YOLOv5学习记录(一): 训练自己的数据模型
目录
前言
一、准备
1.安装Anaconda
2.安装Pytorch
3.下载源码及相关依赖库
4. 数据集准备
4.1、数据标注
4.2、准备labels
4.3、修改配置文件
二、模型训练
总结
前言
本篇内容主要叙述如何运用YOLOv5来训练自己的数据集。
一、准备
-
安装Anaconda;
-
安装pytorch;
-
下载源码及相关依赖库;
-
数据集准备;
1.安装Anaconda
下载地址:Anaconda
安装教程:Anaconda详细安装及使用教程
安装成功后创建一个独立的环境专门用来完成训练。
conda create -n torch107 python=3.7出现提示
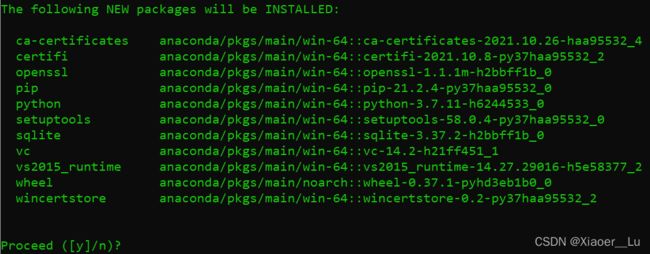
选择Y,等待相关依赖库的安装;
安装完成后,激活环境:
activate torch1072.安装Pytorch
本文基于YOLOv5 6.0版本,对于Pytorch版本要求pytorch1.7.0及以上
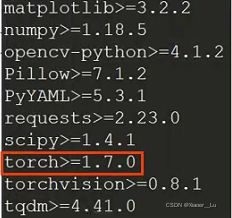
如果需要GPU,配置CUDA请请参考:win10下CUDA和CUDNN的安装
配置完成在环境中输入以下命令,即可安装Pytorch,CUDA修改为自己的版本:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html安装完毕,输入python及下方代码,检验CUDA是否可用:
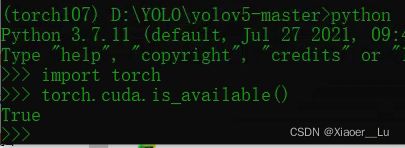
import torch
torch.cuda.is_available()3.下载源码及相关依赖库
下载地址:ultralytics-YOLOv5
本文是基于YOLOv5 6.0版本进行测试,6.0版本在后续Android端部署比较友好。
下载解压后,cmd进入根目录并激活环境torch07
安装所需的依赖库:
pip install -r requirements.txt4. 数据集准备
4.1、数据标注
数据标注可以采用labelImg,安装及使用教程请参考windows下使用labelImg标注图像
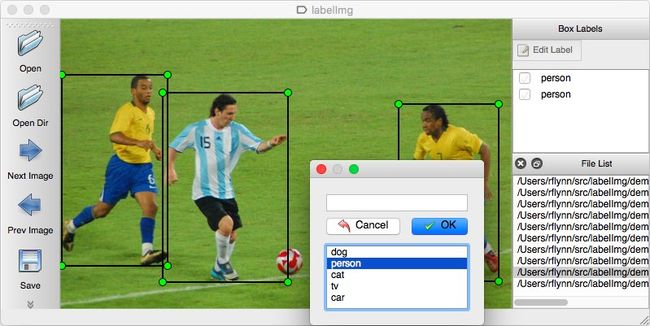
(注:这里说明一下,使用labelImg可以直接生成YOLO模型所需的txt文件。我们实际采用的数据,是在前人标注的人脸数据集上剔除了不必要的信息,并且原标注文件中无对应图片的尺寸信息,无法实现归一化。所以我们使用脚本将原标注文件和图片进行了处理,转成了xml格式文件,重新制作了数据集。这里以xml格式为例,顺便讲解一下xml格式文件如何转为txt格式文件。)
在yolov5-master/data下面新建三个文件夹
data
..images #存放图片
..Annotations #存放图片对应的xml文件
..ImageSets/Main #之后会在Main文件夹内自动生成train.txt,val.txt,test.txt和trainval.txt四个文件,存放训练集、验证集、测试集图片的名字(无后缀.jpg)
示例如下:
data文件夹下内容:

文件夹Annotations,放置labelImg的标注文件.xml(主要包含标注框的位置及图片信息):
文件夹images,放置图片数据.jpg,图片与标注文件一一对应。

文件夹ImageSets下创建Main子文件夹,用来存放训练集、验证集、测试集图片的名字,通过脚本生成,在data文件夹下创建maketxt.py文件,代码内容如下:
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
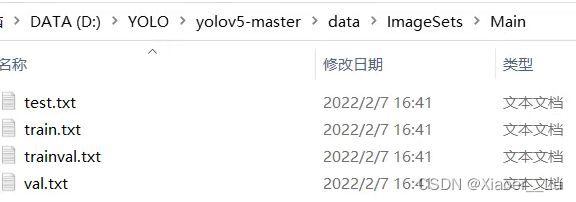
ftest.close()运行上述代码,将会在ImageSets/Main文件夹下生成四个txt文件(存放图片的名字(无后缀.jpg)):
4.2、准备labels
将数据集转换为YOLO训练所需的格式,在yolov5-master目录下创建voc_label.py文件,
代码内容如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['0', '1']
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()该代码主要是把每张图片对应的xml标注文件归一化,每一行为图片中的一个目标信息,依次表示:类别标签、目标框中心x、目标框中心y、目标框宽度、目标框高度;
最终生成的txt文件内容如下:
![]()
4.3、修改配置文件
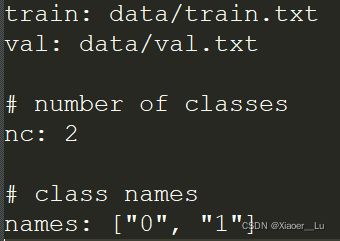
在yolov5-master/data文件夹下新建myeye.yaml(文件名可自行定义),用来指定训练集与验证集,同时设置目标的类别和数目,myeye.yaml内容如下:
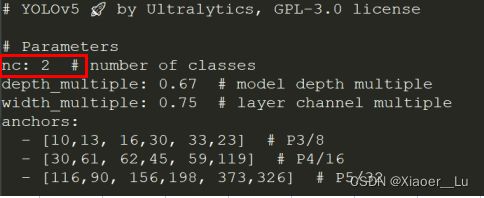
接下来选择并修改训练所需要的模型,在yolov5-master/model文件夹下,有s、m、l、x版本的模型,模型架构逐渐增大,相应地,训练时间也会随之增加,我选择的yolov5m.yaml,只需要在文件中将nc,也就是类别数修改为自己的数目,下方的anchors我采用默认状态,在windows平台上检测是没有问题的。
(但是这个地方在后面移植到别的平台,比如Android上面的时候会出现检测不出来或者出现多次检测且检测框大小不对的问题。经过查询,yolov5 6.0版本会自动根据你的数据集标注框重新计算anchors,如果在开始训练的时候没有加上关闭重新计算的命令,在移植的时候需要按照自己的anchors更改Android工程源码中的值,这个后面讲述平台移植部署时再详细介绍。)
至此,所有前期工作准备完毕,接下来就是训练了。
二、模型训练
在yolov5-master目录下激活环境torch107,运行以下命令即可开始训练:
python train.py --img 640 --batch 16 --epoch 300 --data data/myeye.yaml --cfg models/yolov5m.yaml --weights weights/yolov5m.pt --device 0train.py中需要设置的部分参数含义如下:
img-size:输入图片宽高;
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch;
epochs:训练过程中整个数据集将被迭代多少次;
data:存储训练、测试数据的文件;
cfg:存储模型结构的配置文件;
weights:权重文件路径;
device:cuda device,i.e. 0 or 0、1、2、3 or cpu;

训练开始会在yolov5-master目录下生成一个runs文件夹,训练好的模型存放在runs/train/exp/weights下面,同时我们也可以利用tensorboard对训练进程进行可视化,命令内容如下:
tensorboard --logdir=./runs/train/exp4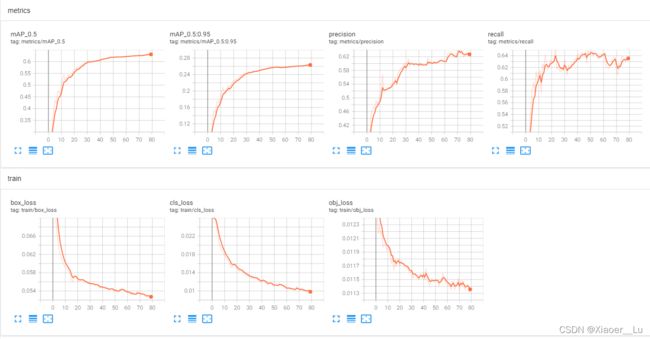
根据官方的检测指令,支持多种图像和视频流检测,best.pt为训练出来的模型,记得修改为自己的路径,命令如下:
python detect.py --weights best.pt --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube video
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
总结
以上就是今天要讲的内容,本文仅仅简单介绍了yolov5 6.0版本训练自己数据集的大致流程。后续会继续介绍如何将训练好的模型部署在Android平台。
针对以上讲述,各位有什么问题可以在评论区留言,互相学习交流!
参考:
手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测 - 知乎 (zhihu.com)
(2条消息) YOLOv5训练自己的数据集(超详细完整版)_深度学习菜鸟的博客-CSDN博客_yolov5训练自己的数据集
【小白CV】手把手教你用YOLOv5训练自己的数据集(从Windows环境配置到模型部署) (icode9.com)