车道线检测新工作VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection ICCV2021
之前写过一篇车道线检测的综述,得到了一些朋友的认可,也因此结识了几个做车道线检测任务的朋友。
之前的车道线检测综述可以点击阅读:
车道线检测综述及近期新工作
https://blog.csdn.net/qq_41590635/article/details/117386286
最近看到了一篇发表在ICCV2021上得车道线检测的新工作——VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection,效果不错,并且提出来了新的车道线数据集,而且文章说是目前第一个视频实例车道线检测数据集,并提供了baseline方案MMA-Net。学习了一下,简单整理如下,感兴趣的朋友可以看一下,希望能起到一点帮助。
1 文章及数据集信息
原文链接:https://arxiv.org/abs/2108.08482
代码:https://github.com/yujun0-0/MMA-Net
车道线数据集:https://pan.baidu.com/s/1NkP_5LMLTn6qsu9pSbyi0g 提取码:iy16

2 研究背景与内容
近年来,自动驾驶在学术界和工业界都受到了广泛的关注。其中最基本和最具有挑战性的任务是在真实场景中进行车道线检测从而辅助驾驶。但是由于恶劣场景的存在,如遮挡、雾霾、黑暗、强光反射等,准确地进行车道线检测极具挑战性。
现有的车道线检测方法大多集中在单帧图像的车道线检测上,而在真实的驾驶中汽车获取的是驾驶视频。因此将车道线检测从图像级别扩展到视频级别是非常重要的,因为后者可以利用时域一致性来解决单帧无法解决的问题,如车道线遮挡、破损等问题。但是进行视频车道线检测的主要障碍是缺乏具有连续车道线实例标注的(视频)数据集。现有的车道线检测数据集(例如,TuSimple、Culane、ApolloScape和BDD100K), 只支持单帧车道线标注(TuSimple、Culane),或者缺乏连续的实例标注(ApolloScape和BDD100K)。
针对以上问题,在这项工作中:
1)首先收集和标注了一个新的视频车道线检测(VIL-100)数据集。它包含100个视频,具有10,000帧图像,涵盖拥挤路况、车道线破损、雾霾、夜晚等10类经典场景。我们将所有视频的帧率从最初的30fps下采样到10fps,对每帧中的所有车道线提供了实例级标注。
2)设计开发了一个新的baseline模型,即多级记忆聚合网络(MMA-Net)。文章提出的网络聚合局部和全局记忆信息增强当前帧的CNN特征。具体来说,将原始视频中历史帧作为局部记忆,时序打乱视频中的历史帧作为全局记忆。局部和全局记忆(LGMA)模块以注意力机制分别对多尺度的局部和全局记忆信息进行聚合,并结合当前帧的特征得到车道线实例分割结果。
3)最后,在VIL-100数据集上对该方法和10个相关方法进行了全面评估。结果表明,文章提出的模型明显优于现有方法,包括单张图像车道线检测方法、视频实例分割方法。
3 车道线数据集
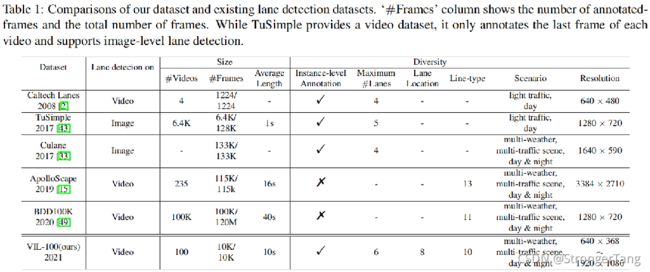
当前的深度学习方法中,数据十分重要。当前的车道线检测数据集主要有Caltech Lanes、TuSimple 、Culane、BDD100K、ApolloScape等,各数据集相关信息如上表所示。但这些数据集都存在一定的局限:
- Caltech Lanes only contains 1,224 images and is usually not used for training deep networks.
- TuSimple and Culane provide large-scale image data with instance-level lane annotations. However, both TuSimple and Culane are not applicable for video instance lane detection.
- BDD100K and ApolloScape are two large-scale video datasets for driving.However, these two datasets do not provide annotations of lane instances – on each frame, multiple lanes of the same kind are not separated and annotated with one label. Lane instance detection is important for regular/emergency lane change, trajectory planning, autonomous navigation in autonomous driving.
基于此背景,这篇文章提出了第一个视频级实例车道线数据集VIL-100 。
3.1 VIL-100数据集
VIL‐100详情:
- 共包含100个视频,每个视频有100帧,总计10,000帧。
- 其中97个视频是通过车载前置摄像机拍摄,3个则从网络上获取。所有视频的帧率从最初的30fps下采样到10fps。
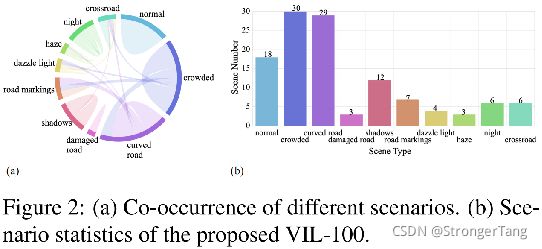
- 收集了10个典型场景:正常路况、拥挤路况、弯道、受损道路、阴影、道路标志、强光、雾霾、夜晚和十字路口。
- 按照8:2的比例将数据集分割为训练集和测试集,所有场景均会在训练集和测试集中包含。
- 将每帧中的所有车道线的中心点坐标存储在json文件中。其中每条车道线被存储为一组,从而提供了实例级车道线注释。然后将每组点用三阶多项式拟合成一条曲线,并将其扩展为具有一定宽度的车道线区域。在1920 × 1080的图片上,将其拓宽为30像素。对于低分辨率的帧,扩展宽度等比例减少。
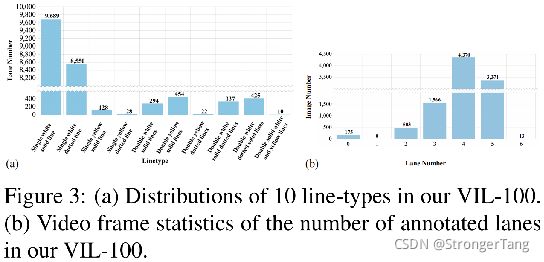
- 每条车道线标注了车道线类型,共10种,即: 单白色实线、单白色虚线、单黄色实线、单黄色虚线、双白实线、双黄实线、双黄虚线、双白实虚线、双白虚实线、白黄实线。
- 每一帧中标注了车道线与自身车辆的相对位置,即2i 表示车辆右侧的第 i 条车道线,2i-1 表示车辆左侧的第 i 条车道线。
图2 (a)(b)分别展示了上述10个典型场景的混合情况和出现次数。图3 (a)(b)分别统计了车道线的线型和每帧存在条数。
4 baseline方案——MMA-Net
本文提出的视频车道线检测baseline方案MMA-Net是在ICCV2019发表的处理视频目标分割任务的《Video Object Segmentation using Space-Time Memory Networks》一文的基础上加以改进的,因此先简要补充介绍一下这篇文章。
4.1 Video Object Segmentation using Space-Time Memory Networks
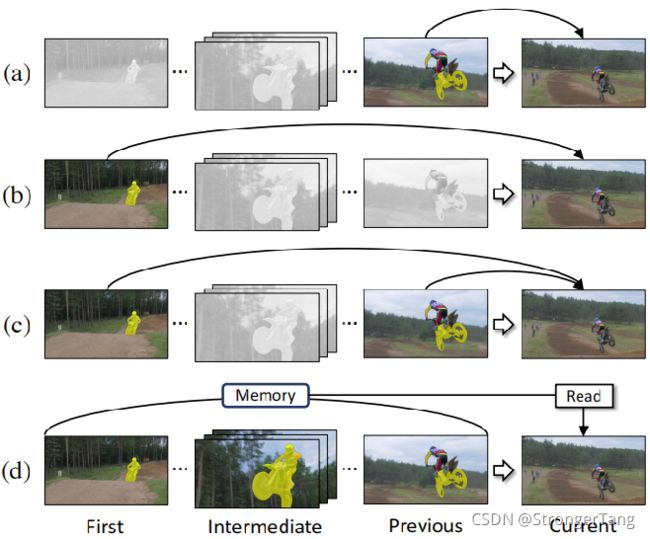
如上图所示,在视频分割任务中网络从视频帧中获取到的目标信息会随着分割的进行逐渐丰富起来,现有的一些分割方法确实或多或少地采用了之前帧的分割结果,但是并没有将当前帧之前的所有帧得到的信息进行融合,帮助当前帧进行分割。
因而这篇文章就是从这角度出发,构建一个大的memory池子从而提出了一种半监督的视频分割方法STM(Spatial-Time Memory Network ),将当前帧的信息与之前帧的所有信息在空间与时序维度上进行特征匹配,从而得到超过之前方法的性能表现,由于采用了之前帧的所有信息自然其对遮挡和目标外表变化的鲁棒性能更加出色。文章的这个方法在DAVIS与Youtube-VOS数据集上性能表现都是很强的。
PS:将当前帧之前的所有帧及其mask都保存到Memory里面是很低效的,文章中默认保存前一桢与首帧,其它的帧则是间隔 N = 5 进行采样。
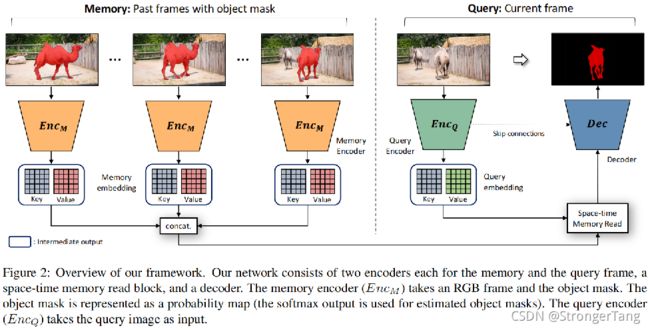
上图可以看到,无论是之前的帧和当前帧都会将数据编码成为键值对的形式(Key和Value):
1)Key:它被用于评估当前帧和之前帧的相似性,用以判断memory中那些特征应该被采样出来,因而其编码了视觉语义用以实现对目标外表变化的鲁棒;
2)Value:相比key中保存的信息,Value中保存的信息则更加的细致,它是用来生成最后mask精细结果的。这里Value在Memory和Query中是由些许不同的:在Query中value包含详细的当前帧的外表信息从而用于解码生成细致的mask;而Memory中的value则包含了详细的目标外表信息与区分前景背景mask信息。这是由于他们进行编码的对象不一样导致的;
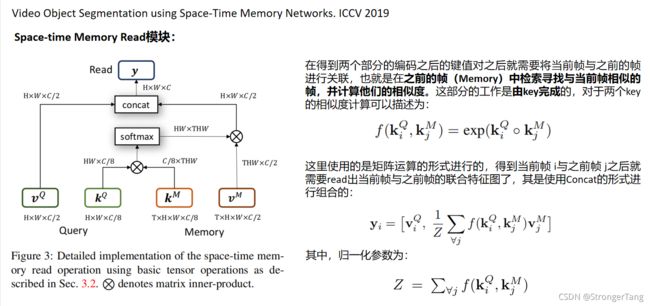
4.2 视频级实例车道线检测 MMA-Net

和4.1节中介绍的baselise方案类似,MMA-Net网络输入包括作为Memory的历史帧和作为Query的当前帧。
- Memory中,首先将原始视频中历史五帧和乱序的视频中的历史五帧分别输入到编码器,得到对应的高级特征和低级特征。之后分别将高级特征图和低级特征图输入局部-全局记忆聚合(LGMA)模块,得到低级和高级的记忆聚合特征。
- Query中,当前帧通过编码器得到低级特征和高级特征,与Memory中得到的记忆聚合特征共同分别传递给记忆读取(MR)模块。
最后,采用U-Net解码器来融合不同CNN层的特征,预测当前帧的车道线实例检测结果。

5 实验
5.1 评价指标
单帧的车道线检测评价指标,小汤之前在之前的综述里已经介绍过:
车道线检测综述及近期新工作
https://blog.csdn.net/qq_41590635/article/details/117386286

而对于视频级车道线检测的评价指标,这篇文章采用的MJ、OJ、MF、OF、MT等指标是出自另一篇视频实例分割文章——A benchmark dataset and evaluation methodology for video object segmentation. CVPR2016
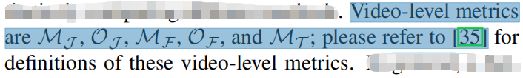
时间关系,小汤没有去看,网上搜了一下,大概是从区域相似度、边沿精度、时间稳定性等方面进行评价,感兴趣的朋友可以自己去仔细看一下。
ps:以下两张图片来自他人博客截图,表示感谢。


5.2 实验结果
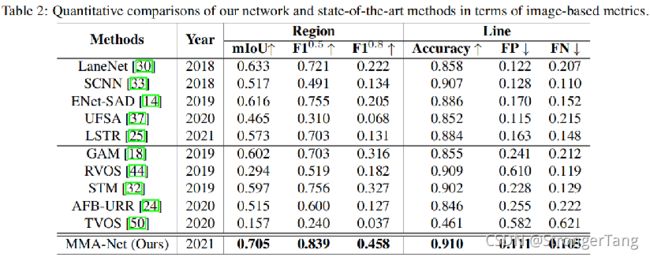
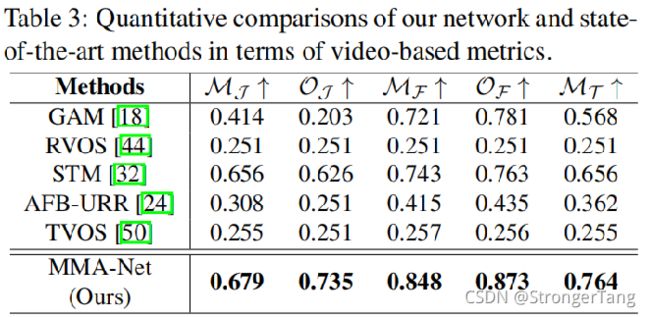
效果在帧级和视频级都表现sota。
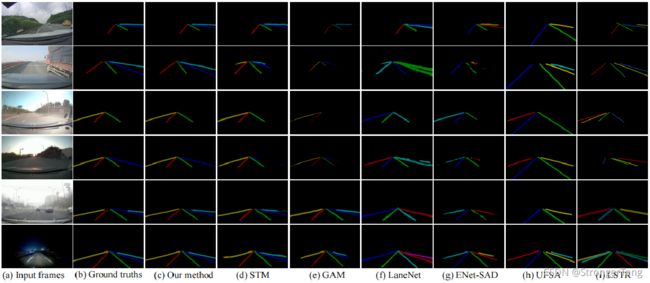
5.3 可视化结果
6 致谢
自动驾驶相关方向的同行或者感兴趣的朋友,欢迎加入自动驾驶交流群,搜索同名g。-[z、号StrongerTang,看更多文章。
本博客参考了 VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection原文及相关网络资料,在此表示感谢,因当时PPT制作距今已有两周,忘记了一些参考来源,所以无法一一罗列致谢,望理解,再次表示感谢!