3亿会员、4亿商品,深度学习在大型电商商品推荐的应用实践!
常见算法套路
电商品推荐中的常见算法大致如下:
基于商品相似度
比如食物 A 和食物 B,根据它们的价格、味道、保质期、品牌等维度,可以计算它们的相似程度,可以想象,我买了包子,很有可能顺路带一盒水饺回家。
优点:冷启动,只要你有商品的数据,在业务初期用户数据不多的情况下,也可以做推荐。
缺点:预处理复杂,任何一件商品,维度可以说至少可以上百,如何选取合适的维度进行计算,涉及到工程经验,这些也是花钱买不到的。
典型:亚马逊早期的推荐系统。
基于关联规则
最常见的就是通过用户购买的习惯,经典的就是“啤酒尿布”的案例,但是实际运营中这种方法运用的是最少的。
首先要做关联规则,数据量一定要充足,否则置信度太低,当数据量上升了,我们有更多优秀的方法,可以说没有什么亮点,业内的算法有 apriori、ftgrow 之类的。
优点:简单易操作,上手速度快,部署起来也非常方便。
缺点:需要有较多的数据,精度效果一般。
典型:早期运营商的套餐推荐。
基于物品的协同推荐
假设物品 A 被小张、小明、小董买过;物品 B 被小红、小丽、小晨买过;物品 C 被小张、小明、小李买过。
直观的来看,物品 A 和物品 C 的购买人群相似度更高(相对于物品 B),现在我们可以对小董推荐物品 C,小李推荐物品 A,这个推荐算法比较成熟,运用的公司也比较多。
优点:相对精准,结果可解释性强,副产物可以得出商品热门排序。
缺点:计算复杂,数据存储瓶颈,冷门物品推荐效果差。
典型:早期一号店商品推荐。
基于用户的协同推荐
假设用户 A 买过可乐、雪碧、火锅底料;用户 B 买过卫生纸、衣服、鞋;用户 C 买过火锅、果汁、七喜。
直观上来看,用户 A 和用户 C 相似度更高(相对于用户 B),现在我们可以对用户 A 推荐用户 C 买过的其他东西,对用户 C 推荐用户 A 买过的其他东西,优缺点与基于物品的协同推荐类似,不重复了。
基于模型的推荐
svd+、特征值分解等等,将用户的购买行为的矩阵拆分成两组权重矩阵的乘积,一组矩阵代表用户的行为特征,一组矩阵代表商品的重要性,在用户推荐过程中,计算该用户在历史训练矩阵下的各商品的可能性进行推荐。
优点:精准,对于冷门的商品也有很不错的推荐效果。
缺点:计算量非常大,矩阵拆分的效能及能力瓶颈一直是受约束的。
典型:惠普的电脑推荐。
基于时序的推荐
这个比较特别,在电商运用的少,在 Twitter,Facebook,豆瓣运用的比较多,就是在只有赞同和反对的情况下,怎么进行评论排序。
基于深度学习的推荐
现在比较火的 CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)都有运用在上面推荐的例子,但是都还处于试验阶段。有个基于 word2vec 的方法已经相对比较成熟,也是我们今天介绍的重点。
优点:推荐效果非常精准,所需要的基础存储资源较少。
缺点:工程运用不成熟,模型训练调参技巧难。
典型:苏宁易购的会员商品推荐。
item2vec 工程引入
现在苏宁的商品有约 4 亿个,商品的类目有 10000 多组,大的品类也有近 40 个,如果通过传统的协同推荐,实时计算的话,服务器成本,计算能力都是非常大的局限。
会员研发部门因为不是主要推荐的应用部门,所以在选择上,我们期望的是更加高效高速且相对准确的简约版模型方式,所以我们这边基于 word2vec 的原始算法,仿造了 itemNvec 的方式。
首先,让我们对 itemNvec 进行理论拆分:
01
part one:n-gram
目标商品的前后商品对目标商品的影响程度
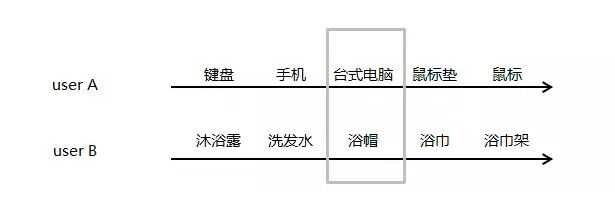
这是两个用户 userA,userB 在易购上面的消费 time line,灰色方框内为我们观察对象,试问一下,如果换一下灰色方框内的 userA、userB 的购买物品,直观的可能性有多大?
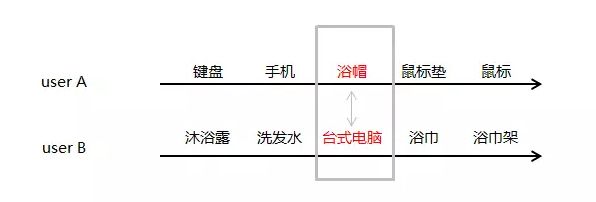
直观的体验告诉我们,这是不可能出现,或者绝对不是常出现的。所以,我们就有一个初始的假设,对于某些用户在特定的类目下,用户的消费行为是连续影响的。
换句话说,就是我买了什么东西是依赖我之前买过什么东西。如何通过算法语言解释上面说的这件事呢?大家回想一下,naive bayes 做垃圾邮件分类的时候是怎么做的?
假设“我公司可以提供发票、军火出售、航母维修”这句话是不是垃圾邮件?
P1(“垃圾邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“垃圾邮件”)p(“我公司可以提供发票、军火出售、航母维修”/“垃圾邮件”)/p(“我公司可以提供发票、军火出售、航母维修”)
=p(“垃圾邮件”)p(“发票”,“军火”,“航母”/“垃圾邮件”)/p(“发票”,“军火”,“航母”)
同理
P2(“正常邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“正常邮件”)p(“发票”,“军火”,“航母”/“正常邮件”)/p(“发票”,“军火”,“航母”)
我们只需要比较 p1 和 p2 的大小即可,在条件独立的情况下可以直接写成:
P1(“垃圾邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“垃圾邮件”)p(“发票”/“垃圾邮件”)p(“军火”/“垃圾邮件”)p(“航母”/“垃圾邮件”)
P2(“正常邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“正常邮件”)p(“发票”/“正常邮件”)p(“军火”/“正常邮件”)p(“航母”/“正常邮件”)
但是,我们看到,无论“我公司可以提供发票、军火出售、航母维修”词语的顺序怎么变化,不影响它最后的结果判定,但是我们这边的需求里面前面买的东西对后项的影响会更大。
冰箱=>洗衣机=>衣柜=>电视=>汽水,这样的下单流程合理。
冰箱=>洗衣机=>汽水=>电视=>衣柜,这样的下单流程相对来讲可能性会更低。
但是对于 naive bayes,它们是一致的。所以,我们这边考虑顺序,还是上面那个垃圾邮件的问题。
P1(“垃圾邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“垃圾邮件”)p(“发票”)p(“军火”/“发票”)p(“军火”/“航母”)
P1(“正常邮件”|“我公司可以提供发票、军火出售、航母维修”)
=p(“正常邮件”)p(“发票”)p(“军火”/“发票”)p(“军火”/“航母”)
这边我们每个词只依赖前一个词,理论上讲依赖 1-3 个词通常都是可接受的。
以上考虑顺序的 bayes 就是基于著名的马尔科夫假设(Markov Assumption):下一个词的出现仅依赖于它前面的一个或几个词下的联合概率问题,相关详细的理论数学公式就不给出了,这里涉及一个思想。
02
part two:Huffman Coding
更大的数据存储形式
我们常用的 user 到 item 的映射是通过 one hot encoding 的形式去实现的,这有一个非常大的弊端就是数据存储系数且维度灾难可能性极大。
回到最初的那组数据:现在苏宁的商品有约 4 亿个,商品的类目有 10000 多组,大的品类也有近 40 个,同时现在会员数目达到 3 亿。
要是需要建造一个用户商品对应的购买关系矩阵做基于用户的协同推荐的话,我们需要做一个 4 亿 X 6 亿的 1/0 矩阵,这个是几乎不可能的,Huffman 采取了一个近似二叉树的形式进行存储。
我们以易购商品购买量为例,讲解一下如何以二叉树的形式替换 one hot encoding 存储方式:
假设
818 苏宁大促期间,经过统计,有冰箱=>洗衣机=>烘干机=>电视=>衣柜=>钻石的用户下单链条(及购买物品顺序如上),其中冰箱总售出 15 万台,洗衣机总售出 8 万台,烘干机总售出 6 万台,电视总售出 5 万台,衣柜总售出 3 万台,钻石总售出 1 万颗。
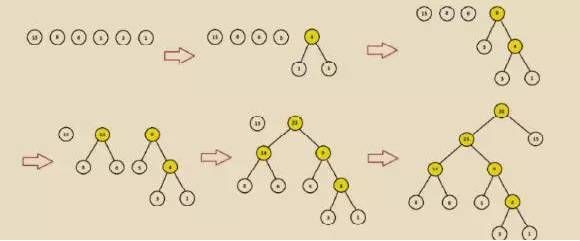
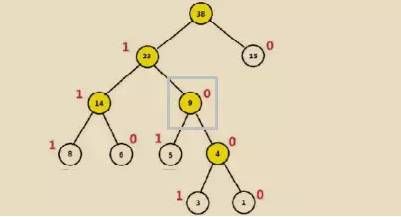
Huffman 树构造过程:
-
给定{15,8,6,5,3,1}为二叉树的节点,每个树仅有一个节点,那就存在 6 颗单独的树。
-
选择节点权重值最小的两颗树进行合并也就是{3}、{1},合并后计算新权重3+1=4。
-
将{3},{1}树从节点列表删除,将 3+1=4 的新组合树放回原节点列表。
-
重新进行 2-3,直到只剩一棵树为止。
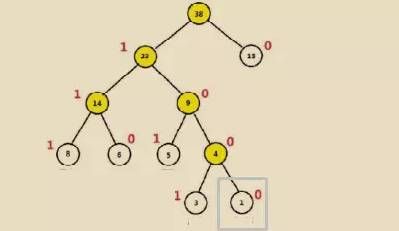
针对每层每次分支过程,我们可以将所有权重大的节点看做是 1,权重小的节点看做是 0,相反亦可。
现在,我们比如需要知道钻石的 code,就是 1000,也就是灰色方框的位置,洗衣机的 code 就是 111。
这样的存储利用了 0/1 的存储方式,也同时考虑了组合位置的排列长度,节省了数据的存储空间。
03
part three:node probility
最大化当前数据出现可能的概率密度函数
对于钻石的位置而言,它的 Huffman code 是 1000,那就意味着在每一次二叉选择的时候,它需要一次被分到 1,三次被分到 0。
而且每次分的过程中,只有 1/0 可以选择,这是不是和 logistic regression 里面的 0/1 分类相似,所以这边我们也直接使用了 lr 里面的交叉熵来作为 loss function。
其实对于很多机器学习的算法而言,都是按照先假定一个模型,再构造一个损失函数,通过数据来训练损失函数求 argmin(损失函数)的参数,放回到原模型。
让我们详细的看这个钻石的例子:

第一步:p(1|No.1 层未知参数)=sigmoid(No.1 层未知参数)
第二步:p(0|No.2 层未知参数)=sigmoid(No.2 层未知参数)
同理,第三、第四层:
-
p(0|No.3 层未知参数)=sigmoid(No.3 层未知参数)
-
p(0|No.4 层未知参数)=sigmoid(No.4 层未知参数)
然后求p(1|No.1 层未知参数) x p(0|No.2 层未知参数) x p(0|No.3 层未知参数)x p(0|No.4 层未知参数)最大下对应的每层的未知参数即可。
求解方式与 logistic 求解方式近似,未知参数分布偏导,后续采用梯度下降的方式。(极大、批量、牛顿按需使用)
04
part four:approximate nerual network
商品的相似度
刚才在 part three 里面有个 p(1|No.1 层未知参数)这个逻辑,这个 NO.1 层未知参数里面有一个就是商品向量。
举个例子:
存在 1000 万个用户有过:“啤酒=>西瓜=>剃须刀=>百事可乐”的商品购买顺序。
10 万个用户有过:“啤酒=>苹果=>剃须刀=>百事可乐”的商品购买顺序,如果按照传统的概率模型比如 navie bayes 或者 n-gram 来看。
P(啤酒=>西瓜=>剃须刀=>百事可乐)>>p(啤酒=>苹果=>剃须刀=>百事可乐),但是实际上这两者的人群应该是同一波人,他们的属性特征一定会是一样的才对。
我们这边通过随机初始化每个商品的特征向量,然后通过 part three 的概率模型去训练,最后确定了词向量的大小。除此之外,还可以通过神经网络算法去做这样的事情。

Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》介绍了详细的方法。
我们这边需要知道的就是,对于最小维度商品,我们以商品向量(0.8213,0.8232,0.6613,0.1234,...)的形式替代了0-1点(0,0,0,0,0,1,0,0,0,0...),单个的商品向量无意义。
但是成对的商品向量,我们就可以比较他们间的余弦相似度,比较类目的相似度,甚至品类的相似度。
Python代码实现
01
数据读取
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib as mt
from gensim.models import word2vec
from sklearn.model_selection import train_test_split
order_data = pd.read_table('C:/Users/17031877/Desktop/SuNing/cross_sell_data_tmp1.txt')
dealed_data = order_data.drop('member_id', axis=1)
dealed_data = pd.DataFrame(dealed_data).fillna(value='')
02
简单的数据合并整理
# 数据合并
dealed_data = dealed_data['top10'] + [" "] + dealed_data['top9'] + [" "] + dealed_data['top8'] + [" "] + \
dealed_data['top7'] + [" "] + dealed_data['top6'] + [" "] + dealed_data['top5'] + [" "] + dealed_data[
'top4'] + [" "] + dealed_data['top3'] + [" "] + dealed_data['top2'] + [" "] + dealed_data['top1']
# 数据分列
dealed_data = [s.encode('utf-8').split() for s in dealed_data]
# 数据拆分
train_data, test_data = train_test_split(dealed_data, test_size=0.3, random_state=42)
03
模型训练
# 原始数据训练
# sg=1,skipgram;sg=0,SBOW
# hs=1:hierarchical softmax,huffmantree
# nagative = 0 非负采样
model = word2vec.Word2Vec(train_data, sg=1, min_count=10, window=2, hs=1, negative=0)
接下来就是用 model 来训练得到我们的推荐商品,这边有三个思路,可以根据具体的业务需求和实际数据量来选择:
相似商品映射表
# 最后一次浏览商品最相似的商品组top3
x = 1000
result = []
result = pd.DataFrame(result)
for i in range(x):
test_data_split = [s.encode('utf-8').split() for s in test_data[i]]
k = len(test_data_split)
last_one = test_data_split[k - 1]
last_one_recommended = model.most_similar(last_one, topn=3)
tmp = last_one_recommended[0] + last_one_recommended[1] + last_one_recommended[2]
last_one_recommended = pd.concat([pd.DataFrame(last_one), pd.DataFrame(np.array(tmp))], axis=0)
last_one_recommended = last_one_recommended.T
result = pd.concat([pd.DataFrame(last_one_recommended), result], axis=0)
考虑用户最后一次操作的关注物品 x,干掉那些已经被用户购买的商品,剩下的商品表示用户依旧有兴趣但是因为没找到合适的或者便宜的商品,通过商品向量之间的相似度,可以直接计算出,与其高度相似的商品推荐给用户。
最大可能购买商品
根据历史上用户依旧购买的商品顺序,判断根据当前这个目标用户近期买的商品,接下来他最有可能买什么?
比如历史数据告诉我们,购买了手机+电脑的用户,后一周内最大可能会购买背包,那我们就针对那些近期购买了电脑+手机的用户去推送电脑包的商品给他,刺激他的潜在购物需求。
# 向量库
rbind_data = pd.concat(
[order_data['top1'], order_data['top2'], order_data['top3'], order_data['top4'], order_data['top5'],
order_data['top6'], order_data['top7'], order_data['top8'], order_data['top9'], order_data['top10']], axis=0)
x = 50
start = []
output = []
score_final = []
for i in range(x):
score = np.array(-100000000000000)
name = np.array(-100000000000000)
newscore = np.array(-100000000000000)
tmp = test_data[i]
k = len(tmp)
last_one = tmp[k - 2]
tmp = tmp[0:(k - 1)]
for j in range(number):
tmp1 = tmp[:]
target = rbind_data_level[j]
tmp1.append(target)
test_data_split = [tmp1]
newscore = model.score(test_data_split)
if newscore > score:
score = newscore
name = tmp1[len(tmp1) - 1]
else:
pass
start.append(last_one)
output.append(name)
score_final.append(score)
联想记忆推荐
在最大可能购买商品中,我们根据这个用户近期的购买行为,从历史已购用户的购买行为数据发现规律,提供推荐的商品。
还有一个近似的逻辑,就是通过目标用户最近一次的购买商品进行推测,参考的是历史用户的单次购买附近的数据,详细如下:
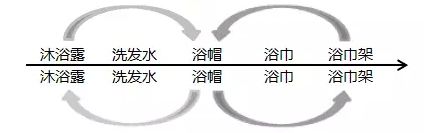
这个实现也非常的简单,这边代码我自己也没有写,就不贴了,采用的还是 word2vec 里面的predict_output_word(context_words_list, topn=10),Report the probability distribution of the center word given the context words as input to the trained model。
上述这些详细做起来还是比较复杂的,我这边也是简单的贴了一些思路供大家参考和实践。