第七周作业:注意力机制的学习
文章目录
-
- 【BMVC2018】BAM: Bottleneck Attention Module
- 【CVPR2019】Dual Attention Network for Scene Segmentation
- 【CVPR2020】ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
- 【CVPR2020】Improving Convolutional Networks with Self-Calibrated Convolutions
- 【ARXIV2105】Pyramid Split Attention
- 【ARXIV2105】ResT: An Efficient Transformer for Visual Recognition
- 【ARXIV2105】Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.
【BMVC2018】BAM: Bottleneck Attention Module
论文: https://arxiv.org/pdf/1807.06514.pdf
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
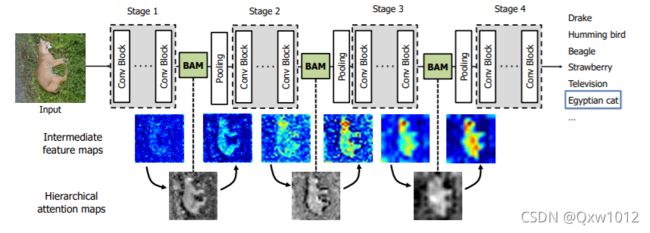
将BAM放在了Resnet网络中每个stage之间。。BAM在每个stage之间消除了像背景语义特征这样的低层次特征,然后逐渐聚焦于高级的语义–明确的目标(比如图中的狗)。

Feature map F {F} F进行全局平均池化得到,得到一个通道向量 F c ∈ R C × 1 × 1 \mathbf{F}_{\mathbf{c}} \in\mathbb{R}^{C \times 1 \times 1} Fc∈RC×1×1 ,然后使用了一个多层感知机(MLP)降维,再升维操作得到 C × 1 × 1 C×1×1 C×1×1。

众所周知利用上下文信息是了解空间位置的关键,重要的是要有一个大的感受野范围来有效地利用上下文信息。利用空洞卷积来高效地扩大感受野,而且在扩大感受野的同时,还不会增加参数量。
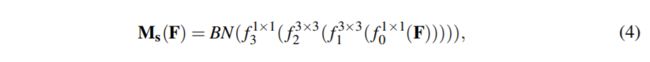
其中: f 表示卷积运算,BN表示批量归一化运算,上标表示卷积滤波器大小。 通道缩减有两个1×1 卷积。中间 3×3 扩张卷积用于聚合具有较大感受野的上下文信息。
![]()
这里 σ σ σ代表sigmoid函数,两个分支的形状在加和之前都会被整形成 R C ∗ H ∗ W \mathbb R^{ C ∗ H ∗ W} RC∗H∗W。通过expand_as函数。
『论文笔记』BAM:Bottleneck Attention Module(注意力机制)
【注意力机制】BAM: Bottleneck Attention Module论文理解
论文笔记(7):BAM: Bottleneck Attention Module
【CVPR2019】Dual Attention Network for Scene Segmentation
论文: https://arxiv.org/abs/1809.02983
代码: https://github.com/junfu1115/DANet
基础网络为dilated ResNet(与DeepLab相同),最后得到的feature map大小为输入图像的1/8。之后是两个并行的attention module分别捕获spatial和channel的依赖性,最后整合两个attention module的输出得到更好的特征表达。
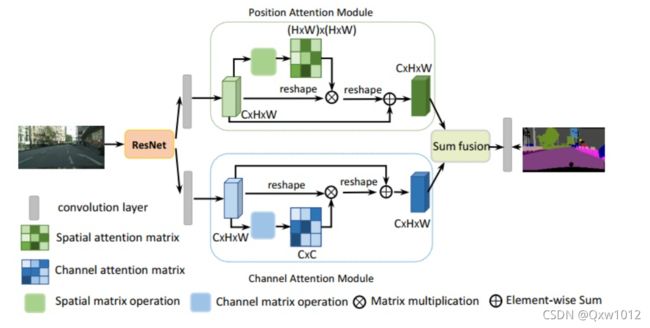
Position attention module:捕获特征图的任意两个位置之间的空间依赖,对于某个特定的特征,被所有位置上的特征加权和更新。权重为相应的两个位置之间的特征相似性。因此,任何两个现有相似特征的位置可以相互贡献提升,而不管它们之间的距离。

具体地,对于网络输出的局部特征A(CxHxW),首先利用三个卷积层后得到B,C,D三个特征map。
然后,对B,C,D分别reshape到(CxN),然后将B的转置与C相乘后,再通过softmax得到spatial attention map S(N,N)(N=H×W,所以,其实就建模了空间间的位置关系,可以理解成,将H×W拉伸为一维向量,通过N×N就建模了每一个位置,与其他位置的关系,然后通过softmax,得到值越大,说明这两个位置依赖性越强),接着,将S的转置与D矩阵乘后,将结果reshape到(CxHxW),乘以一个尺度因子后再加上原始输入图像得到最后的输出map E。
Channel attention module:捕获任意两个通道之间的相互依赖,利用所有通道的加权和更新某个通道的值。

先对A进行reshape到(CxN),然后A与A的转置进行矩阵乘,经过softmax后得到通道间的map X(CxC)(C×C建模了通道之间的关系,在通过softmax,值越大,说明两个通道之间的依赖性越强),之后再乘以A(CxN)得到的输出乘以尺度因子β后与原图相加后获得最后的输出E。
论文阅读-Dual Attention Network for Scene Segmentation
论文阅读 - Dual Attention Network for Scene Segmentation
Dual Attention Network for Scene Segmentation讲解
【CVPR2020】ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文: https://arxiv.org/abs/1910.03151
代码: https://github.com/BangguWu/ECANet
具体而言,给定输入特征,SE块首先为每个通道独立采用全局平均池化,然后使用两个全连接(FC)层以及非线性Sigmoid函数来生成通道权重。 两个FC层旨在捕获非线性跨通道交互,其中涉及降低维度以控制模型的复杂性。 尽管此策略在后续的通道注意力模块中被广泛使用,但我们的经验研究表明,降维会给通道注意力预测带来副作用,并且捕获所有通道之间的依存关系效率不高且不必要。
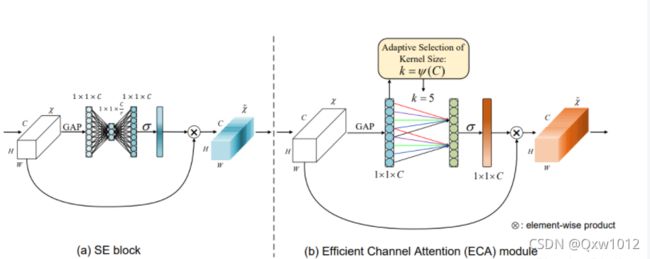
在不降低维度的情况下进行逐通道全局平均池化之后,我们的ECA通过考虑每个通道及其k个近邻来捕获本地跨通道交互。
ECANet
2020-CVPR-通道注意力超强改进-ECANet
VPR2020论文阅读——超强通道注意力模块ECANet
【CVPR2020】Improving Convolutional Networks with Self-Calibrated Convolutions
论文地址:
http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
代码地址:
https://github.com/MCG-NKU/SCNet
作者提出了一种自校正卷积(多个卷积注意力组合的模块),替换基本的卷积结构,在不增加额外参数和计算量的情况下,该卷积可以通过特征的内在通信达到扩增卷积感受野的目的,进而增强输出特征的多样性。
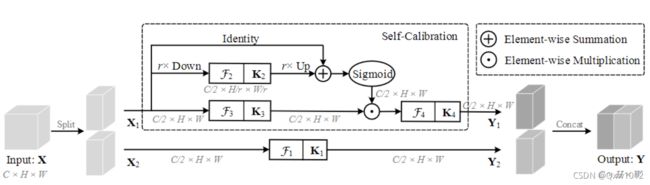
优点:
1.它使每个空间位置能够自适应地编码来自远程区域的信息上下文,说白了就是自适应增加了感受野。
2.SC模块通用性强,而且不会额外引入参数。
论文阅读:Improving Convolutional Networks with Self-calibrated Convolutions
Self-Calibrated Convolutions
CVPR2020 Improving Convolutional Networks with Self-Calibrated Convolutions论文详解 SC-Net 注意力机制
【ARXIV2105】Pyramid Split Attention
论文:https://arxiv.org/pdf/2105.14447v1.pdf
代码:https://github.com/murufeng/EPSANet
论文动机:
-
SE仅仅考虑了通道注意力,忽略了空间注意力。
-
BAM和CBAM考虑了通道注意力和空间注意力,但仍存在两个最重要的缺点:(1)没有捕获不同尺度的空间信息来丰富特征空间。(2)空间注意力仅仅考虑了局部区域的信息,而无法建立远距离的依赖。
-
后续出现的PyConv,Res2Net和HS-ResNet都用于解决CBAM的这两个缺点,但计算量太大。
PSA模块:
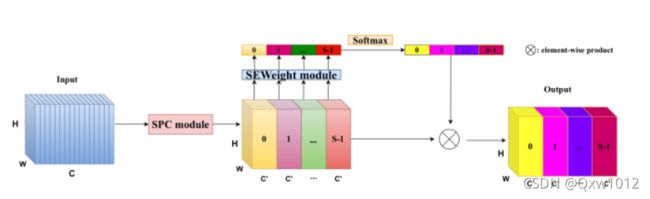
该模块分为以下四个步骤:
- 多尺度的特征图通过SPC模块得到
- SEWeight通过提取不同尺度特征图的注意力得到通道间的注意力向量
- 利用Softmax重新校准通道间的注意力向量
- 校准后的注意力向量与特征图操作后生成输出
SPC模块:

如上图所示,k0、k1、k2和k3是不同卷积核参数(以ESPANet-small为例,论文取3,5,7和9),G0、G1、G2和G3是分组卷积的参数(以ESPANet-small为例,论文默认取1,4,8和16)。整体可看做是模型采用不同卷积核提取多尺度目标特征,并采取Concat操作结合不同感受野下的多尺度特征。
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network(阅读分享)
Epsanet: An efficient pyramid split attention block on convolutional neural network阅读笔记
CVPR2021|一个高效的金字塔切分注意力模块PSA
【ARXIV2105】ResT: An Efficient Transformer for Visual Recognition
论文:https://arxiv.org/pdf/2105.13677v3.pdf
代码:https://github.com/wofmanaf/ResT
对于标准的Transformer,MSA有两个缺点:
(1)MSA尺度的计算是根据输入维度 d m d_m dm与 n n n的二次方计算的,导致训练和推理的开销巨大;
(2)MSA中的每一个head只负责输入的一个子集,这可能会损害网络的性能,特别是当每个子集中的通道维度 d k d_k dk太低时,使得Q和K的点积不能够构成一个信息匹配函数。
EMSA高效的多头自注意力模块

偷懒一下,直接截图相关博客内的解释。

ResT的总体结构与ResNet相似,都是有4个stage。每一个stage中有4部分组成,如下图所示。
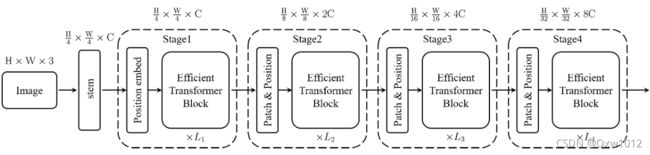
如上图所示,每个stage中的高效transformer模块在相同的尺度上运行(每个stage中都有不止一个Efficient Transformer Block,每个Block都在相同的尺度上运行),在通道和空间维度上具有相同的分辨率。(*例如第一个Stage特征图的大小始终是H/4 * W/4 C)因此,需要patch embed模块逐步扩展通道维度,同时降低整个网络的空间分辨率。
ResT:用于图像识别的高效Transformer
南京大学提出ResT:用于视觉识别的高效Transformer
ResT: An Efficient Transformer for Visual Recognition
【ARXIV2105】Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.
论文链接:https://arxiv.org/abs/2105.02358
代码:https://github.com/MenghaoGuo/-EANet
Self-attention自身存在两个缺点:
(1)计算量太大,计算复杂度与pixel的平方相关;
(2)没有考虑不同样本之间的潜在关联,只是单独处理每一个样本,在单个样本内去捕获这类长距离依赖。例如,属于同一类别但分布在不同样本中的特征应该得到一致的处理。
相比自注意力机制,外部注意力中的Key与Value被拿到了外部,不再由特征投射产生。这种结构使得外部的记忆单元可以习得整个数据集样本的统计特征。使用两个线性单元作为外部注意力的记忆单元则简化了运算复杂度。


其中 M 是为一个与输入无关的可学习参数,作为数据集相关的记忆器。A是利用学习到的记忆推理出的attention map;在feature map和 M线性变换后要经过一个不太一样的Norm。在实际中,作者利用了两个这样的memory unit —— M k M_k Mk 和 M v M_v Mv,作为key和value,来增加网络的性能。
此时的计算复杂度为O(dSN),其中d与S为超参数,实际发现S取值为64就可以得到不错的效果。该方法计算量与像素数量呈现线性关系,相比自注意力机制在输入尺寸较大时效率更高。
外部注意力机制
《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks - 1 - 论文学习
后续论文还在更新中