推荐系统序列化建模总结
大家好,我是对白。
最近在做行为序列相关的工作,在这里对看过的论文做个总结。行为序列数据蕴含着用户的兴趣偏好,对该信息的挖掘可以提高推荐结果的准确性。对行为序列的建模可以归纳为两方面,特征工程和模型结构。特征是对某个行为过程的抽象表达,特征工程旨在更精确地刻画行为过程,需要对具体的业务场景有一定理解。构建完特征后,还需要运用合适的技术有效地挖掘数据中的信息,所以特征和模型两者缺一不可。学术界的一些工作往往更侧重模型结构上的排列组合,但是在实际场景中仅仅靠魔改模型结构是很难取得效果的,行为序列相关的工作则很好地兼顾了特征和模型。
一方面,很多技术包括行为序列建模在搜广推领域是通用的,但是应该注意到不同的场景下会有相应的变化。搜索场景中用户的意图是主动明确的,目标是让用户更快找到需要的物品;而推荐场景中用户的意图是被动模糊的,目标是尽可能增加用户的使用时长。场景的差异要求我们在使用某一技术时因地制宜。例如,在搜索场景,由于Prefix或Query的限制,召回的物品得满足相关性,一些向量召回方法就不易发挥用处。另一方面,推荐系统不同阶段的特点对特征和模型也有所限制,例如,召回阶段面对的是海量的候选集,只能上简单的特征和模型粗略选出用户可能会感兴趣的物品,而排序阶段的候选集的规模较小,可以上复杂的特征和模型更精确地预估用户对物品的感兴趣程度。
本文从特征工程与模型结构两方面总结行为序列相关的工作,同时会对搜索推荐场景以及召回排序阶段加以区分。
1. 特征工程
-
1.1 行为类型:点击,收藏,成交等可以分别表示用户的短期,中期,长期兴趣,既可以组织为一个混合序列通过类别特征区分[1],也可以直接组织为多个种类的序列分别建模[2]。用户对近期点击过的商品大概率仍然感兴趣,但对于近期购买过的商品一般短期内不再感兴趣(需求已被满足)。
-
1.2 行为时间
-
该行为距离当前请求的时间差。一般来说,用户当前的兴趣与近期行为过的物品更相关。
-
该行为与下一次行为的时间差[3]。一般来说,时间上越接近的行为过的物品更相关,类似一个Session内行为过的物品更相关。
-
在当前物品上的停留时间。例如,用户在购买某一商品时在详情页的停留时间,停留时间越长一般越感兴趣。
-
1.3 行为场景:对一个商品的点击可以发生在首页推荐,搜索推荐和广告推荐[1],同一种行为在不同场景下含有不同的意义。
-
1.4 物品种类:行为序列中的物品可以是Query,Item,Review[4],Music,Movie,Book,Food等,视业务场景而定。
-
1.5 物品属性:如果只使用物品ID特征,长尾物品在样本和序列中占比都很低,其ID Embedding不容易学好,因此可以加入类目,品牌,店铺等泛化特征[1],同时模型也能学习到更泛化的偏好,例如某一用户更喜欢购买阿迪达斯品牌的商品。
-
1.6 序列划分
-
多种兴趣:用序列模型抽取行为序列信息得到用户的兴趣向量,考虑到序列内物品的异构性,单一的兴趣向量难以精确地表征用户的兴趣偏好[5],例如,某个用户的行为序列内既有服饰类商品又有电子类商品,将对不同类目商品的兴趣融合到一个向量内容易导致“四不像”。一个典型的例子是推荐场景的召回阶段,单一的兴趣向量召回的商品往往比较杂甚至不相关[5]。因此,我们可以对行为序列进行划分,一方面,可以根据某个准则手动划分,例如,根据类目特征将商品分类[3],根据时间窗口划分Session[6](同一Session内的物品更相关);另一方面,也可以使用胶囊网络[6],记忆单元[7]等动态学习兴趣划分。事实上,Multi-head Attention也能学习到这样的多种兴趣[8,9],将学习到的Attention分布可视化就能发现,某个Head下的Attention和时间差强相关,某个Head下的Attention和类目强相关等等,说明模型学习到了用户对商品的多种兴趣偏好。
-
长短兴趣:根据时间跨度可以将序列划分为短期序列和长期序列,分别用来表征用户的短期兴趣和长期兴趣(相对稳定)。一方面,可以设置一个时间窗口划分长短期序列分别学习再做融合[9,10],另一方面,也可以用记忆网络来学习长期兴趣[11]。一般来说,用户当前的行为主要受短期兴趣的影响。
-
1.7 超长序列:加长序列可以引入更丰富的用户历史行为,但是序列模型在处理时计算量大且RT高。因此,一方面,可以根据某个规则快速筛选出超长序列中与Target相关的物品,例如,同一类目下的物品,Embedding接近的物品(LSH)等[12],另一方面,可以合理设计网络结构并利用记忆网络学习,将兴趣向量的更新与候选物品的打分解耦[7]。
2. 模型结构
对序列数据的处理非常自然,忽略序列的位置信息可以使用简单的Mean Pooling [13,14],但是位置(时间)信息是刻画用户行为过程的重要特征,因此可以使用CNN/RNN/Transformer等模型处理。目前主流的方法是各种改进的RNN和Attention模型。
-
2.1 RNN:可以分为基础的LSTM,GRU和改进的Attention-RNN,如DIEN[15],DUPN[1]等。RNN可以建模用户的兴趣进化过程,并促进序列中相邻物品的特征交互,但是RNN的计算是串行的容易造成RT高,并且部分场景中用户的兴趣可能是跳跃的,例如,用户购买了Switch后又购买了便携屏,投影仪,塞尔达,前后行为是相关的;但是,也有用户购买了手机后又购买了衣服,零食,前后行为并不相关。
-
2.2 Attention:Attention模型从全局抽取序列信息,缓解了RNN的长程依赖问题,但是Attention本身并不建模位置信息,需要合理设计位置特征Embedding。根据Query的类型,可以分为Self Attention,Target Attention和User Attention;根据Attention计算的方式,可以分为点积模型,双线性模型,加性模型,门控模型,其中门控模型是指运用RNN中计算门控的方式计算Attention向量(区别标量),从而在更细粒度的范围建模重要性差异。
-
Self Attention使用序列中每个物品自身作为Query计算Attention,可以建模序列内部物品之间的依赖关系,并且相比RNN是两两物品之间的特征交互,但是Self Attention的计算量大,在部分场景也没什么效果,例如手淘搜索,之前看过一篇美团的博客[16],其中Self Attention离线在线都有效,可能的原因是:在手淘场景中,一是行为序列中的物品非常异构,二是用户的前后行为存在跳跃的现象,不太适合用Self Attention建模。
-
Target Attention[14]使用待预测的物品作为Query计算Attention,相当于一种Soft Search,筛选出序列中更符合用户当前意图的信息。例如,一个用户近20天购买了手机,衣服,零食,现在系统需要给用户推荐零食商品(可能是首页推荐,可能是主动搜索),与零食商品不相关的对手机和衣服商品的行为信息就不需要保留在兴趣向量中。但是从特征交互的角度来看,Target Attention缺少了序列内部物品的交互。
-
User Attention使用User Embedding作为Query计算Attention,一方面考虑到了用户自身特点对偏好的影响,另一方面加强了用户和物品的特征交互。
-
2.3 胶囊网络:上文提到行为序列中包含了多种兴趣,使用单一的兴趣向量表示存在缺陷,胶囊网络中的动态路由算法可以自动学习这样的兴趣划分,相当于对行为序列进行了自动软聚类。
-
2.4 记忆网络:记忆网络利用外部存储单元来贮存长期信息,同时每个记忆单元又可以看做一个兴趣向量,既可以用来建模多兴趣也可以用来建模长期兴趣。
3. 论文介绍
下面会简单介绍涉及到的论文,虽然文中的实验效果都很漂亮,但是在应用时得结合业务场景具体问题具体分析。
3.1 RecSys’16, YouTube | Deep Neural Networks for YouTube Recommendations [13]
-
问题背景:区别于GBDT+LR等机器学习方法,尝试将深度学习应用于推荐系统
-
业务场景:视频推荐的召回和排序阶段
-
数据处理:对每个用户采样了等量的训练样本,防止活跃的头部用户对模型产生过大的影响。
-
召回阶段
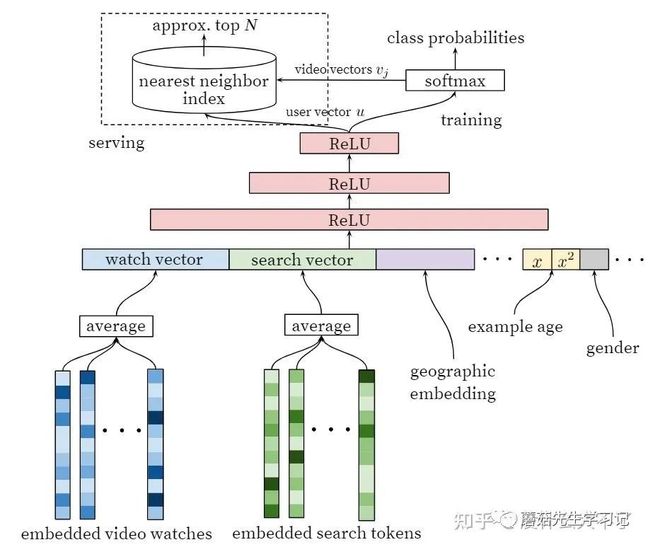
召回模型
-
对序列特征采用简单的mean pooling。
-
Example Age是样本产生的时间(线上用户发生点击)距当前训练时刻的间隔,刻画了用户更偏向于浏览新视频的Bias(个人觉得是近期样本更能反映流行趋势)。在线上预测时,该特征置为0。之所以不用视频产生的时间距当前训练时刻的间隔,可能是考虑到该特征的分布太分散了(包含几年前的视频)。这里还对时间特征进行了开方平方,显示地增强模型的非线性能力。
-
离线训练时将得到的User Embedding和View Embedding存储起来,线上服务时通过局部敏感哈希等方法快速召回。
-
相比word2vec预训练的方式(将行为序列视为句子,任务为用中心词重构上下文),这里根据目标任务直接端到端训练,具体的目标任务抽象为预测下一个观看视频。
-
排序阶段
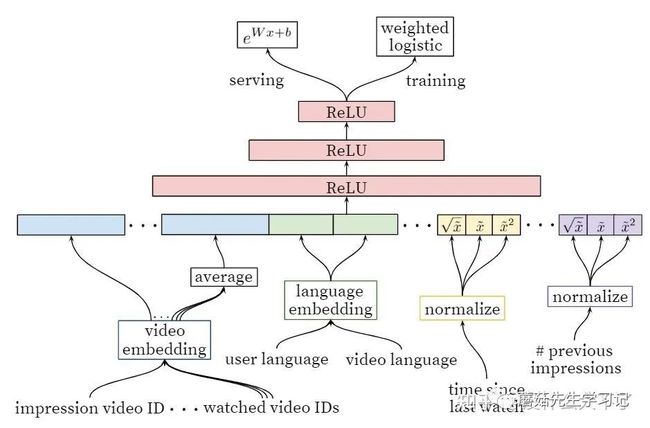
排序模型
-
排序阶段的模型结构和召回阶段基本一致,主要不同点在于特征和目标。
-
特征方面,加入了更多细粒度的特征刻画用户,视频和行为。例如“time since last watch”,自上次观看同频道视频的时间,刻画了用户往往会观看最近同频道的视频。
-
目标方面,广告是YouTube的主要盈利方式,如果仅仅使用CTR预估作为目标任务,会倾向于推荐标题党视频给用户,我们期望可以增加用户观看视频的时长,这样才能在视频中插入广告。具体而言,在训练时采用加权的损失函数,权重与样本的观看时长相关;在线上打分时,使用近似期望观看时长作为打分。
3.2 KDD’18 阿里 | Deep Interest Network for Click-Through Rate Prediction [14]
-
问题背景:Mean pooling的方式忽略了行为序列中的物品相对待打分物品的重要性差异
-
业务场景:广告推荐排序阶段
-
模型结构:对序列数据进行Attention Pooling,Attention的计算方式是Concat+MLP,属于Target Attention,并且还对Q和K进行外积操作,从而增强两者的特征交互。
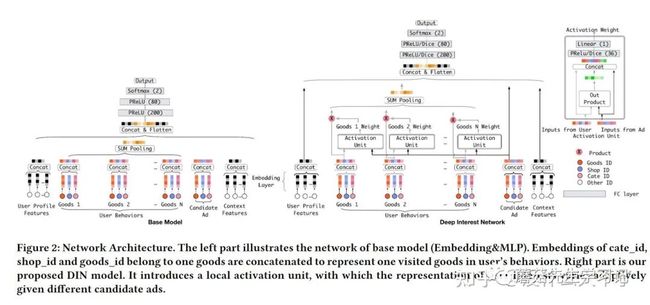
DIN
-
Mini-batch Aware Regularization:个人理解是将对Embedding的L2 Norm Loss限制到了Mini Batch
-
Data Adaptive Activation Function:和LReLU函数的不同点在于,一方面将Hard分段方式改为了Soft,另一方面对特征进行了平滑。
 Data Adaptive Activation Function
Data Adaptive Activation Function
3.3 AAAI’18 阿里 | Deep Interest Evolution Network for Click-Through Rate Prediction [15]
-
问题背景:Attention Pooling忽略了位置(时间)信息,不能建模用户的兴趣进化过程。
-
业务场景:广告推荐排序阶段

DIEN
- Interest Extractor Layer

GRU
-
兴趣抽取层,用GRU抽取序列信息。
-
引入了一个辅助Loss,这里主要是考虑到,行为序列下CTR预估相当于已知1-T次行为,预测T+1次行为,只用T+1次行为作为监督信号更多会作用到第T次行为,对第1-T-1次行为则没那么明显,所以可以人为地将第t+1次的行为作为第t次行为的监督信号。从另一个角度来看,这也促进了行为序列中元素之间的交互(GRU只是单向的)。
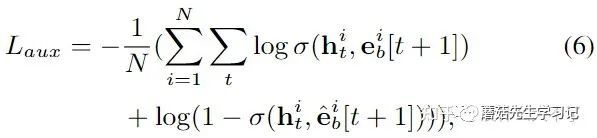
- Interest Involving Layer


-
兴趣进化层,将Target Attention引入GRU,过滤掉与待排序的广告不相关的信息。
-
需要注意的是,这里是先用序列中Item的隐状态和待排序的广告Embedding计算一个Attention标量,再将该标量乘以更新门控向量。最终隐藏状态和候选状态,以及每一个维度的重要性,由当前Item隐状态,待排序广告,前一Item隐状态,当前Item原特征(后两者用于计算更新门)共同决定。
3.4 KDD’18, 阿里 | Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks [1]
-
问题背景:已有工作大多单独优化一个任务,缺少对多个任务的统一建模。多任务可以利用更多样本,对样本稀疏的任务较友好,同时学习到的Embedding泛化性更好。
-
业务场景:商品搜索排序阶段
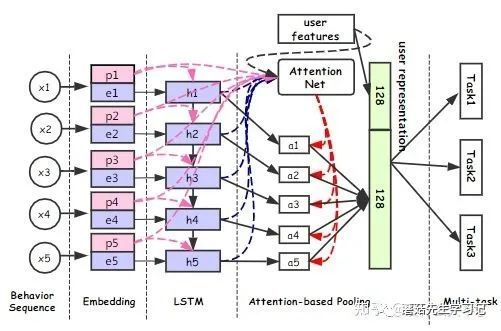
DUPN
-
The Input & Behavior Embedding
-
单个序列数据中混合了多种行为,包括点击,收藏,成交等,通过类别特征进行区分。
-
包含了行为属性特征:行为种类,行为场景(行为发生在搜索,推荐还是广告),行为时间(时间间隔)等。
-
○ 除了Item ID特征(个性化特征),还包含了shop ID,category,tags等特征(泛化性特征),对于长尾Item而言,泛化性特征更重要(样本不充分,ID特征学不好)
-
Property Gated LSTM:行为属性特征只参与门控向量的计算,而没有融入最终的隐状态Embedding中。
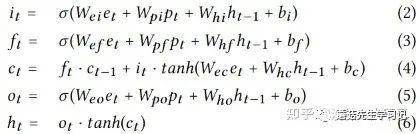
Property Gated LSTM
- Attention Net:行为属性特征同样只用于Attention的计算,Value是不包含这个特征的。这里是Target Attention+User Attention,q是用户搜索的Query,没有直接用待排序的Item是考虑到计算量的问题,u是User Profile特征。
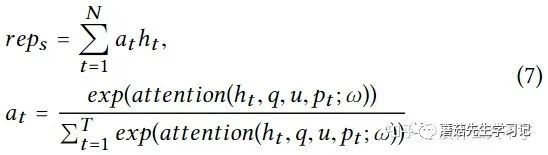
Attention Net
-
Multi-tasks:这里只是简单地共享底层Embedding,对于比较相近的任务容易取得效果,实际上可以用MoME这种更高级的方式。具体而言,多个任务包括:Click Through Rate Prediction,Learning to Rank,Price Preference Prediction,Fashion Icon Following Prediction,Shop Preference Prediction。
-
实验效果
-
行为属性特征对LSTM和Attention的学习都非常重要。
-
在End-to-end Re-training with Single task (RS),End-to-end Re-training with All tasks (RA),Representation Transfer (RT),Network Fine Tuning (FT)中,迁移表征后做Fine-Tune效果最好。个人觉得,这应该和目标场景有关,对于小场景少样本这种类似预训练的方式确实有效,但是对于样本已经很丰富的场景迁移+Fine-Tune的方式不一定有效。
3.5 CIKM’20 京东 | Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems [2]
-
问题背景:已有工作缺少对用户多种行为的利用,缺少对多任务的建模,缺少对场景Bias的建模。
-
业务场景:商品搜索排序阶段
-
特征方面:使用了点击,加购,成交3个Item Sequence,分别表征短期,中期和长期兴趣;对连续型数值特征使用了Z-score归一化;Bias Deep Neural Network中使用了Neighbor Feature,即商品展示时周围的商品信息,他们会影响用户对商品的点击。
-
模型方面
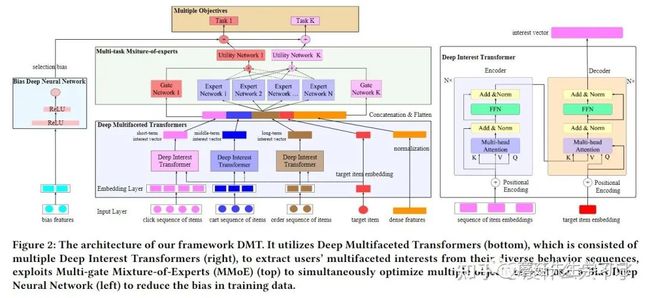
DMT
-
序列建模部分使用Self Attention+Target Attention,位置编码通过sin-cos或可学习的方式生成。
-
多任务建模部分使用MMOE,相比较简单共享底层Embedding,MMOE相当于学习了一组“基”Embedding(划分多个Expert),然后通过Gate机制为每个任务针对性的加权组合“基”Embedding。
-
Bias建模部分使用Bias特征+MLP,输出的Logits与主网络Logits相加。
3.6 AAAI’20 阿里 | Deep Match to Rank Model for Personalized Click-Through Rate Prediction [17]
-
问题背景:已有工作更关注对User Embedding的表达,而没有关注到User和Item的相关性,该相关性可以更直接地反映User对Item的偏好。个人理解是,DIN等模型将学习到的Sequence Embedding(用户兴趣向量)与User Profile,待排序物品特征等Concat后送入最上层的MLP进行特征交叉最终输出一个CTR预估分数,作者认为在Concat特征送入MLP进行交叉前就计算一个User和Item相关性可以降低模型的学习难度。
-
业务场景:商品推荐排序阶段
-
Feature Representation:将召回得分也作为了排序时的特征。
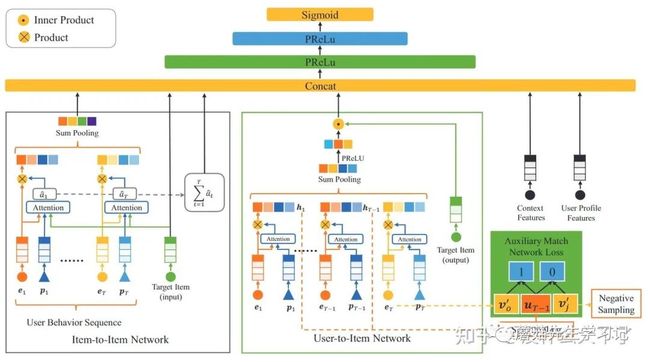
DMR
- User-to-Item Network
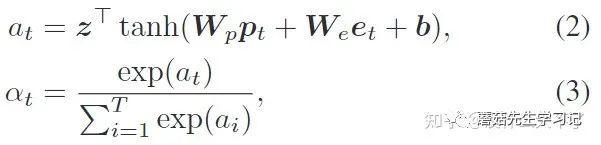


-
是位置特征, 是Item特征,这里用序列中Item自身特征学习其重要性总感觉有点奇怪,不过换个角度将随机初始化的z作为一个与任务相关的Query,最终重要性则取决于与该Query的相关性。
-
对行为序列加权求和后得到User Embedding u,再将该Embedding与待排序的Item v计算点积r作为相关性特征。不过在一个上千维的Concat特征中多一个一维的相关性特征真的有效吗?
-
Auxiliary match network

Auxiliary match network
-
这里是用行为序列中前T-1个Item表征用户,然后用该表征去召回第T个Item(类似于DIEN的Auxiliary Loss的特殊形式)。
-
这里其实相当于一个召回过程。召回和排序是工程上的折中,召回阶段模型简单但打分域大,模型见识过的数据多,排序阶段模型复杂但打分域小,模型见识过的数据少。将召回过程引入排序阶段,扩大了模型的打分域(体现在负采样),让模型见过了更多样本从而表达能力更强,但是线上部署恐怕是个问题。
-
Item-to-Item Network
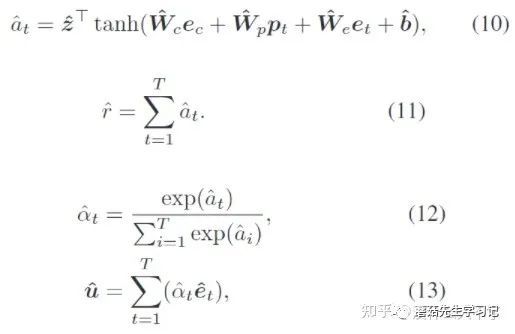
Item-to-Item Network
-
加性模型计算Attention,用到了待排序的Item特征,属于Target Attention。
-
Target Item的Embedding和Sequence Item的Embedding不是共享的。
-
将未经softmax归一化的Attention之和作为另一个User和Item的相关性分特征。
3.7 AAAI’21 腾讯 | U-BERT: Pre-training User Representations for Improved Recommendation [4]
[外链图片转存中…(img-PKHOQRkc-1635863814266)]
U-BERT
这篇论文主要是用BERT对Review(评论)数据进行预训练,加入了领域相关的特征,加入了特征互交叉的操作,在数据集比较小的目标领域上取得了不错的效果,但是对于像手淘搜索这样的大流量场景,预训练的方式想要取得效果可能不太容易。
3.8 IJCAI’19 阿里 | Deep Session Interest Network for Click-Through Rate Prediction [6]
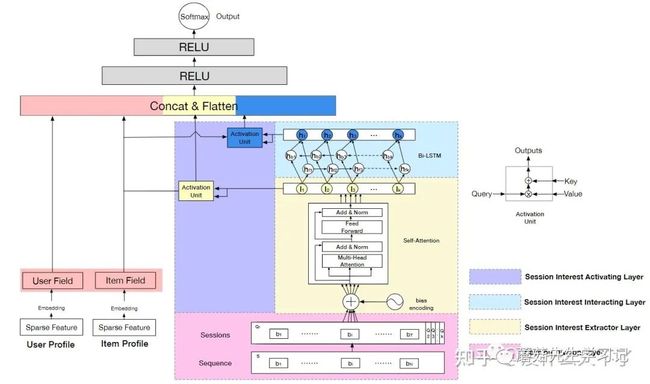
- 问题背景:序列可以被划分为多个Session(一个时间窗口),Session内的Item是同构的,Session间的Item是异构的。例如,用户在一个Session内购买了衣服,裤子,鞋等,在另一个Session内购买了switch,便携屏,投影仪等。直接对整个行为序列用RNN或Attention模型建模会存在问题。
[外链图片转存中…(img-5VZxIz3p-1635863814267)]
Session
-
业务场景:商品推荐排序阶段
-
Session Division Layer:将行为序列按照30分钟的时间窗口划分为多个Session。
DISN
-
Session Interest Extractor Layer:Self Attention+Bi-LSTM
-
Bias Encoding:分别构建了session的位置特征,Item在session的位置特征,Item在Sequence的位置特征。奇怪的是没有使用行为时间特征,个人感觉这类特征还是挺重要的。
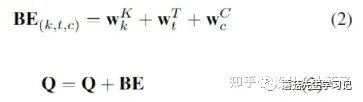
Bias Encoding
- Multi head Self-attention:用Self Attention建模Session内部Item之间的依赖关系(考虑到Session内Item是同构的还是合理的),然后对Session内部Item隐状态Mean Pooling得到Session Embedding(由于Session内Item比较相似,用Target Attention权重也会比较接近)。

Multi head Self-attention
- Session Interest Interacting Layer:用Bi-LSTM对上面得到的Session序列建模兴趣的转移过程,相比Attention模型,RNN更适合学习这种“购买了Item A后接着购买Item B”的模式。

Session Interest Interacting Layer
- Session Interest Activating Layer:用Target Attention抽取相关信息,用双线性点积建模不同方式得到的Embedding的差异性。
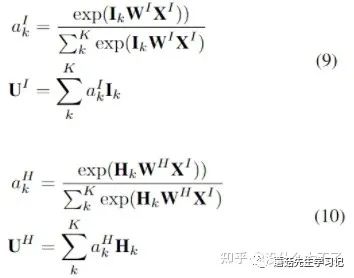
Session Interest Activating Layer
3.9 WSDM’20 京东 | Hierarchical User Profiling for E-commerce Recommender Systems [3]
-
问题背景:行为序列可以划分为不同的粒度,从而更全面地对User Profiling建模。
-
业务场景:商品推荐召回阶段?
-
Hierarchical User Profiling:这里对常用的行为序列(Item view)分别进行了更细粒度(Micro behavior)和更粗粒度(Category View)的刻画,整体上呈现树状结构,刻画粒度从细到粗,最终得到多个不同粒度的兴趣向量。

Hierarchical User Profiling
-
The Input and Embedding Layers:v表示Item, t表示行为时间,b表示行为类型,c表示Item所属的类别,d表示停留时间,g表示和下一次行为的间隔
-
Pyramid Recurrent Neural Networks:用RNN对不同粒度的行为序列建模,底层的隐状态作为高层的输入状态。

Pyramid Recurrent Neural Networks
- Behavior-LSTM Cell:新增了两个受行为特征影响的门控,[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tYLPruq7-1635863814276)(https://mmbiz.qpic.cn/mmbiz_svg/rKBCaRcVshMooyeWaghnHNZdQJLoZBibyVn5NLJafo5wJd2Y9IjhqsANficlJdbUYvklYOFzudd95qZwEsRZvEKNcxiblYMib3Fm/640?wx_fmt=svg)]是前后行为时间间隔,影响着遗忘多少前一次的历史信息;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ta86FZp-1635863814277)(https://mmbiz.qpic.cn/mmbiz_svg/rKBCaRcVshMooyeWaghnHNZdQJLoZBibyiatiaFyJ8lZuNl53mx41tRBmEQQ3PfWbia6ZDictTxB5NxVgffPQVIfZvRdK2AIjhejp/640?wx_fmt=svg)]是行为类型或者停留时间,决定了保留多少当前行为的Item的信息,在Micro Level Layer使用行为类型(停留时间不好统计),其他两层使用停留时间。
[外链图片转存中…(img-k1jR0Kur-1635863814278)]
Behavior-LSTM Cell
- The Attention Layers:用一个2-Layer MLP计算Attention,其中Q是第T步(最后一步)的隐状态,K是第i步的隐状态和行为类型或停留时间,V是第i步的隐状态。
[外链图片转存中…(img-ZfUMTrDE-1635863814279)]
The Attention Layers
- Loss Function:损失函数由负余弦函数构成,每一项对应不同粒度的划分,这里没有负采样。
[外链图片转存中…(img-CTXrU4y2-1635863814280)]
Loss Function
3.10 CIKM’19 阿里 | Multi-Interest Network with Dynamic Routing for Recommendation at Tmall [5]
-
问题背景:由行为序列得到的单一的兴趣向量难以建模用户多样的兴趣。
-
业务场景:商品推荐召回阶段
-
Multi-Interest Extractor Layer
[外链图片转存中…(img-j9lxsfke-1635863814281)]
MIND
- Dynamic Routing Revisit:胶囊网络单元的输入输出都是向量(区别于标量),动态路由算法通过类似K-Means迭代的方式,对底层胶囊(输入向量)进“软聚类”,划分到最相关的高层胶囊(输出向量)中。该模型非常适合用来建模多兴趣划分,底层胶囊可以看做是序列中的Item,高层胶囊则是多个用户兴趣向量,动态路由的过程即将属于同一类兴趣的Item聚类。
[外链图片转存中…(img-57zo9cqQ-1635863814283)]
动态路由
- B2I Dynamic Routing
[外链图片转存中…(img-qStNCSaz-1635863814284)]
B2I Dynamic Routing
- Shared bilinear mapping matrix:用户的行为序列是变长的,不适合为每个Item胶囊分配一个变换矩阵;另一方面,期望通过共享变换矩阵的方式将Item映射到同一个特征空间。
[外链图片转存中…(img-cgtCLd0F-1635863814285)]
Shared bilinear mapping matrix
-
Randomly initialized routing logits:考虑到映射矩阵是共享的,如果初始路由logits一样,会导致高层兴趣胶囊一直不变,因此需要进行随机初始化
-
Dynamic interest number:这里并没有给所有用户都分配固定K个兴趣胶囊,而是设计了一个启发式的规则,保证K个兴趣胶囊足够表征I个行为胶囊。
[外链图片转存中…(img-wxjdV8aU-1635863814289)]
Dynamic interest number
- Label-aware Attention Layer:其实就是Target Item与兴趣胶囊的Target Attention。P用来控制Attention分布的Gap,P趋向于无穷时相当于Hard Attention。
[外链图片转存中…(img-5G6sVt8l-1635863814290)]
Label-aware Attention Layer
- Training:根据行为序列等特征预测下一个Item(Sampling Softmax)
[外链图片转存中…(img-tMr50jSl-1635863814291)]
Training
-
Serving:线上服务时并不会运行Training模块,系统会实时地取到用户的行为序列特征,经过动态路由模块得到K个兴趣向量(即兴趣向量是实时的,随用户行为而更新),再用这K个兴趣向量通过LSH等方法快速召回N个Item,Item的Embedding由离线训练时得到。
-
实验效果:这里主要看一下多兴趣建模的有效性,可以看到单个兴趣向量的召回的Item比较杂也不够准确,而多个兴趣向量分别召回的Item则比较相关且准确。
[外链图片转存中…(img-lGiNrnNy-1635863814293)]
效果
3.11 KDD’20 阿里 | Controllable Multi-Interest Framework for Recommendation [8]
-
问题背景:单一的兴趣向量不足以建模用户的多兴趣;K个兴趣向量召回需要兼顾准确性和多样性。
-
业务场景:商品推荐召回阶段
-
Multi-Interest Framework:作者总结了两种建模多兴趣的方法:动态路由算法和多头注意力机制。
[外链图片转存中…(img-5OtP2gLp-1635863814294)]
贪心算法
- Aggregation Module:仅仅召回K路中最相关的N个Item不利于推荐结果的多样性,作者定义了一个值函数,第一项衡量了准确性,第二项衡量了多样性,其中多样性是通过召回Item的类目种类来定义的。通过贪婪机制确定使值函数最大化的Item集合,即在每一步选取能使当前集合最大化值函数的Item。
[外链图片转存中…(img-DIm85P24-1635863814295)]
值函数和多样性
- 实验效果:动态路由算法和多头注意力机制的效果差别不大
3.12 WSDM’21 阿里 | Sparse-Interest Network for Sequential Recommendation,WSDM 2021 [18]
-
问题背景:已有的多兴趣模型可以分为隐式方法和显示方法。隐式方法通过一个聚类的过程对兴趣做划分,缺少对多兴趣的显示建模;显示方法为每个用户直接学习L个兴趣类簇向量(即随机初始化一组可学习向量用于表征兴趣),无法扩展到工业场景。本文SINE属于显示方法,但是不再为每个用户学习独立的兴趣向量,而是维持了一个所有用户共享的兴趣矩阵,对于每个用户会根据行为序列从中取出相关的K个兴趣向量。“稀疏”体现在每个用户的兴趣个数相对全体用户的兴趣个数是稀少的。
-
业务场景:商品推荐召回阶段
-
Concept activation:C是所有用户共享的conceptual prototype matrix,表征了L个抽象的Concept,类似Item类目等特征。这里对行为序列做self-attention得到一个一般的意图向量,该意图向量包含了序列中各个Item的混合概念信息(如类目),通过它到conceptual prototype matrix取出对应的最相关的Top K个概念向量。
Concept activation
- Intention assignment:每个概念向量表示用户的一个意图,意图分配计算序列中的Item与K个意图向量的相关性,相当于将Item软分配到了K个意图类簇中。
Intention assignment
- Attention weighting:计算序列中的每个Item对预测下一个Item任务的重要性
Attention weighting
- Interest embedding generation:意图向量只包含了高层次的抽象类目等信息,这里还需要利用序列中的Item得到精细的兴趣向量,相当于先得到K个预定义的类簇,然后将序列中的Item分配到K个类簇。
[外链图片转存中…(img-tQoHyzLI-1635863814300)]
Interest embedding generation
- Interest Aggregation Module:MIND训练时通过Label-Attention(Target Attention)聚合兴趣向量,然后测试时由于没有Label(实际上是候选集太大计算量不允许)只能使用K个兴趣向量分别召回K路Item,然后取整体中的Top N个Item。一个直观的方法是粗略计算出下一个Item(Embedding,不是具体的Item)作为我们的Label,但是Item太细粒度了实际上不容易预测准确,因此这里退一步先粗略计算下一个意图(意图相对宽泛,更容易预测),然后使用该意图作为Label,并且在测试时也能保持一致(最后只有一个统一的兴趣向量用于召回)。具体而言,使用之前的意图分布矩阵得到用户当前的意图序列,然后使用Self-Attention预测下一个意图。
Interest Aggregation Module
- Model Optimization:加入了对conceptual prototype matrix的约束项,使得C尽可能正交(形成一组基底)
3.13 IJCAI’18 微软 | Sequential Recommender System based on Hierarchical Attention Network [10]
-
问题背景:以往工作将长期兴趣看做用户比较稳定的的一般性偏好,因此在用历史行为建模时没有考虑到其变化性。
-
业务场景:商品推荐召回阶段
-
Long-term Attention-based Pooling Layer:作者根据时间窗口将行为序列划分为Long-term sets和Short-term sets,然后对前者用User Attention抽取信息(召回阶段的限制,候选集太大不能用Targte Attention)。
Long-term Attention-based Pooling Layer
- Long- and Short-term Attention-based Pooling Layer:将得到的long-term representation与short-term sets一起做User Attention融合。
Long- and Short-term Attention-based Pooling Layer
3.14 CIKM’19 阿里 | SDM: Sequential Deep Matching Model for Online Large-scale Recommender System [9]
该工作和上一篇类似,模型结构上为LSTM+Self Attention+User Attention+Gated Attention(融合长短期兴趣);用多头注意力机制建模用户的多兴趣;对long term sequence从特征的粒度建模,例如类目序列等,大概用来表示一些比较稳定的偏好吧,对各个feature序列Attention抽取后再concat得到Long Term Sequence Embedding。
[外链图片转存中…(img-aJ6nXQsG-1635863814304)]
SDM
3.15 KDD’19 阿里 | Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction [7]
-
问题背景:加长序列可以包含更丰富的用户历史行为,但是一方面,超长序列会带来巨大的存储消耗,另一方面,已有的基于RNN,Attention的方法在处理超长序列时无法满足排序阶段线上服务的低时延要求。
-
业务场景:广告推荐排序阶段
MIMN
- 模型结构:该工作的一个关键在于将用户兴趣向量的更新与用户的请求(待排序物品的打分)进行了解耦,当用户发起一个请求,系统会到UIC模块取出其兴趣向量用于打分;当用户发生商品点击等行为时,系统动态更新UIC中对应的兴趣向量(通过记忆网络的方式)。这两个过程彼此是独立的。但是这样的一个缺陷是,无法对序列做Target Attention。
模型结构
3.16 CIKM’20 阿里 | Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction [12]
该工作也是针对超长序列,其业务场景为广告推荐排序阶段,一般来说,在排序阶段对行为序列使用Target Attention效果较好,对不相关的行为过的Item信息进行了过滤,但是在处理超长序列时计算时延是不可接受的。本文介绍了两种方法,先对超长序列做一次“初筛”,留下与目标Item相关的部分,接着就可以对缩短后的序列用Target Attention“精筛”。一种是“Hard Search”,只保留与Target Item同一类目的Item,线上服务时会构建一个User ID-Category ID-Item ID的二级索引表。一种是“Soft Search”,离线训练时使用整个长序列得到Item的Embedding,线上服务时利用离线训练得到的Embedding,然后用ALSH方法快速筛选出与Target Item相关的Item。该方法非常类似召回和排序。
关于我
你好,我是对白,清华计算机硕士毕业,现大厂算法工程师,拿过8家大厂算法岗SSP offer(含特殊计划),薪资40+W-80+W不等。
高中荣获全国数学和化学竞赛二等奖。
本科独立创业五年,两家公司创始人,拿过三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研清华后退居股东。
我每周至少更新三篇原创,分享人工智能前沿算法、创业心得和人生感悟。我正在努力实现人生中的第二个小目标,上方关注后可以加我私信交流。
期待你的关注,我们一起悄悄拔尖,惊艳所有~