基于机器学习的交通标志的识别c++_基于机器学习的恶意URL识别
网络攻击成为日益重要的安全问题,而多种网络攻击手段多以恶意URL为途径。基于黑名单的恶意URL识别方法存在查全率低、时效性差等问题,而基于机器学习的恶意URL识别方法仍在发展中。对多种机器学习模型特别是集成学习模型在恶意URL识别问题上的效果进行研究,结果表明,集成学习方法在召回率、准确率、正确率、F1值、AUC值等多项指标上整体优于传统机器学习模型,其中随机森林算法表现最优。可见,集成学习模型在恶意URL识别问题上具有应用价值。
因此,基于BP神经网络,设计并实现了命名数据网络的入侵检测方法。仿真结果表明,该方法对网络攻击的分类准确性和辨识效率较高。
随着互联网的发展,网络攻击成为日益重要的安全问题。钓鱼、木马、恶意软件等多种攻击类型,常常以恶意URL作为途径。因此,识别恶意URL对阻止各类网络攻击、维护网络安全具有重要意义。
恶意URL识别最传统的方法是黑名单方法,即将已知的恶意URLs建立黑名单,并通过多种手段进行维护,从而根据黑名单直接判断待检测URL是否为恶意。该方法简单直接,查准率高,但只能识别已有的恶意URL,查全率低,时效性差。在此基础上,一些启发式算法和基于网页内容的方法被提出,是黑名单方法的改进,但依然存在准确率低、规则制定难等问题。近年来,随着人工智能的发展,机器学习方法被应用于恶意URL检测,包括逻辑回归、支持向量机等。机器学习的特征提取和模型选择,很大程度上决定了最终检测效果的好坏。本文提出了一种特征选取方法,尝试多种机器学习模型,特别是几种近年来较为流行的集成学习模型,比较不同模型在同一测试集上的效果。第1章介绍实验的整体流程,包括数据集的获取、特征选择、模型选择和训练;第2章给出不同模型的实验结果,并进行对比分析;第3章对实验作出总结。
01
实验设计
1.1 实验流程
本实验由数据获取、特征选取、特征计算、模型训练以及结果分析等环节构成,流程如图1所示。
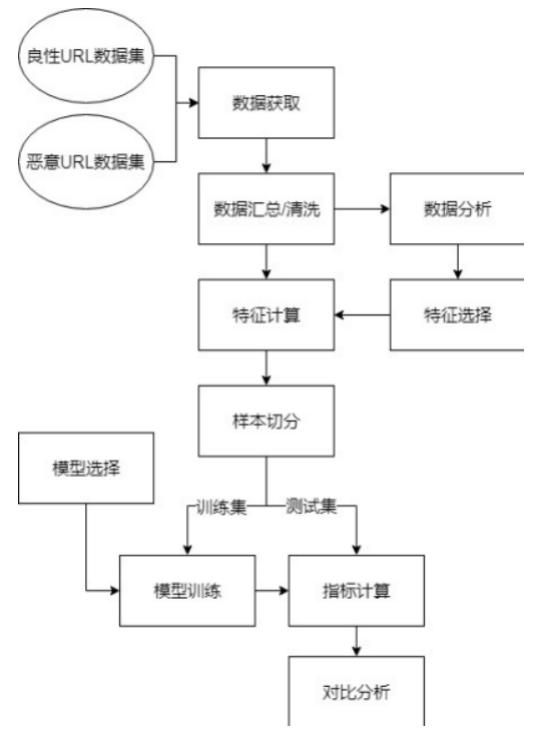
图1 实验总体流程1.2 数据获取
构建恶意URL的分类模型,需要恶意URL和良性URL的相关数据。本实验通过多种渠道进行数据收集工作。
(1)对恶意URL,实验从知名反钓鱼网站PhishTank使用爬虫获取经认证的恶意URL共计20 954条。
(2)对良性URL,实验从流量统计网站Alexa获取访问量排行前100万的所有网址,保留其中排名前1 000的网址,1 000至100万名的网址按一定比例进行抽样,共计获得18 900条良性URL。
(3)考虑到PhishTank提供的恶意URL仅包含钓鱼网站,实验还参考了开源数据集ISCX-URL-2016获取包括钓鱼、垃圾邮件、病毒等多种类型的恶意URL作为补充。将上述渠道获得的URL进行汇总、去重,得到实验最终使用的数据集,共包含76 446条数据。其中,恶意URL共计22 808条,占比29.8%;良性URL共计53 638条,占比70.2%,数据示例如表1所示。表1 数据示例

其中,标签为“1”表示该URL为恶意URL,标签为“0”表示该URL为良性。1.3 特征选取
通过分析1.2中所述恶意URL数据集,可以发现恶意URL往往具有某些共性。基于这些共性可以提取相关的特征,进而用于机器学习模型的训练。这里以URL长度这一特征为例,说明数据分析和特征选取的方法。观察大量恶意URL数据可以发现,攻击者常常使用很长的URL,试图掩盖URL中可疑的部分。例如:https://greatertuckertonfoodpantry.org/wp-users/?id=EgjC8KkaZh&email=renaud.chambolle。为从数据角度证实这一观点,分别画出恶意/良性URL的长度分布曲线,见图2。从图2可以较为直观地看出,恶意URL的平均长度更大,两类URL的长度分布存在明显差异。因此,URL的长度可以作为构建分类模型的一个重要特征。

图2 恶意/良性URL长度的分布
其余特征的分析方法类似,这里不再一一列出。经试验,最终总结出的重要特征如表2所示。表2 恶意URL分类模型的特征
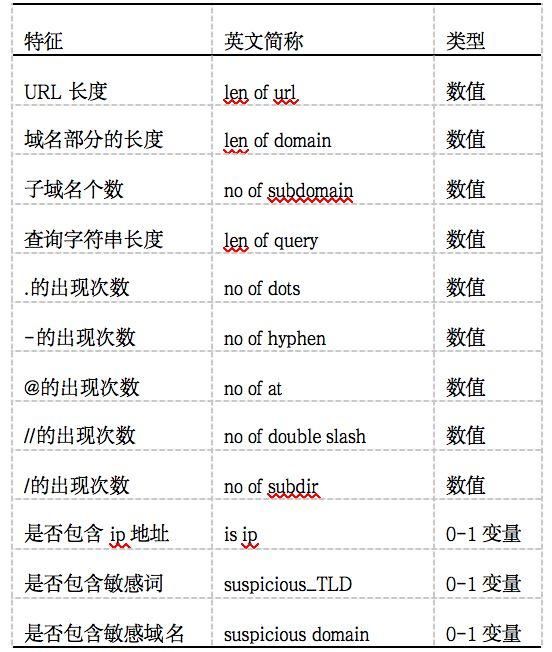
1.4 模型选择
近年来,集成学习(Ensemble Learning)在大规模数据集上的良好表现,使其成为传统机器学习领域最流行的方法。集成学习的基本思想是先训练若干个弱分类器,再通过某种串行或并行方式将这些弱分类器组合起来,从而达到提高预测准确率的效果。基于组合方法和弱分类器的不同,有多种不同的集成学习模型。实验中选取几种最具代表性的集成学习算法进行研究,包括梯度提升算法(Gradient Boosting)、AdaBoost、随机森林(Random Forest)和XGBoost。在集成学习算法以外,实验还选取了几种经典的机器学习算法,包括决策树(Decision Tree)、朴素贝叶斯(Gaussian NB)和逻辑回归(Logistic Regression),以进行对比研究。
02
实验结果
2.1 评估方法
实验将1.2中所述数据集进行划分,随机抽取其中20%作为测试集,其余作为训练集和交叉检验集。测试集共包含15 290条训练数据,将恶意URL作为正样本,良性URL作为负样本。评价分类模型好坏的常见指标有准确率(Precision)、召回率(Recall)、正确率(Accuracy)和F1值(F1-score)。由于恶意URL往往具有严重威胁,在对比各模型好坏的过程中,优先考虑召回率,其余指标作为参考。各常见指标的含义或计算方法如表3所示。表3 分类模型的常用评估指标

此外,为了更直观地对比各模型的好坏,绘制各模型的受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)并进行对比。
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR),纵坐标为真阳性率(True Positive Rate,TPR),描述了在一定制约下模型所能达到的预测准确率。真/假阳性率的定义为:

ROC曲线下面积(Area under ROC Curve,AUC)是指ROC曲线与横坐标轴围成的面积大小。AUC值越大,代表模型的分类效果越好。AUC值受正负样本分布变化的影响较小。实验使用的数据集与真实情景下正负样本的分布可能差异较大,因此AUC值是一项重要的评估指标。2.2 结果分析为控制无关变量,各模型训练时的迭代次数均采用默认参数,其余训练参数简单调优或使用默认值。各模型的实验指标由表4列出,其中每一项的最优值用*标明。表4 不同机器学习模型的实验指标

实验结果表明,集成学习算法的整体表现优于传统机器学习算法。其中,梯度提升算法(Gradient Boosting)有最高的预测准确率,而XGBoost算法有最高的正确率,随机森林算法(Random Forest)在召回率、F1值、AUC值3项指标上均为最优。综合来看,随机森林算法是研究算法中解决恶意URL识别问题的最优模型。在传统机器学习算法方面,决策树算法(Decision Tree)表现尚可,而朴素贝叶斯算法(GNB)和逻辑回归算法(Logistic Regression)则表现不佳。此外,不同机器学习模型的ROC曲线如图3所示。
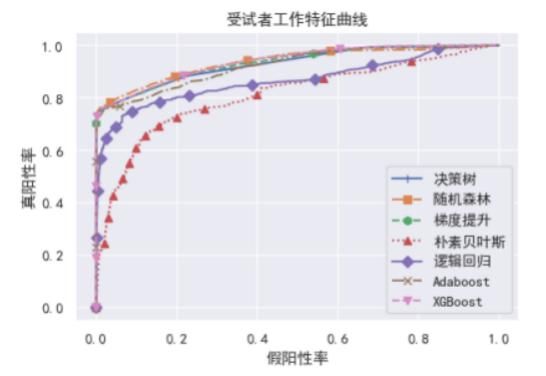
图3 不同机器学习模型的ROC曲线
由ROC曲线得到的结论类似,即在解决恶意URL识别问题上,集成学习方法的整体表现优于传统机器学习方法。
03
结 语
本文对不同机器学习模型在恶意URL识别问题上的应用进行了研究。实验结果表明,集成学习方法在恶意URL识别问题上的效果优于传统机器学习模型。其中,随机森林算法综合表现最优,能够达到76.26%的召回率和95.88%的准确率,表明集成学习方法在恶意URL的识别领域具有应用价值。本文使用的数据集规模偏小(76 446条数据),在训练集成学习模型时会出现过拟合等问题。可以预期,随着训练数据的扩充和硬件水平的提高,集成学习方法在恶意URL识别问题上能够取得更好的效果。作者简介 >>>
李泽宇(1994—),男,硕士,主要研究方向为网络安全;
施 勇(1979—),男,博士,讲师,主要研究方向为网络安全、网络攻防;
薛 质(1971—),男,博士,教授,主要研究方向为计算机通信网、网络安全。
选自《通信技术》2020年第二期 (为便于排版,已省去原文参考文献)