利用CNN进行面部表情识别
本文是论文《Facial Emotion Recognition: State of the Art Performance on FER2013》的复现,感谢原作者Yousif Khaireddin和Zhuofa Chen。
本文采用的数据集是FER2013。
文章目录
- 前言
- 系统设计
-
- 数据预处理
-
- 数据集分割
- 数据增强
- VGGNet 网络结构
- 神经网络的优化方法
-
- 基于Nesterov momentum的SGD方法
- 学习速率监测器
- 系统实现
-
- 实验环境
-
- 本地环境
- 使用GPU训练
- 数据集概览
- 样本概览
- 数据预处理
- 构建我们的神经网络
- 数据增强
- 系统测试
-
- 训练我们的神经网络
- 可视化训练效果
- 评估测试效果
- 使用混淆矩阵进行分析
- 实时人脸表情识别
- 系统总结
前言
面部情绪识别是指识别传达恐惧、快乐和厌恶等基本情绪的表情。它在人机交互中起着重要作用,可应用于数字广告、在线游戏、客户反馈评估和医疗保健等方面。随着计算机视觉技术的进步,在受控条件和一致环境下拍摄的图像中能够实现较高的表情识别准确率,从而使这一技术得到运用。在自然条件下,由于类内变异较大和类间变异较小,例如面部姿势的变化和表情之间的细微差异,表情识别技术面临挑战。
计算机视觉技术的发展一直致力于提高此类问题的分类精度。在图像分类中,卷积神经网络(CNN)由于其计算效率和特征提取能力而显示出巨大的潜力。它们是FER最广泛使用的深度模型。一个包含复杂自然环境条件的具有挑战性的典型数据集是FER2013。它在2013年的国际机器学习会议(ICML)上被引入,并成为比较情感识别模型性能的基准。该数据集的绩效因子估计为65.5%。基于此,我们使用FER2013数据集作为我们的研究对象。
在本次项目实践中,我们的目标是利用CNN训练FER2013数据集,并实现实时的表情识别系统。
系统设计
数据预处理
数据集分割
为了训练FER2013数据集,我们参照ICML官方设计的训练(Training)、验证(Validation)、测试(Test)数据集的分割方法,即80%作为训练数据集,10%作为验证数据集,10%作为测试数据集。
数据增强
为了能让我们的卷积神经网络对表情识别有更加可靠的自适应性,我们可以在神经网络的训练中使用数据增强(Data Augmentation)。基于批量(Batch)数据的实时训练方式,我们的数据增强方法如下表所示。
| 处理方式 | 参数设置 | 效果 | |
|---|---|---|---|
| 1 | Zoom | ±20% | 对图像做随机缩放 |
| 2 | Width/Height Shift | ±20% | 水平/垂直平移 |
| 3 | Rotation | ±10% | 随机旋转角度 |
| 4 | Horizontal Flip | 水平镜像 |
VGGNet 网络结构
VGGNet是一种用于大规模图像处理和模式识别的经典卷积神经网络结构。我们的搭建的VGGNet变体如下图所示。

该网络由4个卷积级(Convolutional Stages)和3个全连接层(Fully Connected Layers)组成。每个卷积级包含两个卷积块(Convolutional Blocks)和一个最大池化层(Max Pooling)。卷积块由卷积层(Convolution)、ReLU激活函数和批标准化层(Batch Normalization)组成。批标准化能够加速神经网络的学习过程,减少内部协方差偏移,以及防止梯度消失或爆炸。前两个全连接层之后是ReLU激活函数。第三个全连接层用于最终分类,使用SoftMax激活函数。卷积级的作用是特征提取、降维和非线性。经过全连接层的训练,我们可以根据提取的特征对输入图像进行分类。
神经网络的优化方法
基于Nesterov momentum的SGD方法
我们回顾基本的mini-bacth SGD方法,其原理是,采用训练数据的一部分,生成批量样本(mini-batch),然后对批量样本,使用随机梯度下降法(SGD)更新权值(weights)和偏置(biases),如下面的公式所示。
{ w j k l ← w j k l + Δ w j k l = w j k l − η m ∑ ∇ w j l b j l ← b j l + Δ b j l = b j l − η m ∑ ∇ b j l \left\{ \begin{array}{l} w_{jk}^l\gets\ w_{jk}^l+\Delta w_{jk}^l=w_{jk}^l-\frac{\eta}{m}\sum{\nabla w^l_j}\\ b_j^l\gets\ b_j^l+\Delta b_j^l=b_j^l-\frac{\eta}{m}\sum{\nabla b^l_j} \end{array} \right. {wjkl← wjkl+Δwjkl=wjkl−mη∑∇wjlbjl← bjl+Δbjl=bjl−mη∑∇bjl
其中, η \eta η 就是学习速率,m是mini-batch的样本数量。
mini-bacth SGD的核心是对权值梯度 ∇ w \nabla w ∇w和偏置的梯度 ∇ b \nabla b ∇b,经过反向传播的方式进行更新。因此,我们也把基于SGD方法的神经网络称为BP神经网络。
进一步,我们使用动量(momentum)方法更好地完成对权值的更新。当使用SGD训练参数时,有时候会下降的非常慢,并且可能会陷入到局部最小值中。momentum的引入就是为了加快学习过程,特别是对于高曲率、小但一致的梯度,或者噪声比较大的梯度能够很好的加快学习过程。
我们引入速度变量 v = v 1 , v 2 , ⋯ v=v_1,v_2,\cdots v=v1,v2,⋯,其中每一个对应 w j w_j wj变量。然后我们将上述公式中关于权值的梯度下降更新规则 w ← w ′ = w − η ∇ C w\gets w^\prime = w-\eta \nabla C w←w′=w−η∇C改成如下的公式。
{ v ← v ′ = μ v − η ∇ C w ← w ′ = w + v ′ \left\{ \begin{array}{l} v\gets v^\prime = \mu v-\eta \nabla C\\ w\gets w^\prime = w + v^\prime \end{array} \right. {v←v′=μv−η∇Cw←w′=w+v′
其中, μ \mu μ是一个超参数,其值越大,则之前的梯度对现在的方向影响越大。
最后,Nesterov momentum是对momentum的改进,可以理解为Nesterov动量在标准动量方法中添加了一个校正因子。与momentum的唯一区别就是计算梯度的不同,Nesterov先用当前的速度v更新一遍参数,再用更新的临时参数计算梯度。即上述公式中的梯度计算先使用如下的公式。
{ g ^ ← + 1 m ∇ θ ∑ i L ( f ( x i ; θ + α v ) ) v ← v ′ = μ v − η g ^ w ← w ′ = w + v ′ \left\{ \begin{array}{l} \hat{g} \gets + \frac{1}{m}\nabla_\theta \sum_i{L(f(x_i;\theta+\alpha v))}\\ v\gets v^\prime = \mu v - \eta \hat{g}\\ w\gets w^\prime = w + v^\prime \end{array} \right. ⎩⎨⎧g^←+m1∇θ∑iL(f(xi;θ+αv))v←v′=μv−ηg^w←w′=w+v′
学习速率监测器
学习速率通常会影响神经网络的训练的效果,当评价指标不再提升时,我们应该降低学习速率,因为此时,较慢的学习速率能找到更精准的网络。
我们使用Reduce Learning Rate on Plateau(RLRP)策略:当评估标准停止提升时,降低一定的学习速率。当学习停止时,模型总是会受益于降低 2-10 倍的学习速率。我们检测某个数据并且当这个数据在一定“有耐心”的训练轮之后还没有进步,那么学习速率就会被降低。
系统实现
实验环境
本地环境
对于网络的构建,我们使用本地环境先行验证。本地环境的版本参数如下表所示。
| 版本 | |
|---|---|
| Python | 3.7.2 |
| Tensorflow | 2.6.2 |
| Keras | 2.6.0 |
| OpenCV | 3.4.2 |
使用GPU训练
我们使用Kaggle提供的在线环境训练我们的神经网络,配置有GPU模块。
然后将训练完的模型,再适配至本地环境,进行真实的人脸表情识别预测。
数据集概览
FER2013数据集共有35887个样本,如下面的输出所示。
data = pd.read_csv('../input/fer2013/fer2013.csv')
# 查看数据集形状
data.shape
Output: (35887, 3)
我们使用的FER2013数据集,以CSV格式呈现,如下图所示。

其中,第0列是表情对应的数字类别,从0~1分别对应着表情:Angry(生气)、Disgust(厌恶)、Fear(害怕)、Happy(高兴)、Sad(生气)、Surprise(惊讶)、Neutral(中立)。
第二列是图像的像素数据,以行向量的形式呈现,使用空格分隔。像素值介于 [ 0 , 255 ] [0,255] [0,255]之间。
第三列是该样本的用途,有Training、PublicTest、PrivateTest。从输出结果可知,训练数据有80%的占比,测试数据和验证数据各占10%。
#查看数据集的分类情况
#80% 训练, 10% 验证 and 10% 测试
data.Usage.value_counts()
Training 28709
PublicTest 3589
PrivateTest 3589
Name: Usage, dtype: int64
样本概览
查看表情分类数据,如下图所示。
#查看表情分类数据
emotion_map = {0: 'Angry', 1: 'Disgust', 2: 'Fear', 3: 'Happy', 4: 'Sad', 5: 'Surprise', 6: 'Neutral'}
emotion_counts = data['emotion'].value_counts().sort_index().reset_index()
emotion_counts.columns = ['emotion', 'number']
emotion_counts['emotion'] = emotion_counts['emotion'].map(emotion_map)
emotion_counts
# %%
# 绘制类别分布条形图
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
plt.figure(figsize=(6, 4))
sns.barplot(x=emotion_counts.emotion, y=emotion_counts.number)
plt.title('Class distribution')
plt.ylabel('Number', fontsize=12)
plt.xlabel('Emotions', fontsize=12)
plt.show()


从上面的图我们可以知道,Disgust类的样本数量比较少,这是一个分布不太均匀的数据集。

上图所示的是一些样本的示例图片,其生成代码如下:
def row2image_label(row):
pixels, emotion = row['pixels'], emotion_map[row['emotion']]
img = np.array(pixels.split())
img = img.reshape(48, 48)
image = np.zeros((48, 48, 3))
image[:, :, 0] = img
image[:, :, 1] = img
image[:, :, 2] = img
return image.astype(np.uint8), emotion
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
plt.figure(0, figsize=(16, 10))
for i in range(1, 8):
face = data[data['emotion'] == i - 1].iloc[0]
img, label = row2image_label(face)
plt.subplot(2, 4, i)
plt.imshow(img)
plt.title(label)
plt.show()
数据预处理
数据预处理部分,主要完成了下面四个事情:
- 分割数据为3个部分: train, validation, test
- 将数据标签由字符串改为整数
- 调整图片大小为 48x48, 归一化图像
- 更改标签编码为one-hot, 例如类别3(Happy)对应为 [ 0 , 0 , 0 , 1 , 0 , 0 , 0 ] [0,0,0,1,0,0,0] [0,0,0,1,0,0,0]
#分割数据为: train, validation, test
data_train = data[data['Usage'] == 'Training'].copy()
data_val = data[data['Usage'] == 'PublicTest'].copy()
data_test = data[data['Usage'] == 'PrivateTest'].copy()
print(f"train shape: {data_train.shape}")
print(f"validation shape: {data_val.shape}")
print(f"test shape: {data_test.shape}")
# %%
# 绘制train, val, test的条形图
emotion_labels = ['Angry', 'Disgust', 'Fear', 'Happy', 'Sad', 'Surprise', 'Neutral']
def setup_axe(axe, df, title):
df['emotion'].value_counts().sort_index().plot(ax=axe, kind='bar', rot=0,
color=['r', 'g', 'b', 'r', 'g', 'b', 'r'])
axe.set_xticklabels(emotion_labels)
axe.set_xlabel("Emotions")
axe.set_ylabel("Number")
axe.set_title(title)
# 使用上述列表设置单个条形标签
for i in axe.patches:
# get_x pulls left or right; get_height pushes up or down
axe.text(i.get_x() - .05, i.get_height() + 120,
str(round((i.get_height()), 2)), fontsize=14, color='dimgrey',
rotation=0)
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
fig, axes = plt.subplots(1, 3, figsize=(20, 8), sharey='all')
setup_axe(axes[0], data_train, 'Train')
setup_axe(axes[1], data_val, 'Validation')
setup_axe(axes[2], data_test, 'Test')
plt.show()
经过处理后的各个子数据集的样本分布情况如下图所示。
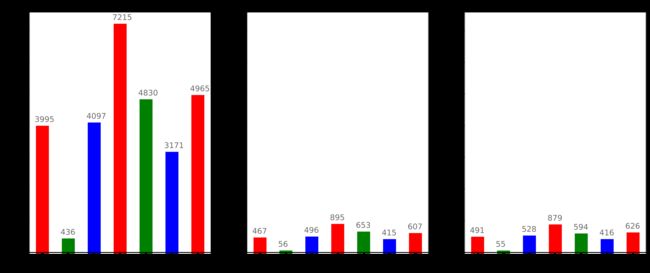
def CRNO(df, dataName):
df['pixels'] = df['pixels'].apply(lambda pixel_sequence: [int(pixel) for pixel in pixel_sequence.split()])
data_X = np.array(df['pixels'].tolist(), dtype='float32').reshape(-1, width, height, 1) / 255.0
data_Y = to_categorical(df['emotion'], num_classes)
print(dataName, f"_X shape: {data_X.shape}, ", dataName, f"_Y shape: {data_Y.shape}")
return data_X, data_Y
train_X, train_Y = CRNO(data_train, "train") #training data
val_X, val_Y = CRNO(data_val, "val") #validation data
test_X, test_Y = CRNO(data_test, "test") #test data
各子数据集的输入和预期输出的形状如下:
train _X shape: (28709, 48, 48, 1), train _Y shape: (28709, 7)
val _X shape: (3589, 48, 48, 1), val _Y shape: (3589, 7)
test _X shape: (3589, 48, 48, 1), test _Y shape: (3589, 7)
构建我们的神经网络
我们的神经网络的整体结构已在前文中给出, 每个层的具体参数如下表所示。

具体代码如下所示,注意到代码中已经设置了SGD的具体优化参数。
# ## 构建我们的CNN
#
# ### CNN 结构:
# Conv Sages 1 --> Conv Stages 2 --> Conv Stages 3 --> Conv Stages 4 --> Flatten --> Full Connection --> Softmax Output Layer
#
# ### Conv Stages
# Conv Block --> Max Pooling
#
# ### Conv Block
# Conv --> BN --> ReLU
# %%
model = Sequential()
# ---------- Convolutional Stages 1 ----------
# ***** Conv Block a *****
model.add(Conv2D(64, kernel_size=(3, 3), input_shape=(width, height, 1),
data_format='channels_last', padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# ***** Conv Block b *****
model.add(Conv2D(64, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# max pooling
model.add(MaxPooling2D(pool_size=(2, 2)))
# ---------- Convolutional Stages 2 ----------
# ***** Conv Block a *****
model.add(Conv2D(128, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# ***** Conv Block b *****
model.add(Conv2D(128, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# max pooling
model.add(MaxPooling2D(pool_size=(2, 2)))
# ---------- Convolutional Stages 3 ----------
# ***** Conv Block a *****
model.add(Conv2D(256, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# ***** Conv Block b *****
model.add(Conv2D(256, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# max pooling
model.add(MaxPooling2D(pool_size=(2, 2)))
# ---------- Convolutional Stages 4 ----------
# ***** Conv Block a *****
model.add(Conv2D(512, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# ***** Conv Block b *****
model.add(Conv2D(512, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# max pooling
model.add(MaxPooling2D(pool_size=(2, 2)))
# Flatten
model.add(Flatten())
# Full connection
model.add(Dense(4096, activation='relu', kernel_regularizer=l2()))
model.add(Dropout(rate_drop))
model.add(Dense(4096, activation='relu', kernel_regularizer=l2()))
model.add(Dropout(rate_drop))
#output layer
model.add(Dense(num_classes, activation='softmax', kernel_regularizer=l2()))
model.compile(loss=['categorical_crossentropy'],
optimizer=SGD(momentum=0.9, nesterov=True ,decay=1e-4),
metrics=['accuracy'])
model.summary()
数据增强
根据前文,使用Keras框架自带的ImageDataGenerator方法,编写如下代码。
# 数据增强
data_generator = ImageDataGenerator(
zoom_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
rotation_range=10,
featurewise_std_normalization=False,
horizontal_flip=True)
系统测试
训练我们的神经网络
设置训练参数如下:
#初始化参数
num_classes = 7
width, height = 48, 48
num_epochs = 300
batch_size = 128
num_features = 64
rate_drop = 0.1
进行训练:
es = EarlyStopping(monitor='val_loss', patience=10, mode='min', restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_accuracy', factor=0.75, patience=5, verbose=1)
history = model.fit(data_generator.flow(train_X, train_Y, batch_size),
# steps_per_epoch=len(train_X) / batch_size,
batch_size=batch_size,
epochs=num_epochs,
verbose=2,
callbacks=[es, reduce_lr],
validation_data=(val_X, val_Y))
注意到,在上述代码中,使用了两个策略监测我们的网络:
- 过拟合监测,如果没有更小的验证损失,则网络停止训练
- 学习速率监测,如果没有更好的验证精度,则降低学习速率
部分训练输出信息如下:
2021-12-26 05:35:09.313687: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/300
2021-12-26 05:35:10.991111: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8005
225/225 - 20s - loss: 2.0907 - accuracy: 0.2503 - val_loss: 1.9219 - val_accuracy: 0.2494
Epoch 2/300
225/225 - 12s - loss: 1.8205 - accuracy: 0.2714 - val_loss: 1.8866 - val_accuracy: 0.2611
Epoch 3/300
225/225 - 12s - loss: 1.6999 - accuracy: 0.3240 - val_loss: 1.8933 - val_accuracy: 0.3090
……
Epoch 00020: ReduceLROnPlateau reducing learning rate to 0.007499999832361937.
……
Epoch 00037: ReduceLROnPlateau reducing learning rate to 0.005624999874271452.
……
Epoch 00048: ReduceLROnPlateau reducing learning rate to 0.004218749818392098.
Epoch 49/300
225/225 - 13s - loss: 0.7174 - accuracy: 0.7382 - val_loss: 1.0229 - val_accuracy: 0.6559
我们观察到,训练过程中存在3次学习速率调整,最终在第49次迭代时提前终止训练。
可视化训练效果
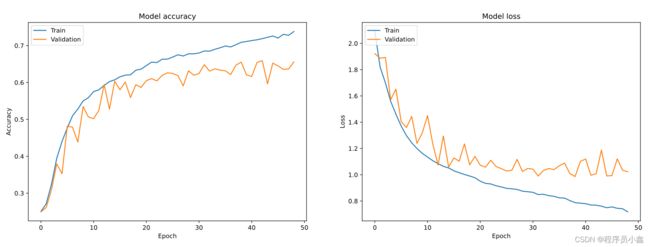
代码如下:
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
fig, axes = plt.subplots(1, 2, figsize=(18, 6))
# 绘制训练和验证精度曲线
axes[0].plot(history.history['accuracy'])
axes[0].plot(history.history['val_accuracy'])
axes[0].set_title('Model accuracy')
axes[0].set_ylabel('Accuracy')
axes[0].set_xlabel('Epoch')
axes[0].legend(['Train', 'Validation'], loc='upper left')
# 绘制训练和验证损失曲线
axes[1].plot(history.history['loss'])
axes[1].plot(history.history['val_loss'])
axes[1].set_title('Model loss')
axes[1].set_ylabel('Loss')
axes[1].set_xlabel('Epoch')
axes[1].legend(['Train', 'Validation'], loc='upper left')
plt.show()
通过观察曲线,我们可以得知神经网络后期存在轻微的过拟合现象。
评估测试效果
我们对测试数据集,进行评估分析,代码如下:
test_true = np.argmax(test_Y, axis=1)
test_pred = np.argmax(model.predict(test_X), axis=1)
print("CNN Model Accuracy on test set: {:.4f}".format(accuracy_score(test_true, test_pred)))
输出信息如下:
CNN Model Accuracy on test set: 0.6704
最终,我们的VGGNet网络,对各个数据集的准确率,如下表所示。
| Accuracy | |
|---|---|
| Train | 73.28% |
| Validation | 65.59% |
| Test | 67.04% |
使用混淆矩阵进行分析
绘制混淆矩阵,以分析表情之间是否会相互混淆,代码如下:
fusion_matrix(y_true, y_pred, classes,
normalize=False,
title=None,
cmap=plt.cm.Blues):
"""
此函数打印和绘制混淆矩阵
可以通过设置“normalize=True”来应用规范化。
"""
if not title:
if normalize:
title = 'Normalized confusion matrix'
else:
title = 'Confusion matrix, without normalization'
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 仅使用数据中显示的标签
classes = classes
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
#print("Normalized confusion matrix")
#else:
#print('Confusion matrix, without normalization')
#print(cm)
fig, ax = plt.subplots(figsize=(12, 6))
im = ax.imshow(cm, interpolation='nearest', cmap=cmap)
ax.figure.colorbar(im, ax=ax)
# 显示所有的标记...
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
# ... 用相应的列表条目标记它们
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# 旋转x轴标签并设置其对齐方式。
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
# 在数据维度上循环并创建文本批注
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
return ax
# %%
# 绘制归一化混淆矩阵
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
plot_confusion_matrix(test_true, test_pred, classes=emotion_labels, normalize=True, title='Normalized confusion matrix')
plt.show()
输出的混淆矩阵如下图所示。通过分析混淆矩阵,可知:Disgust比较容易和其他表情混淆,这是由于Disgust的样本数本身就很少。
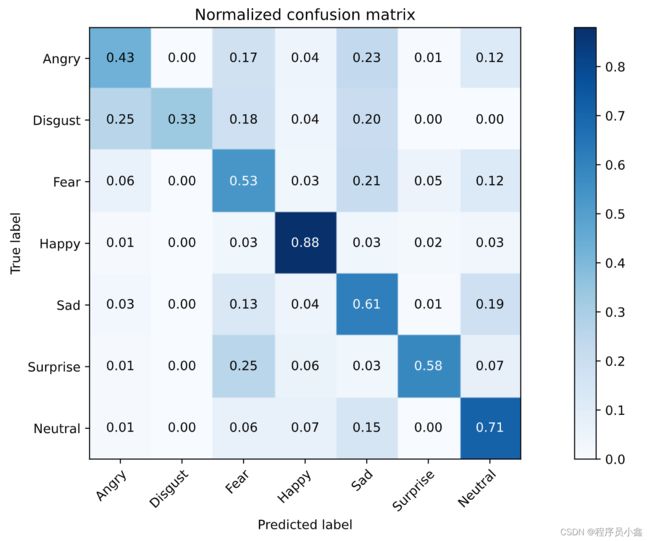
实时人脸表情识别
将已经训练好的模型存入本地,使用摄像头实时捕捉人脸,并识别出相应的表情。我们的思路是,从捕获的图像中,先使用人脸检测器,检测出人脸区域,然后将该区域实施灰度化,并将图片大小缩放至 48 × 48 48\times 48 48×48,最后送入我们的模型,进行预测,得到相应的表情输出。相应的代码如下:
import cv2 as cv
import numpy as np
from keras import models
model = models.load_model('./FER_Model.h5')
emotion_map = {0: 'Angry', 1: 'Disgust', 2: 'Fear', 3: 'Happy', 4: 'Sad', 5: 'Surprise', 6: 'Neutral'}
cap = cv.VideoCapture(0)
if not cap.isOpened():
print("Can not open camera!")
exit()
while True:
# 逐帧捕获
ret, frame = cap.read()
# 转换成灰度图像
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
classifier = cv.CascadeClassifier("./haarcascade_frontalface_default.xml")
faceRects = classifier.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
color = (0, 0, 255)
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 框出人脸
cv.rectangle(frame, (x, y), (x + h, y + w), color, 2)
# 获取人脸源
src = gray[y:y + w, x:x + h]
# 缩放至48*48
img = cv.resize(src, (48, 48))
# 归一化
img = img / 255.
# 扩展维度
x = np.expand_dims(img, axis=0)
x = np.array(x, dtype='float32').reshape(-1, 48, 48, 1)
# 预测输出
y = model.predict(x)
output_class = np.argmax(y[0])
cv.putText(frame, emotion_map[output_class], (200, 100), cv.FONT_HERSHEY_COMPLEX,
2.0, (0, 0, 250), 5)
cv.imshow("frame", frame)
if cv.waitKey(1) == ord('q'):
break
cap.release()
cv.destroyAllWindows()
上述代码中,haarcascade_frontalface_default.xml是由OpenCV提供的人脸检测器。
识别效果样例如下图所示。
系统总结
本系统实现了一种基于卷积神经网络的人脸表情识别模型,采用VGGNet神经网络,使用基于Nesterov momentum的SGD方法训练神经网络,并使用学习速率监测器减轻过拟合现象。最终,我们使用训练好的网络,构建出了可以实时识别人脸表情的一个系统。
本系统的识别精准度能够达到67%左右,尚有很大的提升空间,可改进的方向有:
- 由于Disgust的样本数量较少,可以考虑使用额外的训练数据或者进一步的数据增强;
- 尝试采用其他方法优化我们的网络,如Adagrad、AdaDelta、Adam;
- 考虑结合其他技术,如PCA、SVM等。
通过本次项目实践,更好地掌握了有关机器视觉方面的理论知识,并与卷积神经网络结合,同时,增强了我们的实战能力。