图片超分辨率python_探测图片分辨率,从20次/s到30000次/s
背景
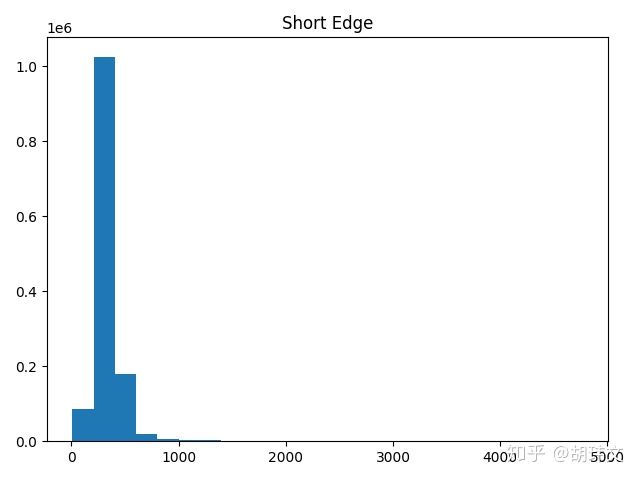
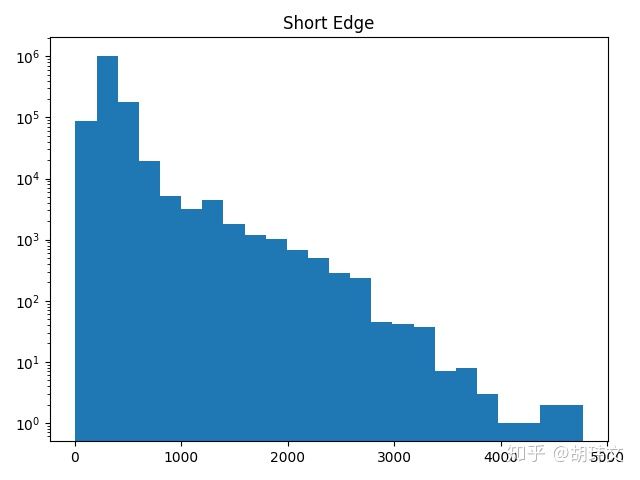
ImageNet数据集有大约1.3e6张图片,不禁令人好奇,其中的图片的分辨率的分布是怎样的呢?在机器学习的训练中,如果我们提前缩小图片的分辨率会不会大幅提升训练速度呢?
FFProbe
ffprobe是著名的多媒体工具FFmpeg的一个组件,简单地通过命令行调用即可快速查询各种多媒体文件的信息。虽然它主要的用途是查询视频,但也可以用于查询图片的信息,其中也包括了的分辨率。以下是使用的方法:
ffprobe -loglevel warning -show_entries stream=height,width -print_format json /path/to/image.jpg它的输出大概是这样的,通过解析JSON就能获得图片的分辨率了。
{
"programs": [
],
"streams": [
{
"width": 480,
"height": 320
}
]
}那剩下的问题就是,怎么快速调用ffprobe 1.3e6次,并统计它的结果了。
Python subprocess:20次/s
要说现在机器学习社区什么编程语言最火,那自然是Python了。这次任务也用Python来试试。最简单直接的方法,首先,用pathlib.Path.rglob()获取一个所有图片的列表,然后逐个图片用subprocess.run调用ffprobe,并解析返回的JSON,写到一个dict里。这里还直接用到了之前写的用asyncio协程来同时起多个子进程的方法。其主体部分大概是这样:
proc = await asyncio.create_subprocess_exec(
'ffprobe', '-loglevel', 'warning',
'-show_entries', 'stream=height,width',
'-print_format', 'json',
str(img),
stdout=asyncio.subprocess.PIPE, stderr=None, stdin=asyncio.subprocess.DEVNULL
)
stdout, stderr = await proc.communicate()
if proc.returncode != 0:
logger.error('ffprobe %s failed with return code %d', img, proc.returncode)
return (str(img), None, None)
probe_result = json.loads(stdout)['streams'][0]
return (str(img), probe_result['width'], probe_result['height'])这个版本的代码没有留下来了,但最终的速度,大约只有不到20次/s,也就是说,跑完整个数据集大概要20小时,这个速度显然不能接受。但首先,我们来用cprofile看看它为啥这么慢:
ncalls tottime percall cumtime percall filename:lineno(function)
980 40.736 0.042 40.736 0.042 {built-in method _posixsubprocess.fork_exec}
4897 18.612 0.004 18.612 0.004 {built-in method posix.read}
980 0.229 0.000 59.740 0.061 .../python3.7/subprocess.py:1412(_execute_child)绝大多数时间都花费在了内置函数fork_exec上。究竟为啥还尚且不知。
multiprocessing + subprocess: 200次/s
加速最简单的方法,那自然是并行化了。得益于我们20核心的高性能服务器,这样的策略一般都能取得很不错的效果。最简单的方案,用multiprocessing.Process运行多个进程,用queue.Queue在进程间传递需要探测的图片路径和探测结果。这样的话,性能大约提升了10倍,花费了约2小时完成了这项工作。但其实我还是不太满意这样的性能。毕竟,为啥这么常用的subprocess会这么慢呢。
forkserver: 2000次/s
这事挺神奇的,但想通了的话却也在情理之中。
首先是来自一个发现,我的程序处理的图片总数量越少,处理速度就越快,并且这个效果非常明显。这挺奇怪的,处理的总数量和处理速度应该没有关系的吧,毕竟不管有多少图片,都是一张一张处理的呀。在处理图片数量少的时候,cprofile的结果大概是这样:
ncalls tottime percall cumtime percall filename:lineno(function)
20738 25.725 0.001 25.725 0.001 {built-in method posix.read}
4148 21.226 0.005 21.226 0.005 {built-in method _posixsubprocess.fork_exec}可以看到,fork_exec的percall(每次调用)时间大概少了一个数量级。CPU利用率统计结果来看,system占用的比例也明显减少了。
在我冥思苦想了几十分钟后,终于想到了答案。这事还得从subprocess的底层实现说起。在Linux系统中,要启动一个子进程,通常需要使用fork和execve这两个系统调用,其中的fork就是罪魁祸首了。fork的作用是创建一个和当前进程一模一样的进程,虽然实际的内存页是有“写时复制”的,并不需要在fork时进行复制,但系统还要处理页表之类的数据结构,依然需要消耗一些时间。而当把整个数据集加载进内存后,整个Python进程大约会占用800M的内存,虚拟地址空间更是到了1G以上。这些占用的内存所需数据结构的维护正是导致fork性能低的原因。而当图片总数越少时,Python进程的内存消耗就更少,自然fork得更快了。
在知道了这一点以后,解决方法就很简单了。我们使用multiprocessing.get_context('forkserver')来获得一个context,之后用这个context来启动worker进程。这样的话,worker进程是从0开始执行的,而不是从主进程fork出来的,它的内存占用在稳定时只有18M,自然fork的速度非常快了。它的cprofile结果大概是这样的:
ncalls tottime percall cumtime percall filename:lineno(function)
416786 347.520 0.001 347.520 0.001 {built-in method posix.read}
83167 89.737 0.001 89.737 0.001 {built-in method _posixsubprocess.fork_exec}fork_exec的速度变得非常快了。整个数据集也大概只需要12分钟就能跑完。但还能更快!
PyAV:20000次/s
但是说到底,不断起子进程本来就不是个高效的做法。进程启动,进程间通信等造成的开销很大。FFmpeg项目有个很著名的Python的绑定,叫PyAV,这个项目可以帮助你直接在进程内调用FFmpeg的功能。经过一番摸索,用PyAV来探测图片的分辨率非常的简单,甚至比启动子进程更简单:
import av
container = av.open(str(img))
s = container.streams[0]
width = s.codec_context.width
height = s.codec_context.height直接用这个替换掉原来启动子进程的代码,效果立竿见影,又快了10倍,只需要1-2分钟就能完成。要知道,遍历一遍数据集的目录获取文件列表都需要几十秒的时间。
concurrent.futures:28092次/s
最后的一些优化了,之前为了配合我用asyncio来启动子进程的做法,我自己用multiprocessing实现了多进程。但这是比较底层的做法。现在既然我抛弃了子进程,那我就可以使用一些更高级的封装。通过concurrent.futures.ProcessPoolExecutor我可以很方便地把任务分配到多个进程里。得益于更高效的实现,以及它将任务打包到更大的块中再分配给子进程的策略,性能又提高了约40%
with ProcessPoolExecutor(max_workers=WORKER) as executor:
map_iter = executor.map(probe, pending_imgs, chunksize=256)
for img_path, width, height in tqdm(map_iter, total=len(pending_imgs)):
results[img_path] = [width, height]总结
这真可谓是个经典的例子,不要以为现在计算机的硬件已经很快了,写软件的时候就能为所欲为。通过我对软件的知识,理解和探索,我用了几个小时的时间,把程序的性能从最naïve的版本,提升了3个数量级。这能帮助以后我们能更快地完成这类任务,也让我对相关软件的认识更近一步了。
它还可以更快吗?当然可以,但是,现在这个速度对于我们来说,已经远远超过了“够用”的程度了吧。
对了,回到最初的问题,ImageNet的图像分辨率的分布究竟是怎样的呢。看看我的最终结果吧。总的来说,绝大多数图片都不是很大,提前缩小图片的分辨率应该不会对训练速度带来什么帮助。
第一次发文章,请多包涵。用空的话,去我的博客看看吧