深度学习 | 超参数(Hyperparameters)(4.4)| 上
最近在恶补深度学习基础知识,以下为根据公众号“ 阿力阿哩哩”的《超参数(Hyperparameters)| 上》而总结的内容。可以结合作者在哔哩大学的视频。

4.4 超参数(Hyperparameters)
经过4.3节的CNN卷积神经网络原理的讲解,笔者相信大家已经迫不及待地想建属于自己的神经网络来训练了。不过,在此之前,笔者还是有一些东西要给大家介绍的。那就是神经网络的超参数(Hyperparameters),记忆力好的读者会发现笔者在上一节中就有提及超参数。
不过,本节介绍的超参数与往期不同,它是所有网络共有的超参数,也就是说我们不管搭建什么网络,都可以对这些超参数进行设置。不像4.3节介绍的CNN卷积神经网络,它的一些特有超参数如Padding,是其他网络并不具备的。最后,对于超参数的定义,通俗易懂来讲就是大家在训练神经网络前必须人工设定的参数。
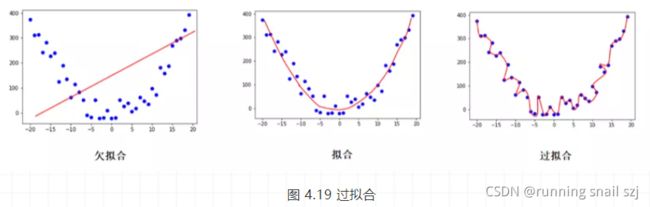
4.4.1 过拟合
在此之前,笔者先给大家科普一下什么是过拟合。
举个最简单的例子,大家一般在考试前都会通过做题来复习,假如我们当晚做的题都在第二天考场上见到了,那么咱们的分数就会高很多,但是其实出别的题目,大家可能就答不上来了,这时候我们就把这种情况叫过拟合,因为大家只是记住了一些题目的特征,但是并没有很好地了解题目最本质的真理。
这时候笔者顺带给大家科普一下泛化性。泛化就像学神考试,不管他当晚有没有复习到第二天考试的题目,依旧能拿高分,因为学神已经将所有题目最本质的真理都学会了,所以不管出什么题目他都能通过已经掌握的真理去解答,这就是泛化。
那我们训练模型也一样,当然希望我们训练出来的模型能和学神一般,不管碰到什么题目都能迎刃而解,而不是像学渣碰运气,全靠当晚临时抱佛脚。所以为了保证我们模型的泛化性,我们可以通过一些手段去避免过拟合,进而避免我们的模型在努力学习数据的本质规律时误入歧途当了学渣。
下面笔者就给大家一一剖析神经网络是如何通过下面两种手段去应对过拟合现象的,不过在此之前,笔者依惯例给大家上一张过拟合的图片让大家对过拟合有个直观的理解。
1. 正则化(Regularization)
正则化有好几种,这里笔者主要介绍L1与L2两种正则化,其他正则化与它们只是形式上有所区别,但它们的数学核心思想都是一样的。说到正则化,难免逃不开数学公式,L1与L2正则化的公式如式(4.28)~(4.29)所示。
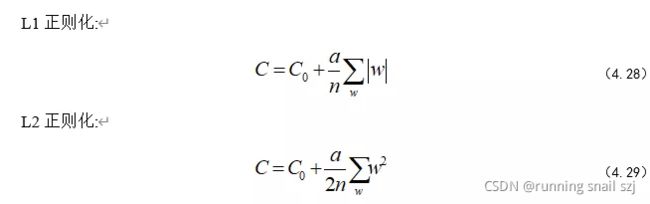
好了,这时候我们先认识一下公式里面的参数,C0与笔者之前提及的损失 Loss是一个东西,不过今天的主角并不是它,而是这个权值累加项a/n ∑w|w| 。C就是当前神经网络的损失,由之前Loss(C0)和这个权值累加项组成。
看着这个公式,大家兴许并没有啥感觉,这时候大家可以回忆下笔者刚刚说的学神与学渣的故事。学神为什么这么强?因为他掌握了题目最本质的真理,这个真理比学渣通过做很多重复的题目来记住题目本身要高效得多。那我们的模型要想跟学神一样强,那就必须得大道至简,掌握数据规律中最基本的真理。
好了,说到这,我们又可以看下公式了,公式有个对权重的累加部分,那我们设想下权重越大,越多,那损失C是不是越大,像不像当年为了考高分疯狂背题的大家?是的,权值越多,越大说明我们花费了很多时间和精力去记住某个题目的特征,而忽略了题目本身的真理。
现在加入这一个权值累加项,就是为了让我们时时刻刻在计算自己的损失,我们知道神经 网络的训练是通过梯度下降不断减小损失C的过程,那么加上这一项就可以有“意识”地避开增大w的方向去行走。
那我们可以将式子中的a理解为惩罚因子。如果我们对下面这个部分越重视,那我们就加大a,迫使它向权值w减小的方向快速移动。
到现在为止,大家应该明白了正则化的目的就是为了模型的泛化而添加的一个权值累加项。那接下来笔者就给大家介绍下L1和L2的区别。现在大家又可以看一下L1和L2的式子了,L1是绝对值,L2是平方,以此类推可以知道L3、L4等等正则项也是这么来的。L2前面加的那个1/2只是为了求导的时候好约分,可以说算是一个计算技巧。
现在笔者给大家附上一个对比图,如图 4.20所示,让大家对两个正则化公式有个直观的了解。
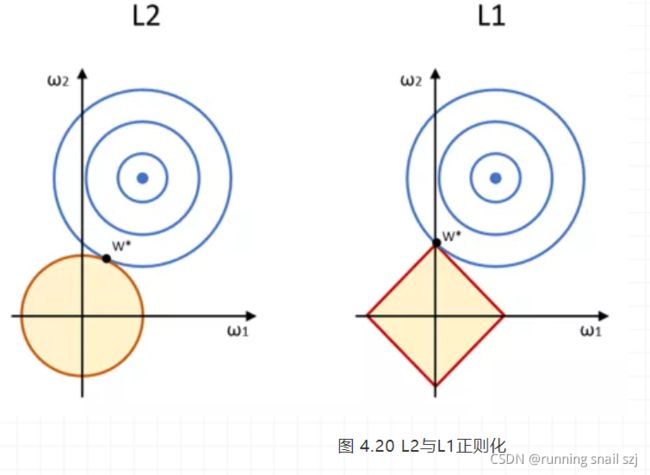
在只考虑二维情况下,我们在(w1, w2)的权值平面上可视化代价函数Loss的求解过程,圆心为样本值,半径是误差,红色的边界是正则项的约束条件(权值累加项),两者相交则是整个代价函数Loss的最优解。
大家可以将整个求解的过程理解为在让w1、w2最小的情况下,让样本与正则项(L1 或者 L2的权值累加项)相交得到最优解。
我们可以看到的是L2比较圆润(二次项),L1则是方块比较尖(一次绝对值),这样L2与样本相交的时候,最优解(w1, w2)都是有值的,而L1与样本相交得到的最优解(w1, w2)其中w1=0。
所以,L1倾向于更少的特征,其他特征为0,而L2倾向于更多的特征,每个特征都有值。这只是二维情况下,如果在三维甚至更高维度,大家也可以想象L1为棱角分明的尖物体,而L2为圆润的物体,这样他们与高维的样本相交的时候,生成的最优解也和二维情况一样。而且本质上也符合上面正则化项(权值累加项)的约束:尽可能让权值更小与更少,这样我们得到模型泛化性越强。
2. Dropout
可能有些大家会说,正则化只是让权值w变小,并没有让权值w的数量减少,因为当整个网络结构确定下来的时候,权值w的数量就已经确定了,而正则化并不能去改变网络结构。这时候Dropout就登场了,我们在每一轮训练过程中随机放弃一些神经元节点,这样我们一定程度上就相当于减少了权值数量,用更少的权值数量去训练网络,相当于我们用最高效的方法去掌握多的题目,本质上就是加强模型泛化性的过程。
依惯例,这里附上一个Dropout示意图,如图 4.21所示,让大家有个直观的感受。

4.4.2 优化器(Optimizer)
在之前的学习中,大家了解到了整个网络的训练都是基于梯度下降法去训练的,但是当数据量多的时候,梯度下降法训练就会非常的慢,因为我们每一轮训练都会对所有数据求梯度。为此,有一些人就对梯度下降提出了优化方法,也就是笔者即将介绍的优化器。
1. 随机梯度下降Stochastic Gradient Decent(SGD)
梯度下降法每次训练都用全部样本,然而这些计算是冗余的,因为我们每次都用同样的样本去计算。而随机梯度下降法(SGD)为此做了些许改变,每次只选择一个样本来更新来更新梯度,这样学习速度肯定非常的快,并且支持对新的数据进行在线更新,如图 4.22所示。
当然了,我们为了速度快,理所应当的要付出一些代价,不像梯度下降法那样每次更新都会朝着Loss不断减小的方向去移动,最后收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点),SGD由于每次选择样本的随机性,会有些许波动,也就是下图的SGD收敛示意图,走的路会比较曲折,有时候会从一个点突然跳到另外一个点去,不过这样也有好处,因为对于非凸Loss函数,我们用梯度下降法很可能收敛在在局部极值点就不动了,但是SGD却能用它的随机选择样本更新梯度的特性跳出局部极值点,很可能在非凸Loss函数中找到全局极值点。

2. Momentum
我们知道了SGD的缺点,为了解决它的波动性,有人在SGD的基础上又添加了点东西,从而抑制SGD的震荡。这个东西就是动量,我们先看下Momentum的公式如(4.30)~(4.31)所示。

我们通过添加γv(t-1)这项,让随机梯度下降拥有了动量,这时候大家要回忆一下高中物理了,动量是具有惯性的,也就是我们在下山过程中,即使随机走路,但是受限于惯性,我们不可能随便跳来跳去,从而抑制了SGD在梯度下降过程中震荡,为此笔者在这附上一张图,如图 4.23所示,让大家有个更直观的理解。

从图 4.24我们就可以看出,加入了动量抑制了震荡,走的路至少不这么曲折了,这个方法就是Momentum。
3. RMSprop
熟悉TensorFlow或者Keras调参的读者可能会觉得学习率(Learning Rate)调参是个比较麻烦的事,为此,自适应的学习率调参方法就出现了,目的是为了减少人工调参的次数(只是减少次数,还是需要人工设定学习率的)。RMSprop就是其中一个比较优秀的自适应学习率方法,如公式(4.32)~(4.33)所示:

RMSprop使用的是指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。允许使用一个更大的学习率η。
4. Adaptive Moment Estimation(Adam)
现在我们讲最后一个优化器:Adam优化器:它相当于RMSprop + Momentum,也就是拥有了这两者的优点,因此笔者在很多优秀的论文都能看到它被用来做神经网络的优化器。所以,如果不知道如何选择优化器,那就选Adam优化器吧!
4.4.3 学习率(Learning Rate)
有些细心的读者会发现笔者在之前的全连接神经网络章节中已经提及了学习率,这里再一次提及只是为了让整个超参数知识体系更加的完整,避免大家知一不知二。首先梯度下降更新权值如公式(4.34)所示。
![]()
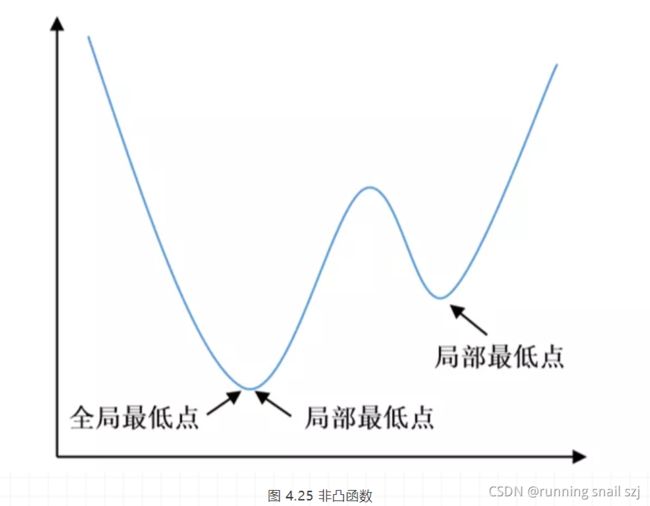
我们知道整个训练过程就是梯度下降更新权值的过程,对于学习率的作用,大家可以通过上面的公式以及图 4.25可以明白,对于凸函数,大的学习率可能会在学习过程中跳过全局极值点,小的虽然速度慢但是最终能收敛到全局极值点,求得最优解。
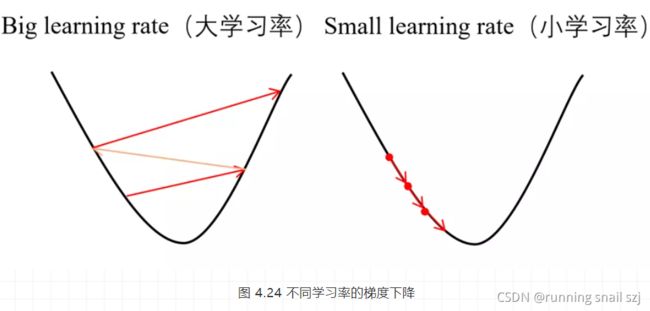
但是对于非凸函数,它可能存在许多局部最小值,大家使用较小的学习率去训练的时候,很可能让整个网络收敛于局部最小值而不是全局最小值,从而得不到最优解。
可能有些读者还不了解什么是非凸函数。如图 4.25所示,它就是存在局部最低点的一个函数,但局部最低点并不一定是全局最低点。
说到这,那我们应该怎么去选择学习率呢?目前业界并没有很好的方法,大家可以通过自己调参去将学习率调到最优即可。
下一期,我们将继续介绍
神经网络的超参数(Hyperparameters)
敬请期待~