pytorch网络部分
torch.nn ( Neural network)
网络都在nn这库里面
图片中最常用的cnn
CNN
#cnn 常用参数in_channel out_channel padding填充 stride步长 kernel_size卷积核大小
input=torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]])
kernel=torch.tensor([[1,2,1],[0,1,0],[2,1,0]])
#第一个1是batch_size 第二个1是通道 因为cnn的输入需要这几个参数才行
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
output=F.conv2d(input,kernel,stride=1)
cnn具体是怎么卷积的:

如果out_channel大于1 那么就会生成多个卷积核 每个卷积核的参数不一样
#cnn具体的例子
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('./dataset',train=False,transform=transforms.ToTensor(),download=True)
dataLoader=DataLoader(dataset,batch_size=4,shuffle=True)
class psw(nn.Module):
def __init__(self):
super(psw, self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
return self.conv1(x)
p=psw()
for data in dataLoader:
#data返回的是数据和标签
imgs,target=data
out=p(imgs)
池化层
那我们再看一下池化层的作用:有平均池化,最大池化等 它也是有大小的,比如2x2的最大池化,就是在卷积后的结果中每2x2选一个最大的保留
class maxpool(nn.Module):
def __init__(self):
super(maxpool, self).__init__()
self.maxpool1=nn.MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,x):
return self.maxpool1(x)
pool=maxpool()
step=0
for data in dataLoader:
imgs,label=data
result=pool(imgs)
step+=1
线形层
具体就是 y = w i x i + b i y=w_ix_i+b_i y=wixi+bi 比较简单
#线性层
class fc(nn.Module):
def __init__(self):
super(fc, self).__init__()
self.fc1=nn.Linear(320,10)
def forward(self,x):
return self.fc1(x)
f=fc()
for data in dataLoader:
imgs,target=data
#imgs=torch.reshape(imgs,(1,1,1,-1))
#reshape可以替换为flatten
imgs=torch.flatten(imgs) #输出的结果为[10]
oputput=f(imgs)
现在我们用Sequential来创建一个vgg16的模型
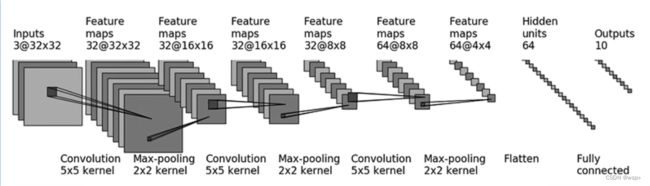
可以看到输入图片为33232,卷积核为55,输出大小为3232*32,通道变为32,但图片尺寸没变,那就要通过下面的公式来计算padding应该设置为多少

首先第一个公式 H o u t H_{out} Hout 输入高度为32 p a d d i n g [ 0 ] padding[0] padding[0]是要计算的 d i l i a t i o n [ 0 ] diliation[0] diliation[0]取默认值为1, k e r n e l kernel kernel_ s i z e [ 0 ] size[0] size[0]为5, s t r i d e [ 0 ] stride[0] stride[0]也就要计算的
同理第二个公式 W o u t W_{out} Wout带入对应参数,两式联立求解得 p a d d i n g [ 0 ] = 2 , s t r i d e [ 0 ] = 1 , p a d d i n g [ 1 ] = 2 , s t r i d e [ 1 ] = 1 , padding[0]=2,stride[0]=1,padding[1]=2,stride[1]=1, padding[0]=2,stride[0]=1,padding[1]=2,stride[1]=1,
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
class cifar10(nn.Module):
def __init__(self):
super(cifar10, self).__init__()
# self.con1=nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
# self.maxpool1=nn.MaxPool2d(kernel_size=2)
# self.con2=nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2,stride=1)
# self.maxpool2=nn.MaxPool2d(kernel_size=2)
# self.con3=nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2,stride=1)
# self.maxpool3=nn.MaxPool2d(kernel_size=2)
# self.fc1=nn.Linear(64*4*4,64)
# self.fc2=nn.Linear(64,10)
self.model=nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
nn.MaxPool2d(kernel_size=2),
Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self,x):
# x=self.maxpool1(self.con1(x))
# x=self.maxpool2(self.con2(x))
# x=self.maxpool3(self.con3(x))
# x=torch.flatten(x)
# x=F.relu(self.fc1(x))
# return self.fc2(x)
return self.model(x)
loss
#loss 不同的loss
inputs=torch.tensor([1,2,3],dtype=torch.float32)
target=torch.tensor([1,2,5],dtype=torch.float32)
#inputs=torch.reshape(inputs,(1,1,1,3))
"""
Input: (*)(∗), where *∗ means any number of dimensions.
Target: (*)(∗), same shape as the input.
"""
#loss=nn.L1Loss()
#print(loss(inputs,target))#(1-1+2-2+|5-3|)/3
#MESloss
#loss=nn.MSELoss()
#result=loss(inputs,target)
#print(result)#(1-1+2-2+|5-3|)**2/3
loss=nn.CrossEntropyLoss()
解释一下交叉熵CrossEntropyLoss
交叉熵主要是用来判定实际的输出与期望的输出的接近程度
l o s s ( x , c l a s s ) = − l o g ( e x p ( x [ c l a s s ] ) ∑ j e x p ( x [ j ] ) ) = − x [ c l a s s ] + l o g ( ∑ j e x p ( x [ j ] ) ) loss(x,class)=-log(\frac{exp(x[class])}{\sum_jexp(x[j])})=-x[class]+log(\sum_jexp(x[j])) loss(x,class)=−log(∑jexp(x[j])exp(x[class]))=−x[class]+log(j∑exp(x[j]))
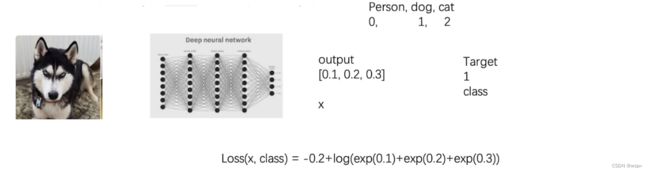
结合上面这个例子和公式,现在是一个三分类问题,网络输出 [ 0.1 , 0.2 , 0.3 ] [0.1,0.2,0.3] [0.1,0.2,0.3]而target是1表示dog
那想让 l o s s ( x , c l a s s ) loss(x,class) loss(x,class)越来越小,其实就是让公式的
- 第二部分 l o g ( ∑ j e x p ( x [ j ] ) ) log(\sum_jexp(x[j])) log(∑jexp(x[j]))越来越小,那这一部分其实是控制分布的概率的,希望不是这一类的概率越来越小,就是log里面的部分越小越好,
- 第一部分有个负号,那就是 x [ c l a s s ] x[class] x[class]越大越好,就是利用预测的结果,那如果预测的结果越准,那概率越大,那 x [ c l a s s ] x[class] x[class]自然大
不同的优化器
optim=optim.SGD(cifar.parameters(),lr=0.01)
现有的模型
#加载现有模型
#没有预训练的
vgg16_false=torchvision.models.vgg16(pretrained=False)
#预训练好的
vgg16_true=torchvision.models.vgg16(pretrained=True)
#改动现有网络模型
print(vgg16_false)
#添加module
vgg16_false.add_module('add_line',nn.Linear(1000,10))
print(vgg16_false)
#改动module
print(vgg16_true)
vgg16_true.classifier[6]=nn.Linear(4096,10,bias=True)
print(vgg16_true)
一个完整的在GPU上训练的例子
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import torch.optim as optim
import torchvision.transforms as transforms
from cifar10_network import cifar10
"""
模型 loss 数据都要转到gpu上
"""
train_data=torchvision.datasets.CIFAR10(root='/data',train=True,transform=transforms.ToTensor(),download=True)
test_data=torchvision.datasets.CIFAR10(root='/data',train=False,transform=transforms.ToTensor(),download=True)
dataloader_train=DataLoader(dataset=train_data,shuffle=True,batch_size=64)
dataloader_test=DataLoader(dataset=test_data,shuffle=True,batch_size=64)
train_data_size=len(train_data)
test_data_size=len(test_data)
print('训练的数据长度为{}'.format(train_data_size))
print('测试的数据长度为{}'.format(test_data_size))
device=torch.device("cuda" if torch.cuda.is_available() else 'cpu')
model=cifar10().to(device)
#1e-2 =1x10^(-2)
lr=0.001
loss=nn.CrossEntropyLoss().to(device)
optim=optim.SGD(model.parameters(),lr=lr)
for epoch in range(100):
print('第{}轮开始了'.format(epoch))
for data in dataloader_train:
imgs,labels=data
imgs=imgs.to(device)
labels=labels.to(device)
output=model(imgs)
loss=loss(output,labels)
optim.zero_grad()
loss.backward()
optim.step()
#每训练完一次都在测试数据上测试一下 测试的时候不需要调优
total_test_loss=0
total_accuary=0
with torch.no_grad():
for data in dataloader_test:
imgs,labels=data
imgs = imgs.to(device)
labels = labels.to(device)
output=model(imgs)
loss=loss(output,labels)
total_test_loss+=loss
accuracy=(output.argmax(1)==labels).sum()
total_accuary+=accuracy
print('测试集上的loss为:{}'.format(total_test_loss))
print('整体测试准确率:{}'.format(total_accuary/test_data_size))
torch.save(model.state_dict(),'modeparap.pth')