DSSM、YoutubeDNN-推荐系统小结
DSSM、YoutubeDNN-推荐系统小结
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。
1.经典双塔模型:DSSM
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。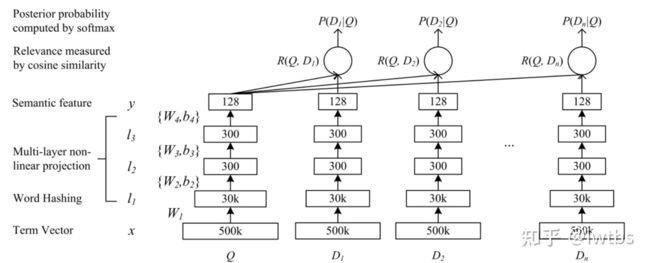
该网络结构比较简单,是一个由几层DNN组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 query 和 document 之间相似分数,然后在做 softmax。
而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题
需要注意的是:对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:
其中s*(x,y)表示两个向量的相似度,P(y∣x;θ)表示预测类别的概率,M表示物料库所有的item。但是在实际场景中,由于物料库中的item数量巨大,在计算上式时会十分的耗时,因此会采样一定的数量的负样本来近似计算。
以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,在一定程度上牺牲掉模型的部分精准性。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。
1.1双塔模型细节
1.1.1归一化与温度系数
在Google的双塔召回模型中,重点介绍了两个trick,将user和item侧输出的embedding进行归一化以及对于內积值除以温度系数,实验证明这两种方式可以取得十分好的效果。那为什么这两种方法会使得模型的效果更好呢?
-
归一化:对user侧和item侧的输入embedding,进行L2归一化
u ( x , θ ) ← = u ( x , θ ) ∣ ∣ u ( x , θ ) ∣ ∣ 2 u(x,\theta) \leftarrow = \frac{u(x,\theta)}{||u(x,\theta)||_2} u(x,θ)←=∣∣u(x,θ)∣∣2u(x,θ)
v ( x , θ ) ← = v ( x , θ ) ∣ ∣ v ( x , θ ) ∣ ∣ 2 v(x,\theta) \leftarrow = \frac{v(x,\theta)}{||v(x,\theta)||_2} v(x,θ)←=∣∣v(x,θ)∣∣2v(x,θ)
-
温度系数:在归一化之后的向量计算內积之后,除以一个固定的超参 r r r ,论文中命名为温度系数。
s ( u , v ) = < u ( x , θ ) , v ( x , θ ) > r s(u,v) = \frac{
那为什么需要进行上述的两个操作呢?
-
归一化的操作主要原因是因为向量点积距离是非度量空间,不满足三角不等式,而归一化的操作使得点击行为转化成了欧式距离。
首先向量点积是向量对应位相乘并求和,即向量內积。而向量內积不保序,例如空间上三个点(A=(10,0),B=(0,10),C=(11,0)),利用向量点积计算的距离 dis(A,B) < dis(A,C),但是在欧式距离下这是错误的。而归一化的操作则会让向量点积转化为欧式距离,例如 u s e r e m b user_{emb} useremb 表示归一化user的embedding, i t e m e m b item_{emb} itememb 表示归一化 item 的embedding,那么两者之间的欧式距离 ∣ ∣ u s e r e m b − i t e m e m b ∣ ∣ ||user_{emb} - item_{emb}|| ∣∣useremb−itememb∣∣ 如下, 可以看出归一化的向量点积已转化成了欧式距离。
∣ ∣ u s e r e m b − i t e m e m b ∣ ∣ = ∣ ∣ u s e r e m b ∣ ∣ 2 + ∣ ∣ i t e m e m b ∣ ∣ 2 − 2 < u s e r e m b , i t e m e m b > = 2 − 2 < u s e r e m b , i t e m e m b > ||user_{emb} - item_{emb}||=\sqrt{||user_{emb}||^2+||item_{emb}||^2-2
那没啥非要转为欧式距离呢?这是因为ANN一般是通过计算欧式距离进行检索,这样转化成欧式空间,保证训练和检索一致。
1.1.2模型的应用
在实际的工业应用场景中,分为离线训练和在线服务两个环节。
- 在离线训练阶段,同过训练数据,训练好模型参数。然后将候选库中所有的item集合离线计算得到对应的embedding,并存储进ANN检索系统,比如faiss。为什么将离线计算item集合,主要是因为item的会相对稳定,不会频繁的变动,而对于用户而言,如果将用户行为作为user侧的输入,那么user的embedding会随着用户行为的发生而不断变化,因此对于user侧的embedding需要实时的计算。
- 在线服务阶段,正是因为用户的行为变化需要被即使的反应在用户的embedding中,以更快的反应用户当前的兴趣,即可以实时地体现用户即时兴趣的变化。因此在线服务阶段需要实时的通过拼接用户特征,输入到user侧的DNN当中,进而得到user embedding,在通过user embedding去 faiss中进行ANN检索,召回最相似的K个item embedding。
可以看到双塔模型结构十分的适合实际的应用场景,在快速服务的同时,还可以更快的反应用户即时兴趣的变化。
1.1.3负样本采样
相比于排序模型而言,召回阶段的模型除了在结构上的不同,在样本选择方面也存在着很大的差异,可以说样本的选择很大程度上会影响召回模型的效果。对于召回模型而言,其负样本并不能和排序模型一样只使用展现未点击样本,因为召回模型在线上面临的数据分布是全部的item,而不仅仅是展现未点击样本。因此在离线训练时,需要让其保证和线上分布尽可能一致,所以在负样本的选择样要尽可能的增加很多未被曝光的item。
全局随机采样 + 热门打压
针对于全局随机采样的不足,一个直观的方法是针对于item的热度item进行打压,即对于热门的item很多用户可能会点击,需要进行一定程度的欠采样,使得模型更加关注一些非热门的item。 此外在进行负样本采样时,应该对一些热门item进行适当的过采样,这可以尽可能的让模型对于负样本有更加细粒度的区分。例如在word2vec中,负采样方法是根据word的频率,对 negative words进行随机抽样,降 低 negative words 量级。
之所以热门item做负样本时,要适当过采样,增加负样本难度。因为对于全量的item,模型可以轻易的区分一些和用户兴趣差异性很大的item,难点在于很难区分一些和用户兴趣相似的item。因此在训练模型时,需要适当的增加一些难以区分的负样本来提升模型面对相似item的分区能力。
Hard Negative增强样本
Hard Negative指的是选取一部分匹配度适中的item,能够增加模型在训练时的难度,提升模型能学习到item之间细粒度上的差异。至于 如何选取在工业界也有很多的解决方案。
例如Airbnb根据业务逻辑来采样一些hard negative (增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性;增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,),详细内容可以查看原文
例如百度和facebook依靠模型自己来挖掘Hard Negative,都是用上一版本的召回模型筛选出"没那么相似"的
Batch内随机选择负采样
基于batch的负采样方法是将batch内选择除了正样本之外的其它Item,做为负样本,其本质就是利用其他样本的正样本随机采样作为自己的负样本。这样的方法可以作为负样本的选择方式,特别是在如今分布式训练以及增量训练的场景中是一个非常值得一试的方法。但这种方法也存在他的问题,基于batch的负采样方法受batch的影响很大,当batch的分布与整体的分布差异很大时就会出现问题,同时batch内负采样也会受到热门item的影响,需要考虑打压热门item的问题。至于解决的办法,Google的双塔召回模型中给出了答案,想了解的同学可以去学习一下。
总的来说负样本的采样方法,不光是双塔模型应该重视的工作,而是所有召回模型都应该仔细考虑的方法。
1.2DSSM模型的优缺点
先说说DSSM模型的优点:
- 解决了LSA、LDA、Autoencoder等方法存在的字典爆炸问题,从而降低了计算复杂度。因为英文中词的数量要远远高于字母n-gram的数量;
- 中文方面使用字作为最细切分粒度,可以复用每个字表达的语义,减少分词的依赖,从而提高模型的泛化能力;
- 字母的n-gram可以更好的处理新词,具有较强的鲁棒性;
- 使用有监督的方法,优化语义embedding的映射问题;
- 省去了人工特征工程;
- 采用有监督训练,精度较高。传统的输入层使用embedding的方式(比如Word2vec的词向量)或者主题模型的方式(比如LDA的主题向量)做词映射,再把各个词的向量拼接或者累加起来。由于Word2vec和LDA都是无监督训练,会给模型引入误差。
再说说DSSM模型的缺点:
- Word Hashing可能造成词语冲突;
- 采用词袋模型,损失了上下文语序信息。这也是后面会有CNN-DSSM、LSTM-DSSM等DSSM模型变种的原因;
- 搜索引擎的排序由多种因素决定,用户点击时doc排名越靠前越容易被点击,仅用点击来判断正负样本,产生的噪声较大,模型难以收敛;
- 效果不可控。因为是端到端模型,好处是省去了人工特征工程,但是也带来了端到端模型效果不可控的问题。
funrec代码(数据处理、模型、ANN):https://datawhalechina.github.io/fun-rec/#/ch02/ch2.1/ch2.1.2/DSSM
2.YouTubeDNN
YouTubeDNN模型是2016年的一篇文章,虽然离着现在有些久远, 但这篇文章无疑是工业界论文的典范, 完全是从工业界的角度去思考如何去做好一个推荐系统,这篇文章给出了很多优化推荐系统中的工程性经验, 不管是召回还是排序上,都有很多的套路或者trick,比如召回方面的"example age", “负采样”,“非对称消费,防止泄露”,排序方面的特征工程,加权逻辑回归等, 这些东西至今也都非常的实用,所以这也是这篇文章厉害的地方。
三大挑战:
1.Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统,文中体现这一点的是召回模型线下训练的时候,采用了负采样的思路,线上服务的时候,采用了hash映射,然后近邻检索的方式来满足实时性的需求
2.Freshness(新鲜度):用户一般都比较喜欢看比较新的视频, 而不管是不是真和用户相关(这个感觉和新闻比较类似呀), 这时候,就需要模型有建模新上传内容以及用户最新发生的行为能力。 为了让模型学习到用户对新视频有偏好, 后面策略里面加了一个"example age"作为体现。
3.Noise(噪声): 由于数据的稀疏和不可见的其他原因, 数据里面的噪声非常之多,这时候,就需要让这个推荐系统变得鲁棒,怎么鲁棒呢? 这个涉及到召回和排序两块,召回上需要考虑更多实际因素,比如非对称消费特性,高活用户因素,时间因素,序列因素等,并采取了相应的措施, 而排序上做更加细致的特征工程, 尽量的刻画出用户兴趣以及视频的特征 优化训练目标,使用加权的逻辑回归等。
2.1YouTubeDNN推荐系统架构

论文把推荐问题转换为一个多分类问题:根据用户 U 和上下文 C,预测在时刻 t 观看视频 i 的概率。
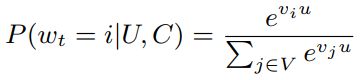
式子中,u 指的是用户 U 和上下文 C 的 Embedding,v 指的是候选视频项目的 Embedding。深度学习的任务是学习一个函数(参数估计),怎么根据用户的历史记录和上下文生成当前的 Embedding。
另外,YouTube 不使用点赞等用户显式反馈作为用户满意度的信号,而是使用用户是否观看完视频的隐式反馈作为用户满意度信号。因为后者有更多的可用数据(很多视频用户感兴趣,看完了,但因为一些原因不愿点赞),前者的数据稀疏性较为严重。
2.2召回模型特征
Example Age
这个特征单独拿出来说,是因为这个是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)
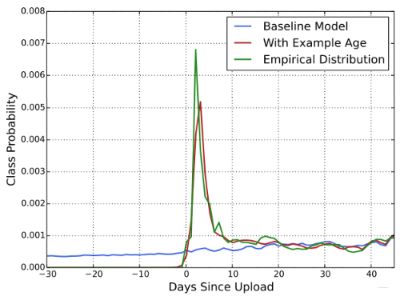
但是我们模型训练的时候,是基于历史数据训练的(历史观看记录的平均),所以模型对播放某个视频预测值的期望会倾向于其在训练数据时间内的平均播放概率(平均热度), 上图中蓝色线。但如上面绿色线,实际上该视频在训练数据时间窗口内热度很可能不均匀, 用户本身就喜欢新上传的内容。 所以,为了让模型学习到用户这种对新颖内容的bias, 作者引入了"example age"这个特征来捕捉视频的生命周期。
"example age"定义为 t m a x − t t_{max}-t tmax−t, 其中 t m a x t_{max} tmax是训练数据中所有样本的时间最大值(有的文章说是当前时间,但我总觉得还是选取的训练数据所在时间段的右端点时间比较合适,就比如我用的数据集, 最晚时间是2021年7月的,总不能用现在的时间吧), 而 t t t为当前样本的时间。线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了。
训练集预处理过程中,没有采用原始的用户日志,而是对每个用户提取等数量的训练样本
这是为了达到样本均衡减少高度活跃用户对于loss的过度影响。
完全摒弃了用户观看历史的时序特征,把用户最近的浏览历史等同看待
这个原因应该是YouTube工程师的“经验之谈”,如果过多考虑时序的影响,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。YouTube给出一个例子,如果用户刚搜索过“tayer swift”,你就把用户主页的推荐结果大部分变成tayer swift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。
2.3YouTubeDNN工业经验:
- 训练数据的样本来源应该是全部物料, 而不仅仅是被推荐的物料,否则对于新物料难以曝光
- 训练数据中对于每个用户选取相同的样本数, 保证用户在损失函数等权重, 这个虽然不一定非得这么做,但考虑打压高活用户或者是高活item的影响还是必须的
- 序列无序化: 用户的最近一次搜索与搜索之后的播放行为有很强关联,为了避免信息泄露,将搜索行为顺序打乱。
- 训练数据构造: 预测接下来播放而不是用传统cbow中的两侧预测中间的考虑是可以防止信息泄露,并且可以学习到用户的非对称视频消费模式
- 召回模型中,类似word2vec,video 有input embedding和output embedding两组embedding,并不是共享的, input embedding论文里面是用w2v事先训练好的, 其实也可以用embedding层联合训练
- 召回模型的用户embedding来自网络输出, 而video的embedding往往用后面output处的
- 使用
example age特征处理 time bias,这样线上检索时可以预先计算好用户向量
参考资料:
funrec代码:https://datawhalechina.github.io/fun-rec/#/ch02/ch2.1/ch2.1.2/YoutubeDNN
相关论文:
面output处的
7. 使用 example age 特征处理 time bias,这样线上检索时可以预先计算好用户向量
参考资料:
funrec代码:https://datawhalechina.github.io/fun-rec/#/ch02/ch2.1/ch2.1.2/YoutubeDNN
#相关论文