深度学习使用GPU问题
深度学习如何使用GPU
- 什么是GPU
- 为什么GPU更适合深度学习
- CPU与GPU区别
- 什么是CUDA
- 什么是TensorRT
-
- 为什么TensorRT可以让底层模型加速呢
- 如何在linux查看GPU利用率,与线程
-
- 程序中进程
- 深度学习中那些参数影响GPU占用
什么是GPU
GPU,即“图形处理单元”,是仅用于特定任务计算机的微型版本。与CPU不同的是, 它可以同时执行多个任务。 GPU带有自己的处理器,该处理器嵌入与v-ram或video ram耦合的主板上,并且具有通风和冷却的散热设计。
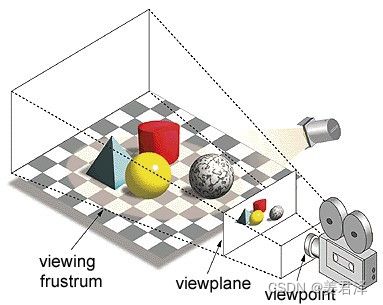
术语“图形处理单元”中的“图形”是指在二维或三维空间上的指定坐标处渲染图像。 视口,或视点,是观察者根据所使用的投影类型看物体的角度。 栅格化和光线跟踪是渲染3d场景的一些方法,这两个概念都是基于一种称为透视投影的投影类型。 那么什么是透视投影呢?
简而言之,透视投影是一种在视线或画布上形成图像的方法,其中平行线会聚到称为“投影中心”的会聚点,而且当对象从视点移开时,它看起来会变小。这正是我们的眼睛感受现实世界中的方式,帮助我们理解图像的深度。这也是它产生逼真的图像的原因。
为什么GPU更适合深度学习
GPU最大的特点是能够并行计算进程。 也是因为GPU的出现,有了并行计算这个概念。CPU通常按顺序方式完成其任务。 一个CPU可以有多个内核,每个内核一次承担一个任务。 假设一个CPU有2个内核,那么两个不同的任务流程可以在这两个内核上同时运行,从而实现多任务处理。
但是在每个内核上,这些过程仍然以串行方式执行。
CPU与GPU区别
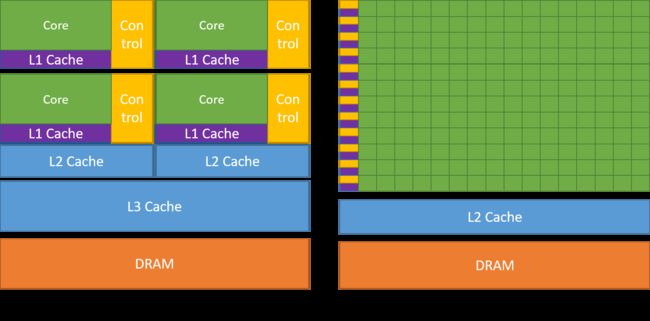
如前所述,CPU被划分为多个内核,因此它们可以同时执行多个任务,而GPU拥有成千上万个内核,所有这些内核都专用于单个任务。 这些任务通常是执行一些简单且频繁的计算,并且彼此独立。 两者都将经常需要的数据存储到相应的缓存中,因此都遵循“位置参考”的原理。
在GPU市场中,有两个主要参与者,即AMD和Nvidia。 Nvidia GPU被广泛用于深度学习,因为它们在论坛软件,驱动程序,CUDA和cuDNN中具有广泛的支持。 因此就AI和深度学习而言,Nvidia长期以来一直占领先锋位置。
神经网络可并行化,这意味着神经网络中的计算可以轻松地并行执行,并且彼此独立。
什么是CUDA
CUDA代表“计算统一设备体系结构”。该体系结构于2007年推出,您可以通过这种方法实现并行计算,并以优化的方式充分利用GPU的性能,从而在执行任务时提高性能。
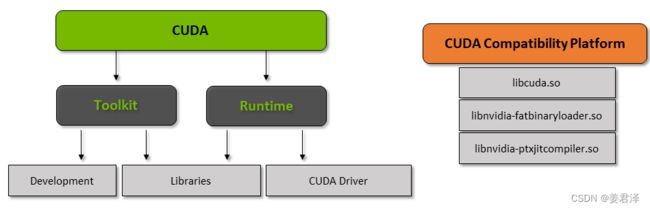
CUDA工具包是一个完整的软件包,其中包含一个开发环境,该开发环境用于构建使用GPU的应用程序。
什么是TensorRT
TensorRT是NVIDIA推出的一个高性能的深度学习推理框架,可以让深度学习模型在NVIDIA GPU上实现低延迟,高吞吐量的部署。TensorRT支持Caffe,TensorFlow,Mxnet,Pytorch等主流深度学习框架。TensorRT是一个C++库,并且提供了C++ API和Python API,主要在NVIDIA GPU进行高性能的推理(Inference)加速。
为什么TensorRT可以让底层模型加速呢
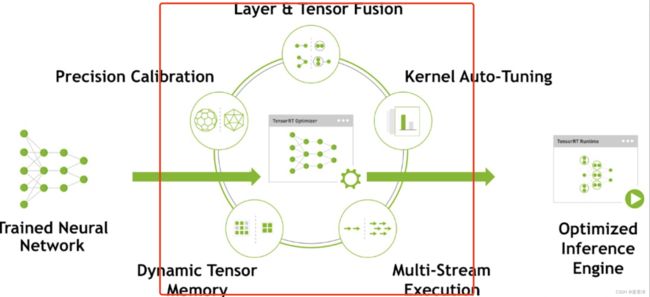
如上图看到,我们训练的模型(trained Neural Network)导入到TensorRT进行一系列优化,比如:
- TensorRT支持FP16和INT8的计算。我们知道深度学习在训练的时候一般是应用32位或者16位数据,TensorRT在优化的时候可以降低模型参数的位宽来进行低精度推理,以达到加速推断的目的,很像模型的压缩的量化方法
- TensorRT对于网络结构进行重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。
- kernel Auto-Tuning:分纵向融合和横向融合,纵向融合通过融合相同顺序的网络层来减少kernel launch,横向融合挖掘输入数据且filter大小相同但weights不同的层,对于这些网络层,使用一个kernel来提高加速。
- 去除掉网络concat层,通过预分配输出缓存以及跳跃式写入方式来避免这次转换
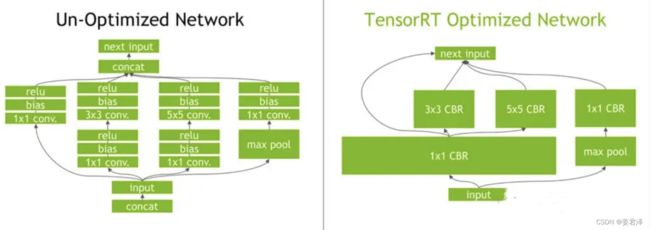
以下图网络优化前后为例:
如何在linux查看GPU利用率,与线程
回到深度学习训练中,因为深度学习通常需要大量的算力。因此通常会选择使用GPU服务器来完成模型的训练,预测,部署等等。
使用如下命令,可以查看自己GPU的使用情况,下图红色框为重要的信息
nvidia-smi
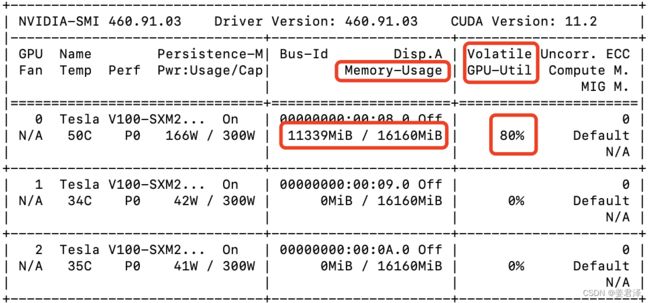
| 参数 | 参数解释 |
|---|---|
| GPU | 本机编号 |
| Fan | 风扇转速给服务器散热的,N/A表示没有风扇 |
| Name | GPU类型 |
| Temp | GPU温度 |
| Perf | GPU的性能状态 |
| Memory-Usage | 显存使用率 |
| Volatile GPU-Util | GPU使用率 |
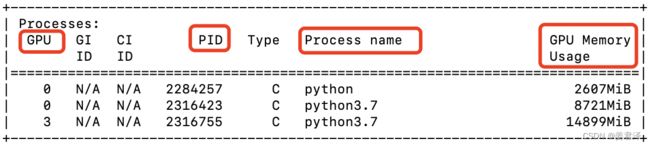
| Processes | |
|---|---|
| PID | 进程号 |
| Process name | 显存占用情况 |
持续观察GPU状态:nvidia-smi -l 秒数,
nvidia-smi -l 10
监控GPU写入到文件,指定需要的字段写入到文件中,通过这二种方法,可以实时查看自己的GPU使用情况,在训练模型时候,就能看到选择什么样的参数,训练,GPU情况。
nvidia-smi -l 1 --format=csv --filename=report.csv --query-gpu=timestamp,name,index,utilization.gpu,memory.total,memory.used,power.draw
| 参数 | 参数解释 |
|---|---|
| -l | 间隔几秒输出一条记录 |
| -format | 记录文件格式csv |
| -filename | 记录文件名称 |
| -query-gpu | 需要记录那些信息到文件中 |
| timestamp | 时间戳 |
| memory.total | 显存使用情况 |
| utilization.gpu | GPU使用率 |
| power.draw | 显存功耗 |
在程序中我们模型训练预测,启动的py文件通常是一个进程,一个进程包含了许多的线程PID(包含读取数据,更参数等等)
程序中进程
查看进程,显示的名称就是运行的程序文件.py,以python
ps -ef |grep python
深度学习中那些参数影响GPU占用
深度学习中模型自身参数、优化器参数、模型的每层输入输出,都会占用GPU的资源,一般以每一批(batchsize)的数据传输到模型开始,模型进行训练,产出模型参数,和优化器占用GPU显存,模型越大,对应的参数就越多。
那模型的输入,第一层就会是我们自己的数据,比如做计算机视觉常用的图片
batch_size 就是让模型在训练过程中每次选择批量的数据来处理,
batchsize的大小一般是2的n次方
一次训练所选取的样本数,会占用GPU显存的,因此如果batch_size过大,一次传入训练的数据过多,GPU就会显存占用,显存利用率增大了,但是可能显存容量不足,因为显存还要保存此次batch_size训练模型的参数,优化器参数等等,以BERT模型为例就需要340M的空间来存储模型参数

一次训练批次的数量 = 训练集 n b a t c h s i z e 一次训练批次的数量=\frac{训练集n}{batchsize} 一次训练批次的数量=batchsize训练集n
显存占用 = 模型自身参数 × n + b a t c h s i z e × 输出参数量 × 2 + 一个 b a t c h 的输入数据(往往忽略) 显存占用 = 模型自身参数 × n + batch size × 输出参数量 × 2 + 一个batch的输入数据(往往忽略) 显存占用=模型自身参数×n+batchsize×输出参数量×2+一个batch的输入数据(往往忽略)
模型训练时,GPU等待CPU传输数据过来,当从总线传输到GPU之后,GPU逐渐计算起来,利用率增高,但GPU算力很强大,很快就处理完传输来的数据,等待下一批batch数据传输,这时候就可以使用多线程传输数据。
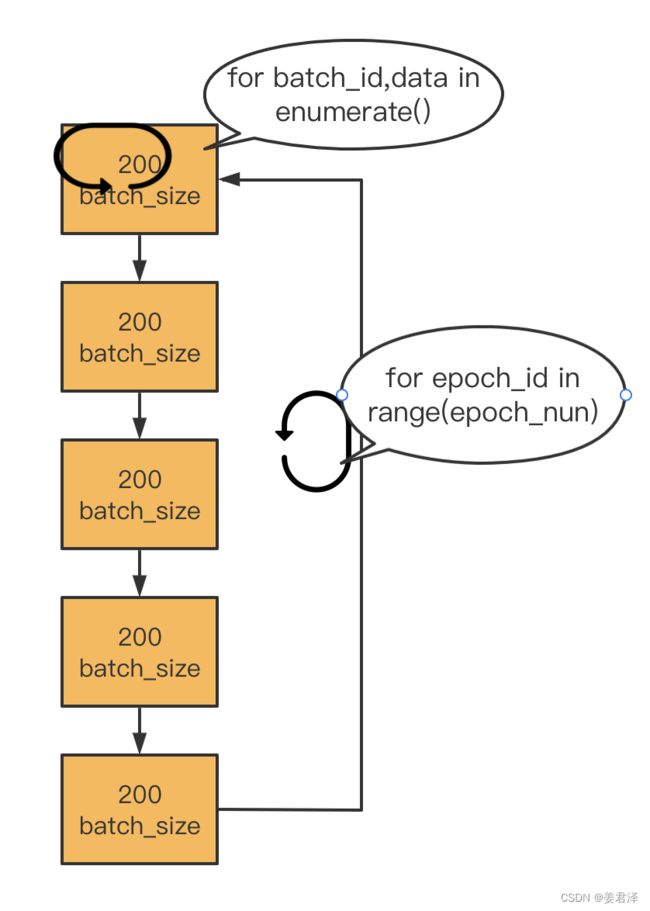
另外在神经网络训练,Epoch、Iteration这二种参数也是非常重要的:
- batchsize:批次大小,每次训练取训练集中一个批次进行训练
- iteration:iteration表示迭代个数代表一个batchsize批次要训练几次,一个迭代=一次模型网络正向传递+一个次模型网络反向传递
- epoch:epoch的个数代表整个训练集压要训练几次
但在模型训练时经常会遇到一个问题,模型加载数据后,模型的训练时发生报错,这个时候,数据其实已经读入到线程中,GPU显存是被占用的,这个显存GPU自己是无法释放的,如果只是查询GPU信息的话(nvidia-smi),是无法查到这里因为报错卡在读取数据的线程的。
如何删除这些线程方法如下:
输入如下命令,可以查看GPU隐藏的线程:
fuser -v /dev/nvidia*
删除线程命令PID
kill -9 [PID]
这里科普一下深度学习中,读数据的二种读取方式:
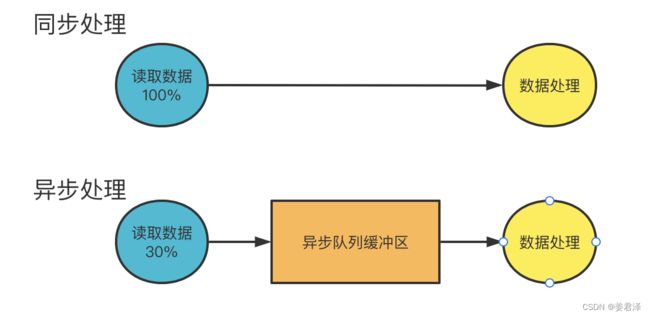
- 同步读取数据:也就是一个batchsize的数据,GPU要先读取完最后一张图片,才开始模型训练
- 异步读取数据:边读取一个batchsize过程中,读多少,就多少先拿去模型训练。