Point and Ask: Incorporating Pointing into VQA论文笔记
Point and Ask: Incorporating Pointing into VQA论文笔记
- 一、Abstract
- 二、引言部分
- 三、相关Work
-
- 1、Spatial Grounding in VQA
- 2、Point input
- 四、数据集1️⃣:PointQA-Local: reasoning about a region
-
- 1.PointQA-Local dataset
- 2、PointQA-Local models
- 3、PointQA-Local evaluation
- 4、Spatial vs Verbal Disambiguation
- 五、数据集2️⃣:PointQA-LookTwice: reasoning about a local region in the broader image context
-
- 1、PointQA-LookTwice dataset
- 2、Counteracting priors,反先验知识?牛皮
- 3、PointQA-LookTwice model
- 4、PointQA-LookTwice evaluation
- 六、数据集3️⃣:PointQA-General: generalized reasoning from a point input
-
- 1、PointQA-General dataset
- 2、PointQA-General models
- 3、PointQA-General evaluation
- 七、结论
- 八、附录部分
-
- A. Human Evaluations
- 总结
写在前面
这是第二篇论文笔记了,好好学习,多读论文多读书学习。
论文链接: Point and Ask: Incorporating Pointing into VQA
代码已开源: Github
一、Abstract

重点蓝色部分:点出本文内容:考虑包含一个空间点推理式的视觉问答;
本文contribution:
1:引入并促进了一种 point-input的问题;
2:定义了三种新颖的问题类型;
3:对于这三种问题,引入了对应的数据集和一系列模型;
区别于以往问题类型的依据:
1:确保设计出的问题需要根据spatial reference才能得出精确的答案;
2:采用的是point-spatial输入,而非传统的矩形框输入
二、引言部分
先表达一下VQA发展的快,针对一些问题(如GQA数据集中指向问题),批评其越来越不realistic,简短说,就是不像人话。所以作者提出自己的数据集(作为VQA任务的一个扩展),并指出与其他数据集不同的地方,也就是abstract中的“区别于以往问题类型的依据”:
1:确保设计出的问题需要根据spatial reference才能得出精确的答案;
2:采用的是point-spatial输入,而非传统的矩形框输入
下面是其示例:

输入是一幅带有spatial point的图像,输出是多选答案。
另外就是问题的设计了:

1、指向性代词与图片中的pixel point对应,也就是需要对图像局部进行分析;
2、对全局图像的理解;
3、构建point disambiguation数据集(改写Visual7W);
同时作者论述了这三种数据集的构建,以及拿一些模型来测试
本文的contributions:
1、引入了一种新的Point-input类型的问题;
2、设计了一系列 benchmark datasets;——这个应该有戏;
3、引入了解决该问题的模型;
三、相关Work
1、Spatial Grounding in VQA
首先介绍了VQA数据集的发展过程,例如:Visual7W,GQA 以及后来的VQAv2+VQAcp数据集,同时作者抛出自己的论点:visual grounding在VQA数据集中的重要性;
然后继续深入说明这几个数据集,先说优点,visual7W引入poin-QA,“which”问题;
VG 数据集引入region-based QAs,缺点是17%的问题才需要region区域才能回答出答案;
所以作者是第一个引入需要spatial grounding signal才能准确回答问题的benchmark;
接下来 将相应模型的主要核心也介绍了一下,主要是attention机制,poxel-wise 预测,heatmap or semantic segmentation。
2、Point input
强调了将spatial grounding input 送入模型还没有人这样干过。
四、数据集1️⃣:PointQA-Local: reasoning about a region
(后面分别介绍了三种数据集以及对应的模型,写作套路都是相同的)
首先引入一下数据集的介绍:

1.PointQA-Local dataset
从VG数据集产生,3种问题的模板,后面介绍了数据集是如何构建的
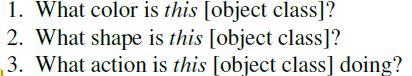
依据Attribute selection分成三类:color, shape, action,and size,而Size并非物体绝对属性所以被排除掉;
问题的产生:在相同种类中有超过一种属性的object将被排除在外,目的是为了避免混淆;
同时点明数据集存在的bias——97.2%都是有关颜色,以及举例,同时强调bisa无关问题难度。
数据集的分布:

最后提及了人类在该数据集上的表现:在test-final数据集上面76%的精度。
2、PointQA-Local models
采用Pythia作为基准模型,上来解释了一下为何需要这个 模型的原因:不复杂、简单易分析;
接下来讲了一下Pythia模型的结构:参考链接:Pythia v0.1: the Winning Entry to the VQA Challenge 2018
然后叙述一下对pythia模型的修改。主要是为了让输入匹配,同时描述一下优点

3、PointQA-Local evaluation
首先描述一下实验的设置,基本上差不多,学习率,梯度优化这种
然后作者根据删除区域的不同做了消融实验:

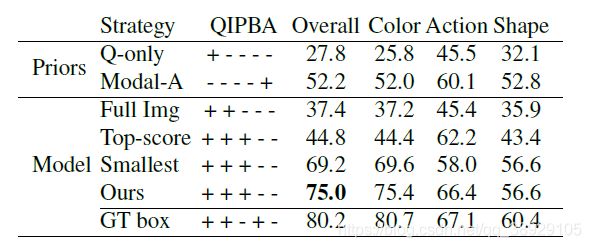
分析:主要根据注意力值的落点分析pythia模型的效果;
4、Spatial vs Verbal Disambiguation
两种消除歧义的方法:
1、引入空间点;
2、在question描述上更加具体;
作者分别设计两个数据集:
1、口语上消除歧义;
2、采用spatial point消除歧义
然后用pythia在这两者上实验,结果2效果很好
五、数据集2️⃣:PointQA-LookTwice: reasoning about a local region in the broader image context
这个数据集需要全面理解图像内容才能准确回问题:原因是都是计数问题,只有三种选项,1,2,>2,
从而引入PointQA-Look Twice,设计计数问题数据集。
1、PointQA-LookTwice dataset
计数问题的两种指代方式:两种问题类型,these,those,supercategory+these/those

2、Counteracting priors,反先验知识?牛皮
开始同样讲解数据集如何构建的,然后描述一下数据集的统计:

人类评估精度:test数据集上79%
3、PointQA-LookTwice model
与上一个模型讲解类似:简要介绍一下pythia处理过程;
4、PointQA-LookTwice evaluation

Global vs local-only attention:
局部注意力和全局注意力在计数数量上的分析,(在pointqa-local数据集上),验证了global model适用于 a wider range of pointing-based questions
六、数据集3️⃣:PointQA-General: generalized reasoning from a point input
同样简述:这次进行一个全局实验,修改transformer-based模型,在全新的数据集上进行。
1、PointQA-General dataset
第三个数据集:PointQA-General,改写Visual7W中的问题生成,主要将which问题转化为Is问题,从而简单一些:
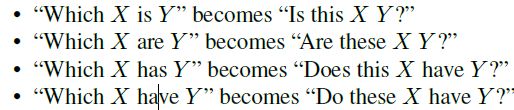
答案的设置:点在正确的bbox上,答案为yes,否则答案为no
接下来是数据集的统计:

人类的评估精度:在test数据集上91%
2、PointQA-General models
这次用3个模型做测试:MCAN、LXMERT、Pythia
后面就是三个模型分别描述了一下,这里我就不过多解读了;
最后比较了两种处理思路:

外加一种可选的结构:整合image-feat和point-feat到singal feature里面,成为双流。
3、PointQA-General evaluation
首先和之前一样,讲一下模型的设置,
第二部分是测试结果:
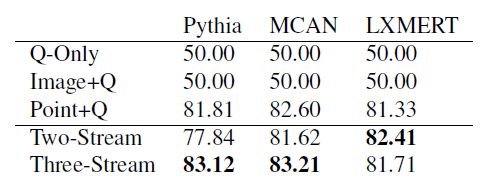
注意一下:在双流模型中,LXMERT表项最好,可能的原因之一是其pooling 策略
Using Image Context这个部分文中提及主要是问题不仅需要某个点,而且需要结合上下文才能回答。
重点是在这里:

重点在这里:三流模型牛皮的地方在于能有有效地整合范围更广的图像上下文。
七、结论
结论没讲啥,三句话结束,数据集+模型+期望。
八、附录部分
A. Human Evaluations
讲解了是怎么做的人类评估。三个人,每个人回答100个问题,3个数据集,所以900个答案。
剩下的A1、2、3是对三个数据集的分开说明,也就是为什么有些问题人类没有回答正确,这些进行一些原因分析。
最后分析一下结果的可信度。

总结
这是第一次看这种数据集的论文,该论文发表在CVPR VQA workshop上,又恰巧被我看到了,只能说是缘分。
近些年来在VQA数据集方面做得工作有很多,数据集也不少,像本文提出的这种作为拓展,怎么说呢,格局有点小了,xdmen,应该单独整个这种类别的数据集的。现在的模型需要的数据量辣么多,一堆人在刷分,头疼。