ML模型部署-工具箱
ML模型部署-工具箱
Machine Learning模型部署涉及两大工程部分,服务优化和模型优化。服务优化就是大家熟知的后端开发优化,涉及的指标有吞吐量、响应时间、CPU占用和服务内存占用等。而模型优化涉及模型参数量、模型推理时间、内存占用等。
本文将简单介绍有关模型优化的工具库,便于之后需要时进行查阅。
1 推理框架
ONNX
ONNX(Open Neural Network Exchange)是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch、MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊,Facebook和IBM等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有:PyTorch ,Caffe2, PyTorch, MXNet,TensorRT 和 Microsoft CNTK。
TensorRT
NVIDIA TensorRT™ 是用于高性能深度学习推理的SDK。此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。借助 TensorRT,您可以优化在所有主要框架中训练的神经网络模型,精确校正低精度,并最终将模型部署到超大规模数据中心、嵌入式或汽车车产品平台中。
附带一句,ONNX能转TensorRT格式进行推理加速,也就是各种深度学习框架(PyTorch、TensorFlow等)训练的模型都能间接转为TensorRT进行推理加速。
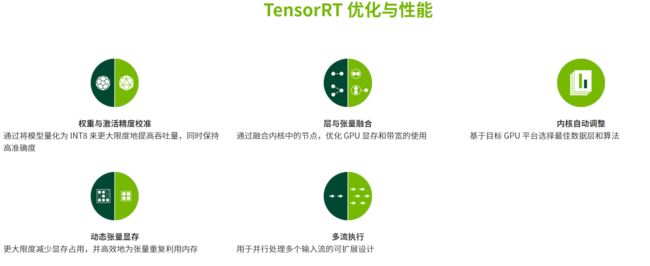
TensorRT 以 NVIDIA 的并行编程模型 CUDA为基础构建而成,所以TensorRT只能在有NVIDIA GPU的设备上使用。
OpenVINO
OpenVINO 是英特尔推出的一款全面的工具套件,利用其提供的深度学习推理套件(DLDT),能将各种深度学习开源框架中预训练好的模型,在Intel的CPU上快速部署起来。
在模型部署中,在线推理阶段往往需要前处理和后处理,前处理如通道变换,取均值,归一化,Resize等,后处理是推理后,需要将检测框等特征叠加至原图等,都可以使用OpenVINO工具套件里的API接口完成。
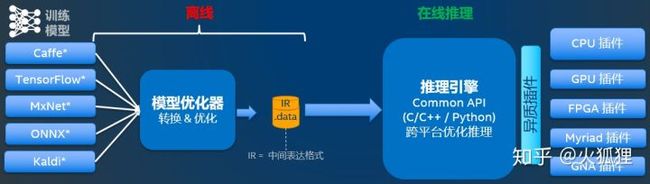
**深度学习推理套件(DLDT)**分为两部分:
- 模型优化器(Model Optimizer)
- 推理引擎(Inference Engine)
关于模型优化器的具体使用过程。将开源框架已训练好的模型通过模型优化器(python脚本工具),转化为OpenVINO推理引擎可以识别的中间表达(xml文件和bin文件,前者是网络结构的描述,后者是权重文件)。模型优化器包括压缩模型和加速[3]。
推理引擎是一个支持C\C++和python的一套API接口,需要开发人员自己实现推理过程的开发。
NCNN
ncnn有腾讯公司推出的,专门为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,将 AI 带到你的指尖。ncnn 目前已在腾讯多款应用中使用,如 QQ,Qzone,微信,天天P图等。[4]
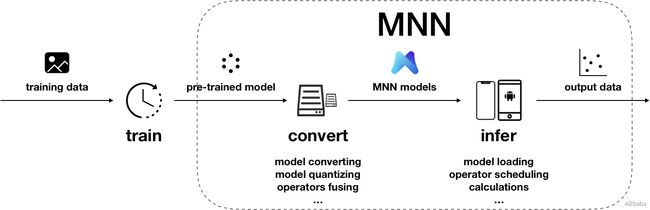
MNN
MNN是一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷等20多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。此外,IoT等场景下也有若干应用。
MNN可以分为Converter和Interpreter两部分。
Converter由Frontends和Graph Optimize构成。前者负责支持不同的训练框架,MNN当前支持Tensorflow(Lite)、Caffe和ONNX(PyTorch/MXNet的模型可先转为ONNX模型再转到MNN);后者通过算子融合、算子替代、布局调整等方式优化图。
Interpreter由Engine和Backends构成。前者负责模型的加载、计算图的调度;后者包含各计算设备下的内存分配、Op实现。在Engine和Backends中,MNN应用了多种优化方案,包括在卷积和反卷积中应用Winograd算法、在矩阵乘法中应用Strassen算法、低精度计算、Neon优化、手写汇编、多线程优化、内存复用、异构计算等。
2 模型服务器
简化模型部署过程的一种方法是使用模型服务器,即专门设计用于在生产中提供机器学习预测的现成的 Web 应用程序。模型服务器可轻松加载一个或多个模型,并自动创建由可扩展 Web 服务器提供支持的预测 API。接下来会介绍常用的模型服务器,并在最后介绍由微软开发的,用于管理整个机器学习项目生命周期的云服务–Microsoft Azure
TensorRT Inference Server
TensorRT Inference Server提供了一个为NVIDIA gpu优化的数据中心推理解决方案。 它通过HTTP或gRPC端点最大化gpu上的推理利用率和性能,允许远程客户机请求对服务器管理的任何模型进行推理,并提供关于延迟和请求的实时指标。
Triton Inference Server
Triton Inference Server提供了一个针对cpu和gpu优化的云和边缘推理解决方案。 Triton支持HTTP/REST和GRPC协议,允许远程客户端请求对服务器管理的任何模型进行推理。 对于边缘部署,Triton是一个具有C API的共享库,允许将Triton的全部功能直接包含在应用程序中。
TorchServe
TorchServe是一款高性能、灵活且易于使用的工具,用于服务于PyTorch模型和torscript模型。模型服务器还可以根据预测请求运行代码预处理和后处理。最后同样重要的一点是,模型服务器还提供对生产至关重要的功能,例如日志记录、监控和安全性等。广为使用的模型服务器有 TensorFlow Serving 和 Multi Model Server。
Azure
Azure 机器学习是微软开发的,一种用于加速和管理机器学习项目生命周期的云服务。 机器学习专业人员、数据科学家和工程师可以在日常工作流中使用它:训练和部署模型,以及管理 MLOps(机器学习生命周期)。
可以在 Microsoft Azure 机器学习中创建模型,也可以使用从开源平台构建的模型,例如 Pytorch、TensorFlow 或 scikit-learn。 MLOps 工具有助于监视、重新训练和重新部署模型。
参考
[1] ONNX home https://onnx.ai/
[2]NVIDIA TensorRT™ (https://developer.nvidia.com/zh-cn/tensorrt)
[3]OpenVINO推理简介(知乎_火狐狸) https://zhuanlan.zhihu.com/p/918825151
[4]腾讯NCNN Github地址 https://github.com/Tencent/ncnn
[5]TensorRT Inference Server https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tensorrtserver
[6]Triton Inference Server https://github.com/triton-inference-server/server
.nvidia.com/orgs/nvidia/containers/tensorrtserver
[6]Triton Inference Server https://github.com/triton-inference-server/server
[7]TorchServehttps://pytorch.org/serve/