从self-attention到transformer之transformer
从self-attention到transformer之transformer
在看这篇笔记之前你最好确保自己了解了self-attention的内容,这里附上关于self-attention的笔记连接供参考:
https://blog.csdn.net/weixin_42254244/article/details/116572402
1. Seq2Seq模型:
今天来介绍transformer模型,也跟后来产生的BERT有着紧密的联系,transformer也是Seq2Seq中的一个。Seq2Seq模型一般都有Encoder和Decoder两个结构,由Encoder来处理input sequence然后交给Decoder来决定要什么样的output sequence。如下图所示:

2. Encoder:
首先来介绍transformer的Encoder的部分,Encoder要做的事情说白了就是输入一个序列的向量然后经过处理在输出另一个序列的向量(同样长度)。就针对Encoder这件事情来说,不仅仅是self-attention,还有RNN,LSTM都可以做同样的事情。

那transformer模型中的Encoder的主要部分就是self-attention来做的。下图就是transformer论文中的Encoder的原始架构。
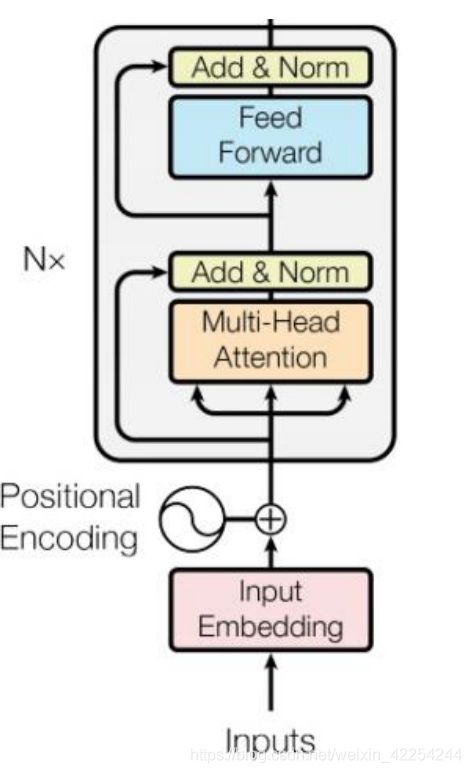
看起来可能会非常复杂,下面分别用几张图片来拆开讲解transformer的Encoder的架构:
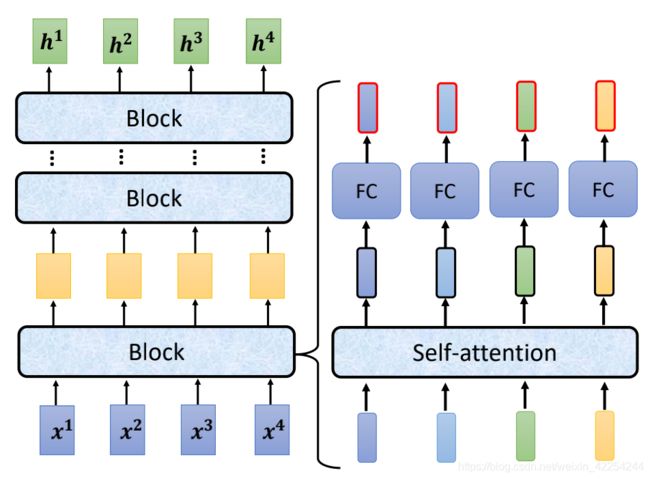
先看左半部分,Encoder是由好几个block连接而成,每一个block都是输入一个序列的向量然后经过处理在输出相同长度的向量再作为输入传给下一个block。(这里之所以叫block而不叫layer是因为每一个block其实都多了好几个layer的事情)
每一个block里面所做的事情就像右半图画的一样,输入一个序列先通过一个self-attention结构,然后再通过一个fully-connected neural network得到输出的序列。
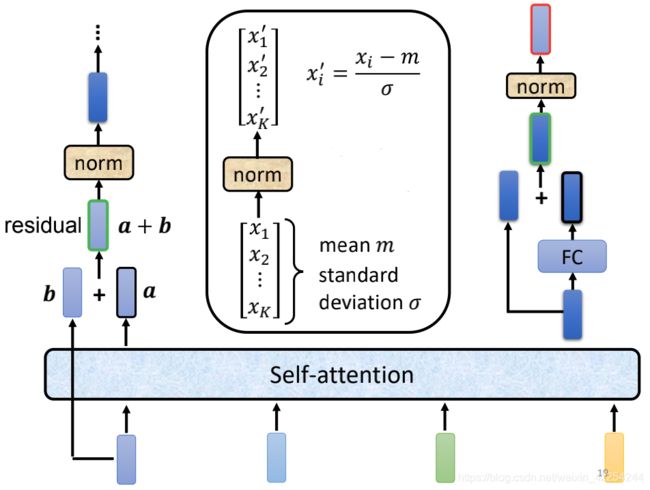
然而实际上,真实的block做的还不止这么多,还要把经过self-attention前后的对应位置的输入a和输出b加在一起的a+b当作是self-attention的新的输出。这种把输入和输出加在一起的做法叫residual connection(残差连接),这种做法在CV领域还是用的很广泛的,这里就不做详细的介绍。(其实是博主本人没有详细了解)
经过了residual connection之后还没有结束,还要把新的输出a+b做一次normalization。这里用的不是batch-normalization而是layer-normalization,layer-normalization其实还要逼batch-normalization更简单一些。不需要考虑序列的其他位置,只是计算单个向量的均值m和标准差σ。然后把每个元素分别减去m再除上σ。
得到了layer-normalization的输出其实才是fully-connected neural network的输入,而fully-connected neural network这起还要再做一次residual connection,把输入和输出加在一起然后再做一次layer-normalization再输出。而这个最后的输出序列才是Encoder中一个block的输出。整个过程如下图所示:
这回再来回去看最开始的图,(图中Add&Norm代表的是Residual+Layer norm的意思)您可能就明白Encoder究竟是什么样的了。把input(可能是one-hot)做embedding,然后加入positional encoding表示位置信息(在self-attention那篇中有简略介绍)然后把它们送进上文一直在介绍的复杂的结构中,重复N次得到的结果就是Encoder部分最后的输出。(之前没有强调这里用的self-attention是multi-head selfattention)

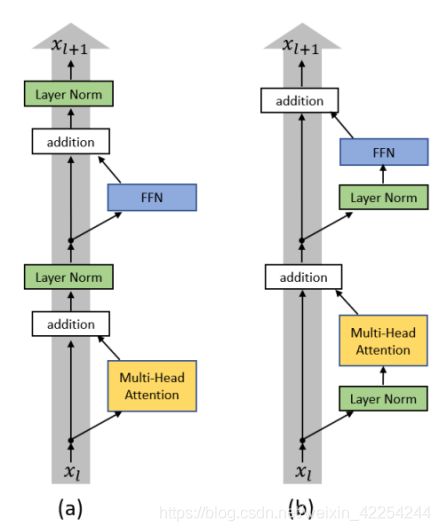
那其实前介绍的都是论文里提到的原始架构,很多人尝试过调整架构里面各种操作的顺序。就像下图那样,把layer-normalization的结构提前反而取得了更好的效果:(图a代表原始架构,图b代表改进的架构)
总之到现在为止就介绍完了transformer的Encoder部分,这个结构在BERT模型里还会再出现。(其实可以这么说,BERT就是transformer的Encoder)
3. Decoder:
接下来介绍transformer中Decoder的结构,Decoder主要分为两种,Autoregressive Decoder和Non-autoregressive Decoder。下面主要介绍Autoregressive Decoder。之前一直在介绍Encoder,它的结构非常复杂,如果到这里您已经忘了前面的内容那就算了,您只需要记得Encoder是输入一个序列然后输出一个相同长度的向量序列就够了。Decoder部分用语音辨识来当作例子,假设我们给Encoder输入的是一段语音,只有“机器学习”四个字然后输出四个特征向量,再传给Decoder,具体怎么传给Decoder一会再来介绍。
我们首先要给Decoder一个开始信号(也是一个向量)一般用字符串“”来表示。然后Decoder的第一个位置会输出一个长度为|V|(V=你希望可能会输出的词的词典大小)的向量。然后再通过一个softmax的激活函数,得到的新的|V|维向量每一个维度的数值反映当前维度(索引)对应词典中单词被产生的概率。选择概率最高的维度对应的字当作当前(第一个位置)的输出。在下图的例子中“机”的概率最高,所以第一个位置的输出就是“机”。

接下来把“机”当作下一个位置的输入,然后根据前两个位置的输入“和机”得到另一个|V|维向量,选择数值最大的维度代表的词当作第二个位置的输出“器”。然后再把“器”当做下一个位置的输入,现在Decoder看到的就是前三个位置的输入“,机,器”,然后还是选择概率最大的字“学”当作第三个位置的输出。这个过程会反复的被持续下去,再把“学”当作输入,Decoder看到“,机,器,学”之后,输出的可能是“习”。整个过程如下图所示:会用红线特别表示前一个位置的输出会被当作下一个位置的输入。

到这里很多人可能会想到一个问题,这个过程难道不会出错吗?答案是肯定的,当然可能出错。如果中间的某一个位置的输出是错误的,那么后续的输出是根据错误的输入来进行的,得到的结果大概率也是错的。这个问题当然也有有效的解决方案,可以采用一种叫Beam search的方法,这个不是今天的重点所以不做介绍。
接下来看一下Decoder内部的结构长什么样。看起来比Encoder还要复杂一些…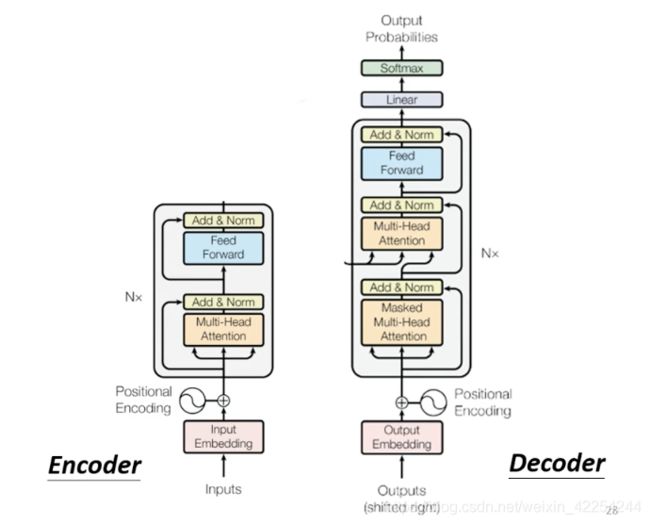
我们把Encoder和Decoder放在一起来对比一下:

你可能会发现,如果把Decoder中间的一个部分遮起来以后,它们两个就长得很像了:

这边有一个稍微不一样的地方是Decoder的multi-head self-attention部分还加了一个masked,这个masked是什么意思呢?
是这样的,原来的self-attention输入一个向量序列,再同时输出另一个向量序列。每一个输出的向量都要看过全部的输入才能得到输出。
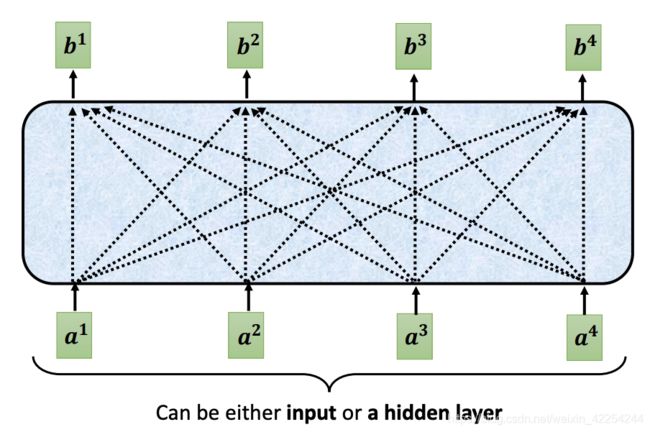
而加入了masked以后,可以理解为不能看右边的部分,也就是说生成b1时候,不能考虑a1之后的输入,只能使用a1提供的信息,当产生b2的时候只能考虑a1 a2,不能再考虑a3 a4的信息。换句话说就是,再生成b2的时候我们只用a2得到的query分别与a1 a2得到key相乘得到两个attention score再加权平均a1 a2得到的value,产生b2。如下图所示: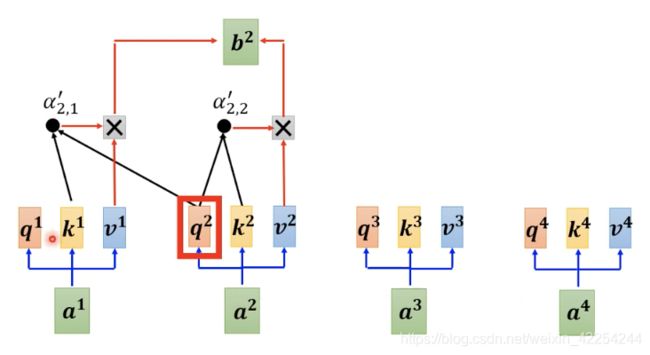
那么为什么要masked呢?这件事情其实非常的直觉,在Encoder的部分是一次性把a1 a2 a3 a4读进去。而在Decoder的部分a1 a2 a3 a4是依次输入的,是先有a1然后再有a2,之后才有a3和a4的,所以在生成b2的时候根本不可能考虑a3和a4。
讲到这里,你们可能早就发现了一个关键的问题,就是这种autoregressive的Decoder必须要自己决定输出的序列的长度。不能从Encoder输入的序列中获取输出序列长度的信息,并不是输入四个向量,在Decoder就输出四个向量。(前面的例子只是一个例子而已)当然不会一直持续下去,那么什么时候停下来呢。要特别准备一个类似于前面提到的开始符号的结束符号一起加到词典里面去,这个符号一般用字符串“”来表示。也就是说Decoder也可能会输出“”。

在前面的例子中我们期待当把“习”输入到Decoder中后,Decoder会输出一个“”,也就是说Decoder在看到了Encoder的embedding和,机,器,学,习之后觉得不需要再输出什么其他的东西了就输出一个“”符号(恰好经过softmax之后概率最大)那么整个decode的过程就结束了。
那以上就是Autoregressive Decoder(AT)的运作方式。接下来简单介绍一下Non-autoregressive Decode(NAT)的模型。在AT中是先输入输出w1,然后把w1当作输出后面的知道有为止。那在NAT中做法是这样的,第一种方式是单独训练一个网络来决定输出序列的长度,然后输出等长的序列,然后得到想要的长度的输出。第二种方式是,预先设定一个最大的输出长度maxLength,然后不管三七二十一直接把maxLen长度的丢进去,得到maxLength长度的输出序列,在序列中哪个位置得到了,那么截止到这里把后面的位置输出都舍弃掉。如下图所示: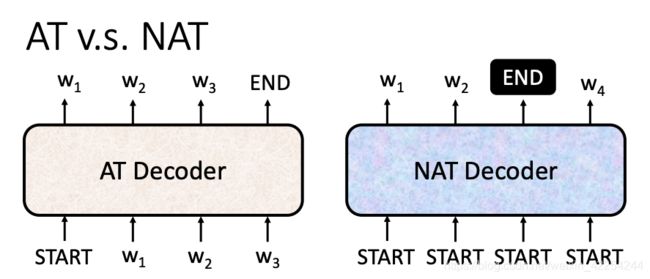
那NAT的Decoder有什么好处呢?第一个就是输出是并行的,假设要输出一个长度为100的序列,NAT只需要做一次的decode就可以一次性得到全部的输出序列。而AT的Decoder要一个一个输出,也就是要做100次的decode。其实NAT的想法是有了self-attention之后才产生的,像之前只有RNN和LSTM做Seq2Seq模型的时候就算你一次性输入了一排的还是要等模型一个一个大输出。直到后来有了self-attention才可以做到并行输出。那另一个好处就是NAT比AT更容易控制输出序列的长度。但是就算是这样NAT的Decoder的performance往往比不上AT的Decoder。
接下来介绍一开始遮盖起来的部分,这一部分实际上是连接Encoder和Decoder的桥梁。从下图中可以看到中间的部分有两个箭头来自于Encoder,有一个箭头来自于Decoder自己。如下图所示:
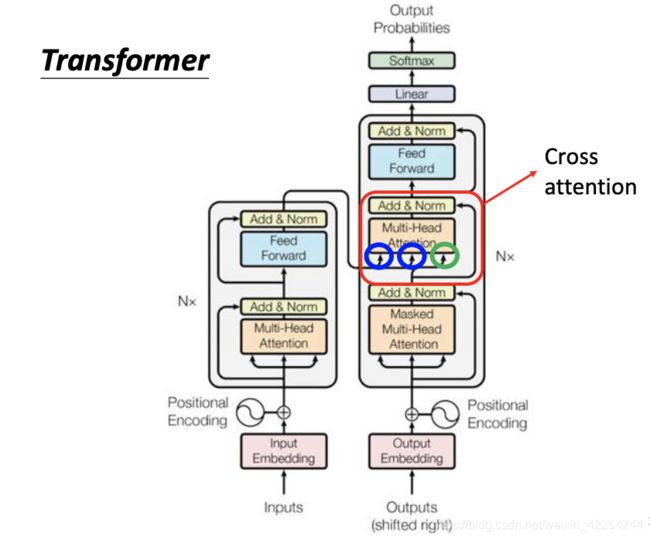
接下来具体看一下这一块到底经历了什么:假设Decoder这边输入了一个经过了第一个self-attention(masked)之后得到了第一个位置输出,然后成一个矩阵Wk得到q,再用q分别和Encoder得到的k1 k2 k3(由a1 a2 a3乘矩阵Wk得到)做点积再经过softmax得到attention score。在加权平均v1 v2 v3 (由a1 a2 a3乘矩阵Wv得到)得到一个v向量再是接下来送到fully-connected nerual network的输入。整个过程叫做cross attention类似于self-attention,只不过query来自Decoder,而key和value来自Encoder。如下图所示: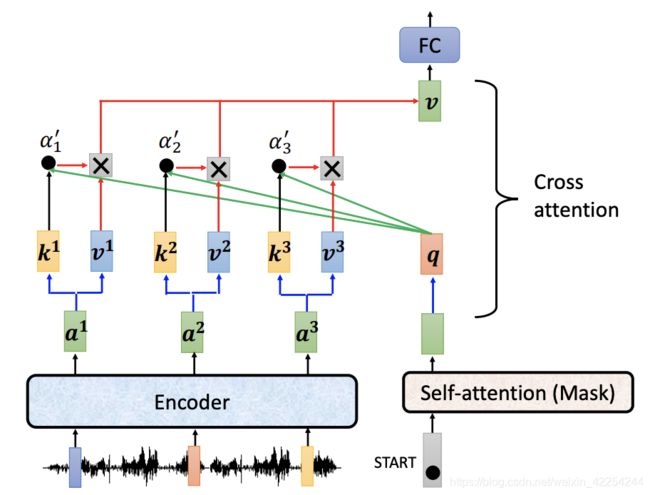
接下来的过程也是一样的,假设第一个位置得到“机”然后当作输入给第二个位置,就不做详细介绍直接上图: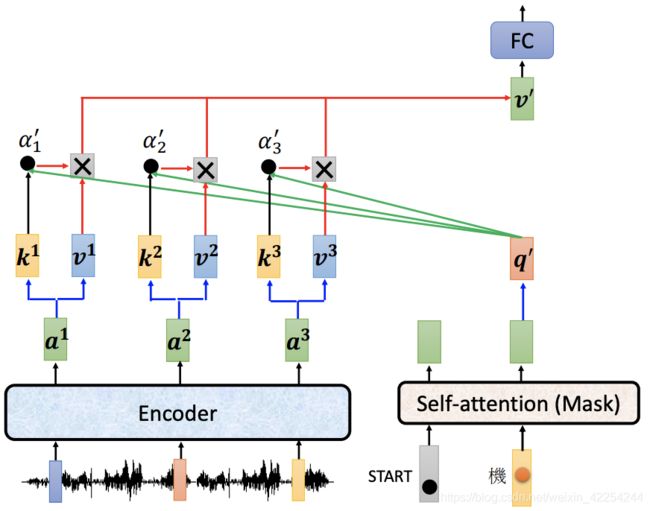
要注意的是前面的一小部分都没有提到residual和layer-norm,不是没有哦,图上都有标明。还有人可能会问,Decoder和Encoder都有很多层,是不是Decoder的每一层都是和Encoder的最后一层做cross attention呢?原始的论文里确实是这样的,不过这个无所谓,可以更改transformer的结构也没问题。完全可以有以下这么多种结构: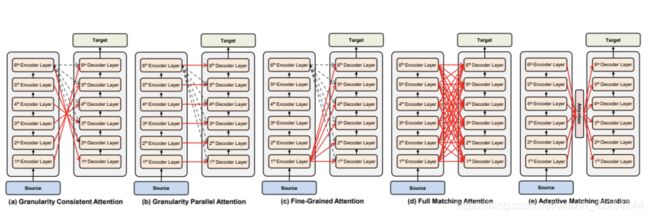
4.Encoder & Decoder
刚才说的都是模型训练好以后是怎么运作的,现在来介绍一下transformer是如何训练的:
如果今天是要做语音辨识,那么先要有一堆的语音信号,然后把每一段信号对应的文字打出来(也就是labels)每一个字都表示成one-hot的形式。后面就相当于是输出的每一个位置都是一个多分类问题了。用ground turth和softmax得到的distribution计算cross entropy做损失函数。再用梯度下降做优化最小化损失函数就好了。
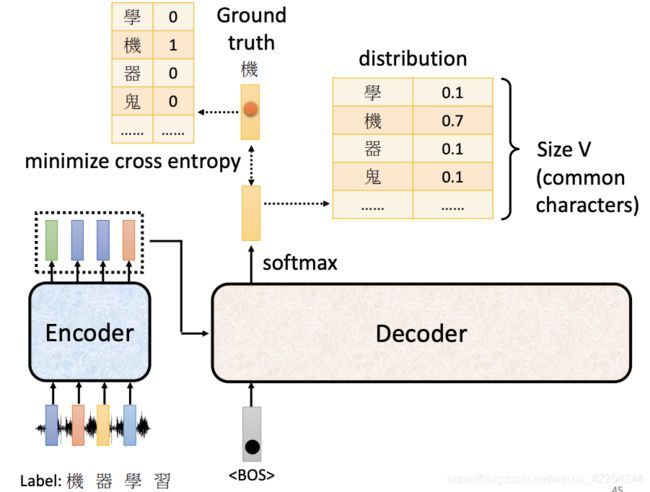
这边还有一个重要的问题,与之前的应用过程中不同的是,在训练过程中我们给Decoder每一位置的输入都是正确答案而不是前一个位置的输出。这种技术叫teacher forcing。
好了以上就是transformer的全部内容。本文内容是学习李宏毅老师机器学习课程的笔记,所这里附上李宏毅老师主页链接:
https://speech.ee.ntu.edu.tw/~hylee/index.html