)) X~=AddNorm(F(Z)) A d d N o r m AddNorm AddNorm表示残差连接和layer norm层。
给定上述结构,多个编码层依次叠加,第i层使用第i-1层的输出作为输入,这相当于创建了图像区域之间关系的多级编码,在这些编码层中,更高级的编码层可以利用和细化已经被前面的层识别出来的关系,最终利用先验知识。因此,N个编码层的栈的将产生一个多级输出 X ~ = ( X ~ 1 , . . . X ~ N ) \tilde{X}=(\tilde{X}^1,...\tilde{X}^N) X~=(X~1,...X~N),从每个编码层的输出获得。
网状解码器(Meshed Decoder)
解码器以前面生成的单词和区域编码为条件,并负责生成输出描述的下一个token。作者设计了一个网格注意算子,不同于Transformer的交叉注意算子,它可以利用句子生成过程中的所有编码层,利用上述输入图像的多层表示,构建多层结构。
网状交叉注意(Meshed Cross-Attention)
给定输入序列向量 Y Y Y,和所有编码层 X ~ \tilde{X} X~的输出,Meshed Attention operator通过门控交叉注意将Y连接到属于X的所有元素,并不是只关注最后一个编码层,而是对所有编码层进行交叉关注,这些多层次的贡献经过调整后整合在一起。定义如下:
M m e s h ( X ~ , Y ) = ∑ i = 1 N α i ⊙ C ( X ~ i , Y ) M_{mesh}(\tilde{X},Y)=\sum_{i=1}^{N} {\alpha_i \odot C(\tilde{X}^i,Y)} Mmesh(X~,Y)=i=1∑Nαi⊙C(X~i,Y)其中 C ( ⋅ ) C(·) C(⋅)表示编码器和解码器的交叉注意,计算如下:
C ( X ~ i , Y ) = A t t e n t i o n ( W q Y , W k X ~ i , W v X ~ i ) C(\tilde{X}^i,Y)=Attention(W_qY,W_k\tilde{X}^i,W_v\tilde{X}^i) C(X~i,Y)=Attention(WqY,WkX~i,WvX~i) α i \alpha_i αi 是一个权重矩阵,其大小与交叉注意结果相同。 α i \alpha_i αi的权值调节各编码层的单一贡献,以及不同编码层之间的相对重要性。通过测量每个编码层的交叉注意结果与输入查询之间的相关性来计算这些数据,如下所示:
α i = σ ( W i [ Y , C ( X ~ i , Y ) ] + b i ) \alpha_i=\sigma(W_i[Y,C(\tilde{X}^i,Y)]+b_i) αi=σ(Wi[Y,C(X~i,Y)]+bi)其中 [ ⋅ , ⋅ ] [\cdot,\cdot] [⋅,⋅]表示连接, σ \sigma σ是sigmoid激活函数, W i W_i Wi是一个 2 d × d 2d\times d 2d×d的权重矩阵, b i b_i bi是可学习的偏置向量。
解码层结构(Architecture of decoding layers)
解码层同样使用多头的方式应用网状注意力。由于一个单词的预测应该只依赖于之前预测的单词,解码器层包括masked selfattention operation,derived,它将从输入序列 Y Y Y的第 t t t个元素派生的查询与从左子序列(即 Y≤ t)获得的键和值连接起来,解码器层包含一个位置前馈层 ,所有组件都封装 A d d N o r m AddNorm AddNorm中。解码器层的最终结构可以写成:
Z = A d d N o r m ( M m e s h ( X ~ , A d d N o r m ( S m a s k ( Y ) ) ) ) Z=AddNorm(M_{mesh}(\tilde{X},AddNorm(S_{mask}(Y)))) Z=AddNorm(Mmesh(X~,AddNorm(Smask(Y)))) Y ~ = A d d N o r m ( F ( Z ) ) \tilde{Y}=AddNorm(F(Z)) Y~=AddNorm(F(Z))其中 Y Y Y是输入序列的向量, S m a s k S_{mask} Smask表示随时间变化的 masked self-attention。最后多个解码器层堆叠在一起,有助于改善对文本输入的理解和下一个token的生成。
训练细节(Training details)
作者使用单词级交叉熵损失(XE)对模型进行预训练,并使用强化学习对序列生成进行精细调整。用XE进行预训练是遵循学习速率调度策略,预热相当于10000次迭代。当使用XE进行训练时,该模型被训练为预测给定前ground-truth单词的下一个token;在这种情况下,解码器的输入序列是立即可用的,整个输出序列的计算可以一次性中完成,随着时间的推移并行化所有操作。
在使用强化学习进行训练时,作者将自临界序列训练方法的一种变体应用于用beam search(波束搜索)采样的序列进行解码,在每个时间步从解码器的概率分布中采样top-k的单词,并始终保持具有最高概率的top-k序列。由于在此步骤中序列解码是迭代的,因此不能利用上述随时间变化的并行性。但是,用于在时间步t计算输出token的中间键和值可以在下一个迭代中重用。
之后,作者使用CIDEr-D分数作为奖励,因为它与人类的判断[很好地相关,使用奖励的平均值作为奖励的基线,作者发现它可以略微提高最终的表现。最终梯度表达式为: ∇ θ L ( θ ) = − 1 k ∑ i = i k ( ( r ( ω i ) − b ) ∇ θ l o g p ( ω i ) ) \nabla_{\theta}L(\theta)=-\frac{1}{k}\sum_{i=i}^{k} {((r(\omega^i)-b)\nabla_{\theta}logp(\omega^i))} ∇θL(θ)=−k1i=i∑k((r(ωi)−b)∇θlogp(ωi))其中 w i w^i wi是beam中的第 i i i个句子,r(·)是奖励函数, b = ( ∑ i r ( w i ) ) / k b=(\sum_{i} {r(w^i)})/k b=(∑ir(wi))/k是baseline。在预测时刻,采用beam search重新解码,保留最后一个beam中预测概率最高的序列。
实验(Experiments)
数据集(Datesets)
作者先在COCO数据集上评估该模型,这是最常用的图像描述测试平台。然后又在最近提出的nocaps数据集上测试来评估新对象的描述。
实验设置(Experimental settings)
评价指标(Metrics)
按照标准评估协议,作者采用全套描述指标:BLEU、METEOR、ROUGE、CIDEr和SPICE。
实现细节(Implementation details)
作者使用Faster R-CNN和在Visual Genome数据集上经过微调的ResNet-101获得每个区域的2048维特征向量,使用one-hot向量表示单词,并将它们线性投影到模型的输入维度上,还使用正弦位置编码来表示序列内的字的位置,并在第一个解码层之前对两个嵌入进行求和。
在模型中,设置每一层的维度为512,头的数目设为8,内存向量的数目设为40。在每个注意和前馈层之后,使用概率为0.9的dropout。然后,在CIDEr-D优化过程中,使用固定的学习率5×10−6,使用Adam优化器训练所有模型, batch size为50, beam size为5。
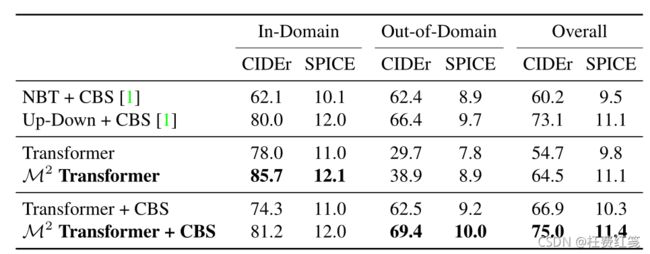
新对象描述(Novel object captioning)
为了在nocaps数据集上训练该模型,作者使用GloVe单词嵌入来表示单词,而不是使用one-hot向量向量,加入两个全连接层,在第一解码层之前和最后解码层之后进行GloVe维数转换。在最后的softmax之前,我们乘以单词embeddings的转置。所有其他实现细节保持不变。
消融实验(Ablation study)
Transformer性能(Performance of the Transformer)
在实验工程中作者发现,3层的Transformer结构要比6层的结构效果Transformer要好,作者假设这是由于减少了训练集的大小和描述中句子相对于语言理解任务的语义复杂性较低。
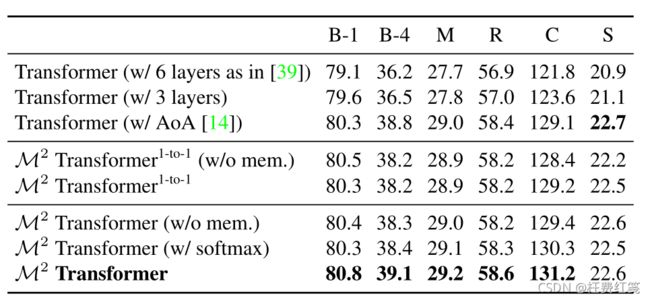
AoA基线(Attention on Attention baseline)
作者实现了将Attention on Attention(AOA)添加到编码器和解码器的注意力层,在这种情况下,点积注意的结果与初始查询连接起来,并提供给两个全连接层,以获得一个信息向量和一个sigmoidal注意门,然后将这两个向量相乘,最终的结果被用来替代标准的点积注意,获得效果提升,如上图所示。
网状连接(Meshed Connectivity)
作者先实验了1-1的连接,即编码器只和对应的解码器连接,效果已有提升,因此证实了利用图像区域的多级编码是有益的。
与最新技术比较(Comparison with state of the art)
单模型(Single model)

集成模型(Ensemble model)

在线评估(Online Evaluation)

新对象的描述(Describing novel objects)
定性结果和可视化(Qualitative results and visualization)


总结(Conclusion)
作者提出了 M 2 M^2 M2 Transformer,一种新的基于transformer的图像描述架构。该模型模型结合了区域编码方法,通过记忆向量利用先验知识和编码和解码模块之间的网状连接。值得注意的是,这种连接模式在其他全关注的架构中是前所未有的。
部分实验细节作者在附录有提到,不明白的地方或者感兴趣的可以观看原文