ICCV 2021 | Y-Net:轨迹-场景信息的真正融合
今天没有多余的解释,直接开始吧~
1. Y-Net网络结构
Y-Net的网络结构长什么样子呢?Y-Net的网络结构就长下图这样子。看上去我好像在自言自语,其实你仔细揣摩就会发现,我真的是在自言自语。可以看到说,Y-Net网络输入的是一张张的图片,而不是序列。这一点很重要的,因为只有先搞清输入输出是什么,才能进行接下来的工作。那在(一)中的时候说,对于给定的RGB三通道图片 ,先通过语义分割网络得到图片的语义分割图
,先通过语义分割网络得到图片的语义分割图 ,于此同时将行人的过去轨迹转化为轨迹热力图
,于此同时将行人的过去轨迹转化为轨迹热力图 ,然后将语义分割图与轨迹热力图进行concatenate拼接,之后送到我们的编码器
,然后将语义分割图与轨迹热力图进行concatenate拼接,之后送到我们的编码器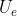 当中。编码器的最终输出
当中。编码器的最终输出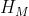 作为解码器
作为解码器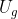 、
、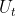 的输入,的中间特征
的输入,的中间特征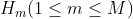 将与俩解码器的中间层输出进行skip connection,也就是进行特征融合。在Goal & Waypoint decoder中,最后的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对goal 和 waypont生成一个概率分布,从这个概率分布中采样我们所需的goal 和 waypoint,紧接着将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为
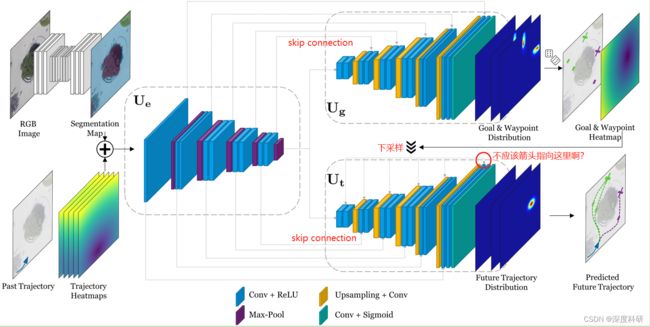
将与俩解码器的中间层输出进行skip connection,也就是进行特征融合。在Goal & Waypoint decoder中,最后的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对goal 和 waypont生成一个概率分布,从这个概率分布中采样我们所需的goal 和 waypoint,紧接着将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为 。最后,对向量进行下采样以匹配中每个block的空间尺寸(从图中来看是要下采样6次,但是最后一个下采样箭头是不是画错位置了呢?另外,匹配的意思指的是”拼接“,而不是”输入“)
。最后,对向量进行下采样以匹配中每个block的空间尺寸(从图中来看是要下采样6次,但是最后一个下采样箭头是不是画错位置了呢?另外,匹配的意思指的是”拼接“,而不是”输入“)
2. encoder
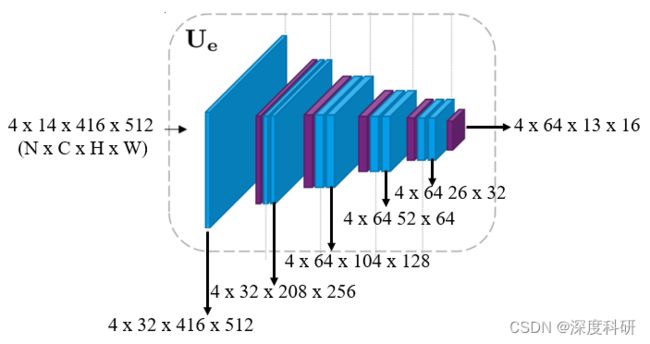
我们知道,编码器要干的事情就是提取图片的深层特征。Y-Net的encoder架构很显然是仿照U-Net encoder所设计的,encoder的输入是Segmentation Map与Trajectory Heatmap所拼接的张量tensor,那这个tensor的维度是多少呢?那我们先给定这个tensor的维度是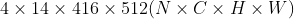 。每一层的输出如下图所示:
。每一层的输出如下图所示:
3. decoder
解码器实际上就是要恢复原图的大小,并融合深层的特征。那解码器是怎么实现该功能的呢?从图中我们可以看到,首先会被送到的center block当中去,然后再将center block的输出送到接下来的模块。接下来的模块是反卷积——skip connection——卷积的重复操作。
我们来看前向传播过程:在encoder的前向传播代码中,会将六层的future特征预存在feature[ ]中,这是为了在decoder中方便进行特征融合。读过U-Net的朋友应该知道,特征融合应该有相同的维度(当然channel数可以不同)。所以在的前向传播过程中,首先将encoder保存的特征进行逆排序,然后将feature进行切片——也就是代码中的feature[0]——赋给center_feature。经过两层卷积后以center_feature的输出维度作为后续block的输入x。在for循环当中,enumerate()是枚举函数,zip()函数将对应的元素打包成一个个元组,F.interpolate()对输入的x进行插值,为接下来上采样做准备;torch.cat()将encoder中间层的特征与decoder进行concatenate拼接,拼接好后输入到module()模块,该模块在decoder该类中有所定义,实际上就是decoder架构中反卷积后的两层卷积层。在for循环完之后,有一个self.predictor(),同样得,它在decoder该类中有定义,实际上就是的输出层,经过它我们将得到goal $ waypoint heatmap logits.
每一层的输出如下:

4. decoder
上面说过, 将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为。最后,对向量进行下采样以匹配中每个block的空间尺寸。采样的过程该怎么用代码实现呢?
gt_waypoints_maps_downsampled = [nn.AvgPool2d(kernel_size=2**i, stride=2**i)(gt_waypoint_map) for i in range(1, len(features))]
gt_waypoints_maps_downsampled = [gt_waypoint_map] + gt_waypoints_maps_downsampled 采样的结果将保存在列表里,将随、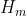 一同输入到当中:
一同输入到当中:
traj_input = [torch.cat([feature, goal], dim=1) for feature, goal in zip(features, gt_waypoints_maps_downsampled)]
pred_traj_map = model.pred_traj(traj_input) 这一行代码一定要注意,得到的traj_input的输出为:(4,33,416,512),(4,33,208,256),(4,65,104,128),(4,65,52,64),(4,65,26,32),(4,65,13,16),从代码中我们可以看到,zip()函数将来自的特征即该行代码里的feature,与对下采样的结果打包成了元组,然后再进行concat拼接得到traj_input的输出。所以,待会在前向传播的时候,已经有了来自下采样的拼接,所以我希望读者看到这的时候不会疑惑。
的网络结构与并没有太大区别,不同的是的输入除了之外,还有下采样的结果。前向传播的过程与是一样的,这里就不在赘述。每一层的输入输出如下:
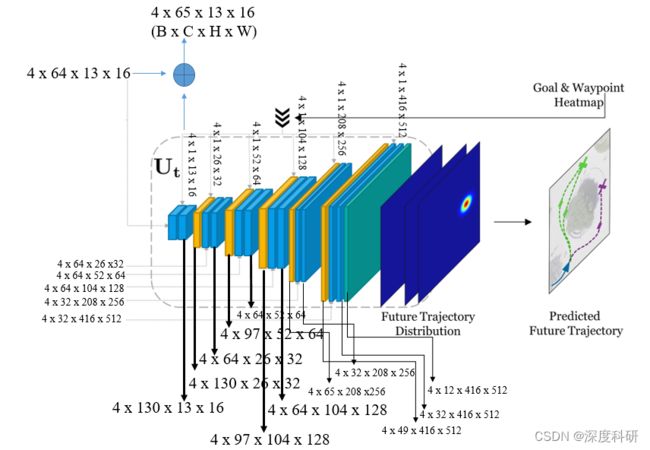
5. 训练与测试
那回顾之前对Y-Net的描述,读者会发现说,其实我并没有涉及对算法很具体的描述,只弄一弄输入输出是提高不了博客质量的。这篇文章是很早之前写的,那现在来将算法描述清楚。现在是2022年10月25日,是的,没有看错,过去了很久的时间。
Y-Net网络架构是很特别的,为什么这么说呢?在Y-Net之前,行人轨迹预测的论文对行人与场景、行人与行人之间的交互都是简单的将其放在一个大矩阵里,然后喂给相应的模型进行特征融合,再经过某种处理得到最后的预测轨迹,这种模式相当于:轨迹——Pooling——轨迹。但是Y-Net通过将轨迹映射到特征图的方式做到了真正的融合,这种模式相当于:轨迹——Mapping——轨迹,这是一种很大胆的创新。
在开始之前,论文中几个符号的含义请务必弄清:
①
:goal的数目
②
:到达某个goal的路径数目
③
:waypoint的映射图
④waypoint:到达某个goal中途的点
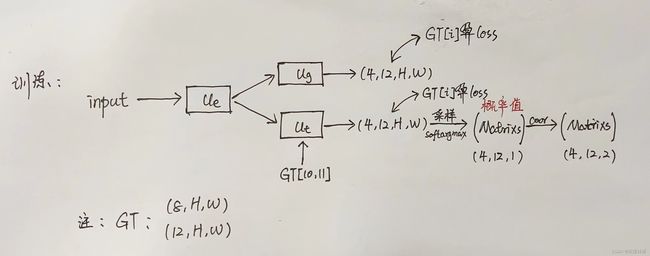
Y-Net训练与测试存在一定的不同。举例来说,在训练阶段,轨迹heatmap与场景图叠加后作为模型的输入![]() ,经过、处理得到
,经过、处理得到![]() 大小维度的输出。这一步实际上可以将U-Net视为预测部件,输入8帧(张)图片,得到后续12帧(张)的图片。模块的输入来自三个方面,一是最后一层的输出、二是来自下采样的拼接、三是与中间层的跳跃连接。一、三方面的输入是固定的,变化的是第二方面的输入。举例来说,假定超参数
大小维度的输出。这一步实际上可以将U-Net视为预测部件,输入8帧(张)图片,得到后续12帧(张)的图片。模块的输入来自三个方面,一是最后一层的输出、二是来自下采样的拼接、三是与中间层的跳跃连接。一、三方面的输入是固定的,变化的是第二方面的输入。举例来说,假定超参数 ,
,![]() ,
,![]() ,需要解释的是上述超参数分别代表选取goal的数目、到达某个goal存在的路径数目以及选择GT的第10、11张heatmap图作为waypoint的map(注意:①训练阶段不引入goal的信息,或者换句话说直接将GT的第12张heatmap图作为goal的信息;②这里所说的GT的第10、11张图是指,人为的将GT heatmap分为前8张(0~8)与后12张(0~12))。训练阶段提供真实的第19帧轨迹坐标映射的heatmap与下分支的各个block进行拼接,经输出
,需要解释的是上述超参数分别代表选取goal的数目、到达某个goal存在的路径数目以及选择GT的第10、11张heatmap图作为waypoint的map(注意:①训练阶段不引入goal的信息,或者换句话说直接将GT的第12张heatmap图作为goal的信息;②这里所说的GT的第10、11张图是指,人为的将GT heatmap分为前8张(0~8)与后12张(0~12))。训练阶段提供真实的第19帧轨迹坐标映射的heatmap与下分支的各个block进行拼接,经输出![]() 大小的特征图,再对该输出特征图进行采样(softargmax)得到概率值经变换后得到预所有行人12帧下的预测坐标
大小的特征图,再对该输出特征图进行采样(softargmax)得到概率值经变换后得到预所有行人12帧下的预测坐标![]() 。请注意,这里的上分支的监督12个点,与GT算loss,得到goal_loss,下分支也监督12个点,也与GT算loss得到traj_loss。这里有意思的是:上下分支监督12个相同的点,那这两个loss有什么区别?并且也没有实现论文中所提及的
。请注意,这里的上分支的监督12个点,与GT算loss,得到goal_loss,下分支也监督12个点,也与GT算loss得到traj_loss。这里有意思的是:上下分支监督12个相同的点,那这两个loss有什么区别?并且也没有实现论文中所提及的![]() loss.
loss.
 Training
Training
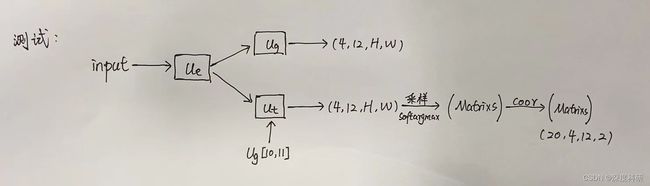
测试阶段,超参数,![]() ,
,![]() 不变,请注意这里
不变,请注意这里![]() 含义不同了:此时
含义不同了:此时![]() 的含义是选择输出
的含义是选择输出![]() 的第10、11张特征图作为采样heatmap和goal的map。读者可能很自然的想到,在第10张图片上采样waypoint,在第11张图片上采样goal。事实上,我们只需要在第11图片上采样就可以了。那为什么还需要第10张图片呢?这里就涉及具体编程时的逻辑语句。举例来说,如果只设置
的第10、11张特征图作为采样heatmap和goal的map。读者可能很自然的想到,在第10张图片上采样waypoint,在第11张图片上采样goal。事实上,我们只需要在第11图片上采样就可以了。那为什么还需要第10张图片呢?这里就涉及具体编程时的逻辑语句。举例来说,如果只设置![]() ,那len(
,那len(![]() )=1,相当于goal就是waypoint。没有waypoint什么事的话,那多尴尬啊。所以设置len(
)=1,相当于goal就是waypoint。没有waypoint什么事的话,那多尴尬啊。所以设置len(![]() )=2,就意味着waypoint与goal不可能重合。由于我们只在第11图片上采样,那为方便叙述,我们给它取名
)=2,就意味着waypoint与goal不可能重合。由于我们只在第11图片上采样,那为方便叙述,我们给它取名![]() ,它的大小为
,它的大小为![]() 。好,那怎么得到所需要的goal呢?一个不太直觉的想法是:在你得到的
。好,那怎么得到所需要的goal呢?一个不太直觉的想法是:在你得到的![]() 上进行采样。那采样(sampling)这件事怎么又该怎么操作呢?举例来说,我们首先会将
上进行采样。那采样(sampling)这件事怎么又该怎么操作呢?举例来说,我们首先会将![]() 进行平铺的操作,得到维度大小为
进行平铺的操作,得到维度大小为![]() 的概率矩阵,行数4代表着4位行人,列数实际上是每一张概率图的展平。现在假定我们要取样20个点,也就是n_sample = goal = 20,我们利用torch.multinomial函数对该矩阵的每一行随机采样20次,返回每次采样概率所在行的位置,那这样我们就得到了一个大小为
的概率矩阵,行数4代表着4位行人,列数实际上是每一张概率图的展平。现在假定我们要取样20个点,也就是n_sample = goal = 20,我们利用torch.multinomial函数对该矩阵的每一行随机采样20次,返回每次采样概率所在行的位置,那这样我们就得到了一个大小为![]() 的样本矩阵,4代表4个行人,20代表每一个行人采样20个样本点。到这里其实还不是我们想要的目的,你想想,我们要采样样本点的目的实际上是想得到每个goal的坐标,所以我们还需要将
的样本矩阵,4代表4个行人,20代表每一个行人采样20个样本点。到这里其实还不是我们想要的目的,你想想,我们要采样样本点的目的实际上是想得到每个goal的坐标,所以我们还需要将![]() 的样本矩阵处理成最终的坐标形式,得到
的样本矩阵处理成最终的坐标形式,得到![]() (batch, 1, n_samples, dim)矩阵才是每一个goal在图中的像素坐标。
(batch, 1, n_samples, dim)矩阵才是每一个goal在图中的像素坐标。
现在goal有了,waypoint又该怎么得到呢?这里分情况讨论:第一种情况是你的![]() (注意的含义),此时goal就是waypoint,waypoint就是goal。第二种情况是你的
(注意的含义),此时goal就是waypoint,waypoint就是goal。第二种情况是你的![]() ,此时你还需要在
,此时你还需要在![]() 对waypoint进行采样,那采样的次数由什么决定呢?采样的次数由你预先设想的到每个goal有几条路径所决定,用直观的符号表示就是
对waypoint进行采样,那采样的次数由什么决定呢?采样的次数由你预先设想的到每个goal有几条路径所决定,用直观的符号表示就是![]() ,这里的就是到某个goal的路径数。有了采样的次数,你需要的就是在
,这里的就是到某个goal的路径数。有了采样的次数,你需要的就是在![]() 重复上述采样过程就可以得到waypoint的像素坐标。
重复上述采样过程就可以得到waypoint的像素坐标。
Anyway,到目前为止,我们有了goal的像素坐标,有了waypoint的像素坐标,紧接着就该将每个采样点的坐标映射到图中了吧。将每个采样点的坐标映射到图中这一操作具有普遍性,也就是说不管你是情况一还是情况二都是这么进行映射的,那具体怎么操作呢?举例来说在事先你会有一个距离模板矩阵,这个矩阵的大小是![]() ,该矩阵中的每一个数是网格索引到中心点的距离的归一化。这个模板矩阵的意义是:减少每个点映射到图中的计算量,举例来说要产生一个点到图的映射,待会你只需在做好的模板矩阵上截取patch就能够实现,而不需要繁杂的计算。这一过程用公式来表述为:
,该矩阵中的每一个数是网格索引到中心点的距离的归一化。这个模板矩阵的意义是:减少每个点映射到图中的计算量,举例来说要产生一个点到图的映射,待会你只需在做好的模板矩阵上截取patch就能够实现,而不需要繁杂的计算。这一过程用公式来表述为:
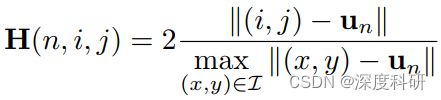
以第一种情况![]() 为例,超参数设置 ,
为例,超参数设置 ,![]() ,
,![]() 不变,采样得到waypoint
不变,采样得到waypoint![]() 和goal
和goal![]() 之后,我们将其Concatenate拼接起来
之后,我们将其Concatenate拼接起来![]() ,每一个样本映射到一张heatmap图,所以你的样本总数(20)有多少,就会有多少张heatmap图,并且每次循环只用一张heatmap,总共循环20次,每次循环最终的输出为
,每一个样本映射到一张heatmap图,所以你的样本总数(20)有多少,就会有多少张heatmap图,并且每次循环只用一张heatmap,总共循环20次,每次循环最终的输出为![]() 大小的矩阵,那堆叠20次循环的输出,最终得到的输出维度为
大小的矩阵,那堆叠20次循环的输出,最终得到的输出维度为![]() (n_samples, batch, seq_len, dim)
(n_samples, batch, seq_len, dim)
 Testing
Testing
那到这里,Y-Net也就结束了,这是一篇很有启发性的文章,代码非常优美,读者有时间一定要细看。