pytorch_神经网络模型搭建系列(4):自定义损失函数
目录
- 1、自定义损失函数
-
- 1.1 nn.Module和nn.Functional的区别与联系
-
- 1.1.1 二者的相似之处
- 1.1.2 二者的差别之处
-
- 1.1.2.1 调用方式
- 1.1.2.2 与nn.Sequential的结合运用
- 1.1.2.3 参数的管理
- 1.1.3 小结
- 1.2 定义损失函数
-
- 1.2.1 方法1:自定义类--继承nn.Module
- 1.2.2 方法2:自定义函数
- 1.2.3 方法3:扩展nn.autograd.function
- 1.3 具体代码算例
- 1.4 总结
1、自定义损失函数
前言:
首先,回顾一下上一次的核心内容:使用nn.Mudule来自定义激活函数,以及为激活函数设置可进行训练的参数,也就是参数化的激活函数
-
在深度学习框架PyTorch中已经内置了很多激活函数,如ReLU等
-
但是有时根据个人需要,需要自定义激活函数,甚至需要为激活函数添加可学习的参数,如PReLU,具体参见PyTorch官方github激活函数源码实现。
-
对于不需要可学习参数的激活函数的实现,比较简单,具体见PyTorch官网教程的一个例子
之前已经说过了pytorch自定义神经网络模型、自定义神经网络层、自定义激活函数,整个神经网络正向传播的搭建过程已经逐渐完整了,下面再说一说反向传播和训练的过程。
这次主要内容:
-
nn.Module 和 nn.Functional 区别和联系
-
自定义损失函数
import warnings
from typing import Tuple, Optional
import torch
from torch import Tensor
from .linear import _LinearWithBias
from torch.nn.init import xavier_uniform_
from torch.nn.init import constant_
from torch.nn.init import xavier_normal_
from torch.nn.parameter import Parameter
from .module import Module
from .. import functional as F
-
在深度学习框架PyTorch中已经内置了很多激活函数,如ReLU等
-
但是有时根据个人需要,需要自定义激活函数,甚至需要为激活函数添加可学习的参数,如PReLU,具体参见PyTorch官方github激活函数源码实现。
-
对于不需要可学习参数的激活函数的实现,比较简单,具体见PyTorch官网教程的一个例子
1.1 nn.Module和nn.Functional的区别与联系
主要参考资料为:
知乎解答
pytorch论坛
1.1.1 二者的相似之处
-
nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d 都是进行卷积,nn.Dropout 和nn.functional.dropout都是进行dropout,等等; -
运行效率也是近乎相同
但是,在不涉及可学习的参数情况下,推荐使用nn.Xxx,因为:
-
nn.functional.xxx只是函数接口,只涉及一些运算操作,但无法保留参数的信息 -
nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module
-
nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict等
1.1.2 二者的差别之处
1.1.2.1 调用方式
nn.Xxx
需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据
inputs = torch.rand(64, 3, 244, 244)
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
out = conv(inputs)
`nn.functional.xxx`
- 需要同时传入输入数据和weight, bias等其他参数
1.1.2.2 与nn.Sequential的结合运用
-
nn.Xxx继承于nn.Module, 能够很好的与nn.Sequential结合使用,
-
nn.functional.xxx无法与nn.Sequential结合使用
fm_layer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.2)
)
1.1.2.3 参数的管理
-
nn.Xxx不需要你自己定义和管理weight;
-
nn.functional.xxx需要你自己定义weight,每次调用的时候都需要手动传入weight, 不利于代码复用
(1)使用nn.Xxx定义一个CNN
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5,padding=0)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, padding=0)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.linear1 = nn.Linear(4 * 4 * 32, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
out = self.maxpool1(self.relu1(self.cnn1(x)))
out = self.maxpool2(self.relu2(self.cnn2(out)))
out = self.linear1(out.view(x.size(0), -1))
return out
(2)使用nn.function.xxx定义一个与上面相同的CNN
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1_weight = nn.Parameter(torch.rand(16, 1, 5, 5))
self.bias1_weight = nn.Parameter(torch.rand(16))
self.cnn2_weight = nn.Parameter(torch.rand(32, 16, 5, 5))
self.bias2_weight = nn.Parameter(torch.rand(32))
self.linear1_weight = nn.Parameter(torch.rand(4 * 4 * 32, 10))
self.bias3_weight = nn.Parameter(torch.rand(10))
def forward(self, x):
x = x.view(x.size(0), -1)
out = F.conv2d(x, self.cnn1_weight, self.bias1_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.conv2d(x, self.cnn2_weight, self.bias2_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.linear(x, self.linear1_weight, self.bias3_weight)
return out
注意:
-
上面两种定义方式得到CNN功能都是相同的,至于喜欢哪一种方式,是个人喜好问题
-
PyTorch官方推荐:
具有学习参数的(例如,conv2d, linear, batch_norm)采用nn.Xxx方式,没有学习参数的(例如,maxpool, loss func, activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式 -
但关于dropout,强烈推荐使用nn.Xxx方式,因为一般情况下只有训练阶段才进行dropout,在eval阶段都不会进行dropout。
使用nn.Xxx方式定义dropout,在调用model.eval()之后,model中所有的dropout layer都关闭- 但
以nn.function.dropout方式定义dropout,在调用model.eval()之后并不能关闭dropout
# 举例说明
import torch
# 建议多使用torch.nn.xxx
import torch.nn as nn
# 少使用torch.nn.functional.xxx
import torch.nn.functional as F
# 自定义一个类,使用了nn.Dropout
class Model1(nn.Module):t
def __init__(self):
super(Model1, self).__init__()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
return self.dropout(x)
# 自定义一个类,使用了F.dropout
class Model2(nn.Module):
def __init__(self):
super(Model2, self).__init__()
def forward(self, x):
return F.dropout(x)
# 调用类
m1 = Model1()
m2 = Model2()
inputs = torch.rand(10)
print(m1(inputs))
print(m2(inputs))
print(20 * '-' + "eval model:" + 20 * '-' + '\r\n')
m1.eval()
m2.eval()
print(m1(inputs))
print(m2(inputs))
tensor([1.7913, 0.5987, 0.6826, 1.1169, 0.0000, 1.8184, 0.9602, 1.2687, 0.0000,
0.0000])
tensor([1.7913, 0.0000, 0.6826, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 1.6976,
1.5953])
--------------------eval model:--------------------
tensor([0.8956, 0.2994, 0.3413, 0.5585, 0.5147, 0.9092, 0.4801, 0.6344, 0.8488,
0.7976])
tensor([1.7913, 0.0000, 0.0000, 1.1169, 1.0295, 0.0000, 0.9602, 0.0000, 0.0000,
1.5953])
1.1.3 小结
什么时候使用nn.functional.xxx,什么时候使用nn.Xxx?
-
这个问题依赖于你要解决你问题的复杂度和个人风格喜好。
-
在nn.Xxx不能满足你的功能需求时,nn.functional.xxx是更佳的选择,因为nn.functional.xxx更加的灵活(更加接近底层),你可以在其基础上定义出自己想要的功能 -
在能使用nn.Xxx情况下尽量使用,不行再换nn.functional.xxx ,感觉这样更能显示出网络的层次关系,也更加的纯粹(所有layer和model本身都是Module,一种和谐统一的感觉) -
简单来说, nn.Module是一个包装好的类,可以具体定义了一个网络层,可以维护状态和存储参数信息;
nn.Functional仅仅提供了一个计算,不会维护状态信息和存储参数
对于activation函数,比如(relu, sigmoid等)等没有训练参数,可以使用functional模块
1.2 定义损失函数
注意:
-
只要tensor算术操作(+, -,*, %,求导等)中,有一个tensor的
resquire_grad=True,则该操作得到的tensor就会反向传播,可以自动求导 -
对于需要训练的参数,记住自己实现的loss使用tensor提供的数学运算操作,并且设置resquire_grad=True -
下面有3种方式定义损失函数
1.2.1 方法1:自定义类–继承nn.Module
核心:
-
自定义类,继承了nn.Module类,并在定义的损失函数这个子类中必须实现init和forward方法
-
自定义损失函数和之前的自定义模型、自定义层、自定义激活函数其实都非常相似
注意:
- 定义一个损失函数类,继承自nn.Module,在forward中实现loss定义
- 所有的数学操作使用tensor提供的math operation
- 返回的tensor是0-dim的scalar
- 有可能会用到nn.functional中的一些操作https://www.zhihu.com/question/66988664
(1)自定义MSEloss实现:
class My_loss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.mean(torch.pow((x - y), 2))
(2)调用自定义损失函数
# 实例化对象
criterion = My_loss()
# 调用对象,传入真实值和预测值,求误差
loss = criterion(outputs, targets)
1.2.2 方法2:自定义函数
-
自定义类中,其实最终还是调用forward方法实现的
-
nn.Module还要维护一些其他变量和状态。不如直接自定义loss函数实现
# 直接定义函数 , 不需要维护参数,梯度等信息
# 注意所有的数学操作需要使用tensor完成。
def my_mse_loss(x, y):
return torch.mean(torch.pow((x - y), 2))
1.2.3 方法3:扩展nn.autograd.function
-
如果一些算法无法轻易调用API实现,比如nn.functional中没有提供自己需要的操作
-
那么就要自己实现backward和forward函数,要使用numpy或scipy中的方法实现,这个要自己定义实现前向传播和反向传播的计算过程
先给出参考资料,后续再补充具体讲
参考资料1
参考资料2
1.3 具体代码算例
- 附上前两种自定义损失函数的测试代码
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
##################自定义损失函数:三种方法,先给两种###########
# 1. 继承nn.Mdule
class My_loss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.mean(torch.pow((x - y), 2))
# 2. 直接定义函数,不需要维护参数,梯度等信息
# 注意所有的数学操作需要使用tensor完成。
def my_mse_loss(x, y):
return torch.mean(torch.pow((x - y), 2))
# 3, 如果使用 numpy/scipy的操作 可能使用nn.autograd.function来计算了
# 要实现forward和backward函数
input_size = 1
output_size = 1
# 超参数设置:定义迭代次数, 学习率以及模型形状的超参数
num_epochs = 60
learning_rate = 0.001
#####################准备数据########################
# 1. 准备数据集
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
######################定义网络模型########################
# 2. 定义网络结构 y=w*x+b 其中w的size [1,1], b的size[1,]
model = nn.Linear(input_size, output_size)
# 3.定义损失函数, 使用的是最小平方误差函数
# criterion = nn.MSELoss()
# 选择第一种自定义损失函数类
criterion = My_loss()
####################设置优化器############################
# 4.定义迭代优化算法, 使用的是随机梯度下降算法
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 给误差一个列表存储
loss_dict = []
####################循环训练############################
# 5. 迭代训练
for epoch in range(num_epochs):
# 5.1 准备tensor的训练数据和标签
# 需要把数据转换为torch
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
####################前向传播,计算预测值###############
# 5.2 前向传播计算网络结构的输出结果
outputs = model(inputs)
# 5.3 计算损失函数
# loss = criterion(outputs, targets)
# 6.1. 自定义损失函数1
# loss = criterion(outputs, targets)
####################计算损失##########################
# 6.2. 自定义损失函数2
loss = my_mse_loss(outputs, targets)
####################梯度归零、反向传播、参数更新#########
# 7.反向传播更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
####################打印误差##########################
# 8.打印训练信息和保存loss
# 把loss.item()的数字取出来,把列表中的值用误差填充
loss_dict.append(loss.item())
if (epoch+1) % 5 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
####################画出误差曲线、预测结果图##########################
# Plot the graph 画出原y与x的曲线与网络结构拟合后的曲线
#########################计算新的数据集的预测值#######################
predicted = model(torch.from_numpy(x_train)).detach().numpy()
###########################作图####################################
plt.plot(x_train, y_train, 'ro', label='Original data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()
#########################误差下降图##################################
# 画loss在迭代过程中的变化情况
plt.plot(loss_dict, label='loss for every epoch')
plt.legend()
plt.show()
Epoch [5/60], Loss: 0.2724
Epoch [10/60], Loss: 0.2144
Epoch [15/60], Loss: 0.1908
Epoch [20/60], Loss: 0.1813
Epoch [25/60], Loss: 0.1774
Epoch [30/60], Loss: 0.1758
Epoch [35/60], Loss: 0.1752
Epoch [40/60], Loss: 0.1749
Epoch [45/60], Loss: 0.1748
Epoch [50/60], Loss: 0.1747
Epoch [55/60], Loss: 0.1747
Epoch [60/60], Loss: 0.1747
误差损失下降图: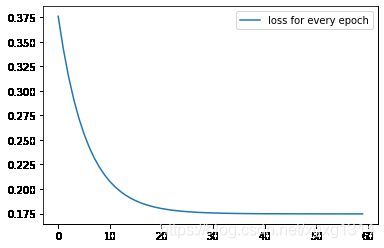
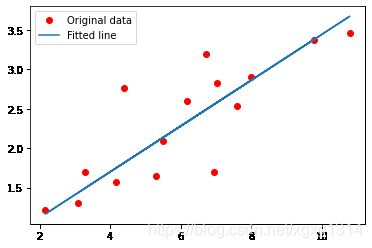
1.4 总结
1、关于nn.xxx和nn.functional.xxx
-
在不涉及可学习的参数情况下,推荐使用nn.Xxx
-
nn.functional.xxx只是函数接口,只涉及一些运算操作,但无法保留参数的信息 -
nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module
-
nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict等
2、关于自定义损失函数
-
一般可以使用类来自定义损失函数,此时可以借助nn.functional的一些函数,
class My_loss(nn.Module): -
也可以使用自定义函数的形式,
def my_mse_loss(x, y): -
如果nn.functional提供的函数不够用,那就要写一个numpy/scipy的扩展了