网络程序设计课程项目学习总结-SA1622120-姜天
网络程序设计课程项目学习总结-SA1622120-姜天
1.学习心得总结
第一节课当孟老师介绍完本学期的课程内容后,我就被深深的吸引了。虽然自己对神经网络机器学习这领域的了解是完全空白的,老师也在第一堂课劝退了很多同学,但是我觉得来到软院就是为了锻炼自己,总是接触自己以前熟悉的东西非常的无趣。并且机器学习的内容现在非常的火,这是个非常好的入门机会,而且高级软件工程这课对孟老师的印象非常好,就毅然决然的留下来了。
自己以前从未接触课程相关的框架和算法,python语言也是从未使用过,所以课程的大多数时间都在学习,并没有能够对工程做出突出的贡献,但是有非常认真的去学习框架语言和研究算法,收获颇丰。同班的同学里大神非常多,每次上课听着同学们的分享和讨论总是能学到很多,不得不说孟老师营造的团队氛围非常的棒,让大家能够非常高效地进行学习和讨论。
在课程快结束的俩周,项目的版本逐渐定型,自己的学习也由浅入深,逐渐有了自己的想法,便开始把自己关于微信公众号的工程实践内容与这次的课程项目相结合,并且取得了成功,虽然还有些bug,但是相信在课程结束后加以调试,会快解决这些问题。
总的来讲,这次技术上的收获是入门了机器学习的领域,并且了解了相关的框架和算法。但更大的收获是学会了分享,第一次有了团队的感觉,本科期间也有过和同学合作,但是很难有1+1>2的效果,而这次班里同学互相帮助互相学习,各自有各自的分工,即使我的基础很差,最后也有了自己的突破,非常开心。非常感谢老师给了这样的学习环境,希望以后多参与这样的团队合作中,不断地提升自己。
2.项目介绍
2.1概要
1) 神经网络实现手写字符识别系统
使用带标签的手写字符数据训练一个神经网络模型,并使用BP反向传播算法对参数进行校正,最终建立一个手写字符训练模型。用户可以在web端的canvas画布上手写数字,当点击Test的时候,就会将该手写字符数据传输到训练模型中,然后返回其预测值;当点击Train的时候,就可以根据人提供的真实数据进行训练。
2)基于机器学习神经网络的一个医学辅助诊断系统
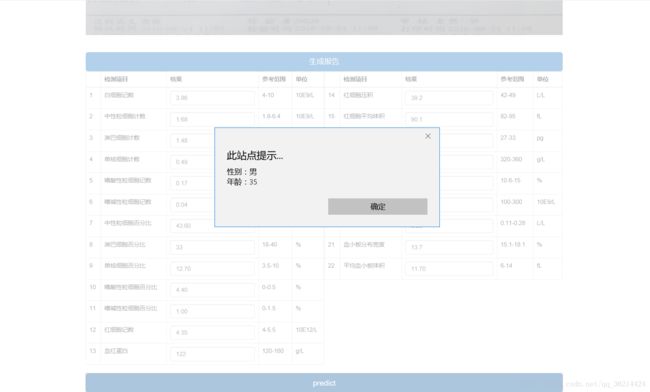
通过对病人血常规化验单的图片的识别采集数据进行分析。利用通过大量真实数据训练出来的有一定可接受的准确率的模型对病人所提供的数据进行判断,通过对各项血常规数据的分析来实现对病人性别和年龄的预测。
3)自己的版本库地址:https://coding.net/u/Lapland/p/np2016/git
2.2环境配置
1)安装前置依赖
get install python2.7-dev python3.2 python3.2-dev
#安装 Python 发布版本,dev包必须安装,很多用pip安装包都需要编译
sudo apt-get install build-essential libssl-dev libevent-dev libjpeg-dev libxml2-dev libxslt-dev
# 很多pip安装的包都需要libssl和libevent编译环境
2)安装python模块
pip sudo apt-get install python-pip
# 安装numpy,
sudo apt-get install python-numpy # http://www.numpy.org/
# 安装opencv
sudo apt-get install python-opencv # http://opencv.org/
#装完后需要更新环境变量
vim /etc/bash.bashrc
#在文件末尾添加两行代码
export PYTHONPATH=$PYTHONPATH:/usr/local/lib/python2.7/dist-packages
export PYTHONPATH="${PYTHONPATH+${PYTHONPATH}:}/usr/local/lib/python2.7/site-packages"
##安装OCR和预处理相关依赖
sudo apt-get install tesseract-ocr
sudo pip install pytesseract
sudo apt-get install python-tk
sudo pip install pillow
# 安装Flask框架、mongo
sudo pip install Flask
sudo apt-get install mongodb # 如果找不到可以先sudo apt-get update
sudo service mongodb started
sudo pip install pymongo
3)安装opencv
sudo apt-get install python-opencv # http://opencv.org/4)安装tensorflow
pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl5)运行demo
cd BloodTestReportOCR
python view.py # upload图像,在浏览器打开http://yourip:80802.3文件简介
1)view.py
Web 端上传图片到服务器,存入mongodb并获取oid
2)imageFilter.py
对图像透视裁剪和OCR进行了简单的封装,以便于模块间的交互,规定适当的接口
3)ocr函数 - 模块主函数返回识别数据
用于对img进行ocr识别,他会先进行剪切,之后进一步做ocr识别,返回一个json对象 如果剪切失败,则返回None @num 规定剪切项目数
4)perspect函数做 - 初步的矫正图片
用于透视image,他会缓存一个透视后的opencv numpy矩阵,并返回该矩阵 透视失败,则会返回None,并打印不是报告 @param 透视参数
关于param
参数的形式为[p1, p2, p3 ,p4 ,p5]。 p1,p2,p3,p4,p5都是整型,其中p1必须是奇数。
p1是高斯模糊的参数,p2和p3是canny边缘检测的高低阈值,p4和p5是和筛选有关的乘数。
如果化验报告单放在桌子上时,有的边缘会稍微翘起,产生比较明显的阴影,这种阴影有可能被识别出来,导致定位失败。 解决的方法是调整p2和p3,来将阴影线筛选掉。但是如果将p2和p3调的比较高,就会导致其他图里的黑线也被筛选掉了。 参数的选择是一个问题。 我在getinfo.default中设置的是一个较低的阈值,p2=70,p3=30,这个阈值不会屏蔽阴影线。 如果改为p2=70,p3=50则可以屏蔽,但是会导致其他图片识别困难。
就现在来看,得到较好结果的前提主要有三个:
化验单尽量平整
图片中应该包含全部的三条黑线
图片尽量不要包含化验单的边缘,如果有的话,请尽量避开有阴影的边缘。
5)filter函数 - 过滤掉不合格的或非报告图片
返回img经过透视过后的PIL格式的Image对象,如果缓存中有PerspectivImg则直接使用,没有先进行透视 过滤失败则返回None @param filter参数
6)autocut函数 - 将图片中性别、年龄、日期和各项目名称数据分别剪切出来
用于剪切ImageFilter中的img成员,剪切之后临时图片保存在out_path, 如果剪切失败,返回-1,成功返回0 @num 剪切项目数 @param 剪切参数
剪切出来的图片在BloodTestReportOCR/temp_pics/ 文件夹下
函数输出为data0.jpg,data1.jpg……等一系列图片,分别是白细胞计数,中性粒细胞记数等的数值的图片。
7)classifier.py
用于判定裁剪矫正后的报告和裁剪出检测项目的编号
8)imgproc.py
将识别的图像进行处理二值化等操作,提高识别率 包括对中文和数字的处理
9)digits
将该文件替换Tesseract-OCR\tessdata\configs中的digits
3.个人工作
3.1概述
因为自己的工程实践的内容是做一个微信公众号的开发,于是在这次的课程中,我也尝试了将微信公众号作为平台代替网页来开发我们这个项目。之前用的是meteor,但是meteor是基于js的平台,不支持python,所以我自己在网上学习了用python搭建一个微信公众号服务器。具体实现步骤如下:
①配置公众号接口,用python搭建服务器接收处理数据,py文件存放于np2016-master\BloodTestReportOCR\下
②客户发送样本图片,服务器接收到微信服务器发送的post请求,用web框架的web.data()获取发送的xml数据包。
③根据文档内容,获取的xml数据包中的PicUrl数据为客户端发送的图片的url,用etree.fromstring(str_xml).find(‘PicUrl’).text提取出图片url
④根据图片url,用lxml框架对网页进行解析,通过lxml的urlopen获取url对象,然后用urlopen.read()提取出图片并转化为可处理的数据。
⑤使用view.py中ImageFilter.ocr的方法对提取出的图片进行预处理矫正并识别图中数据。
⑥使用tf_predict.py对识别出的数据进行预测,并将结果通过模板消息发给微信服务器。
⑦客户端显示模板消息,得知预测结果。
3.2关键部分代码
def POST(self):
str_xml = web.data()
xml = etree.fromstring(str_xml)
msgType = xml.find("MsgType").text
fromUser = xml.find("FromUserName").text
toUser = xml.find("ToUserName").text
res = '请输入图片'
if msgType == 'image':
print('gali')
url = xml.find('PicUrl').text
img = cv2.imdecode(numpy.fromstring(urllib2.urlopen(url).read(), numpy.uint8), cv2.CV_LOAD_IMAGE_UNCHANGED)
data = ImageFilter(image=img).ocr(22)
if data:
data = json.loads(data)
pre = [str(data['bloodtest'][i]['value']) for i in range(22)]
for i in range(22):
if pre[i] == '': pre[i] = 0
else:
tmp = pre[i].replace('.', '', pre[i].count('.')-1)
pre[i] = float(tmp)
arr = numpy.array(pre)
arr = numpy.reshape(arr, [1, 22])
sex, age = tf_predict.predict(arr)
res = 'sex:'+['女','男'][sex] + ' age:'+str(int(age))
else:
res = '请输入正确图片'
return self.render.reply_text(fromUser, toUser, int(time.time()), res)
3.3 个人Demo演示
1)运行服务器
微信公众号的接口只能在80端口,我这里之所以在3000是因为曾经使用Nginx软件将80端口映射到了3000端口。正常情况下这里是在80端口运行。

2)客户端发送图片,服务器处理后并把预测结果发送给客户。

服务器端的反应

4.课程Demo演示
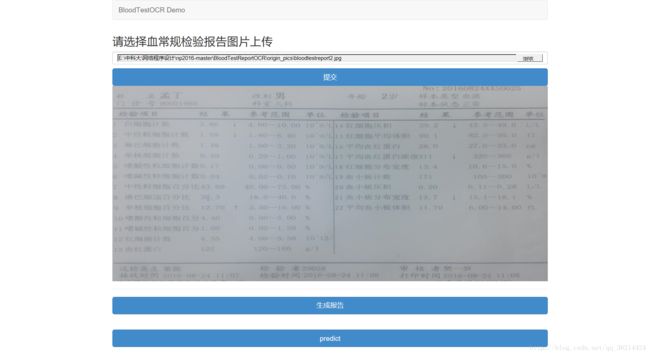
4.1项目启动

4.2上传图片
4.3生成报告

4.4预测结果