python 读取csv文件并输出柱状图(以iris数据集为例)
被半自动的直方图法气晕
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
data = pd.read_csv("iris.csv")
# 获取所有列,并存入一个数组中
ori_data = np.array(data)
#存储三种类别的list
list1 = []
list2 = []
list3 = []
max_num = 40
input_num = [0, 0, 0]
input_num1 = 0
data_num = 150
for i in range(data_num):
if (ori_data[i][5] == 'setosa') & (input_num[0] < max_num):
list1.append(ori_data[i])
input_num[0] = input_num[0] + 1
if (ori_data[i][5] == 'versicolor') & (input_num[1] < max_num):
list2.append(ori_data[i])
input_num[1] = input_num[1] + 1
if (ori_data[i][5] == 'virginica') & (input_num[2] < max_num):
list3.append(ori_data[i])
input_num[2] = input_num[2] + 1
#提取iris三个种类的数据集为四个部分并画图
def mission1(list,class_name):
data1 = [[], [], [], []]
#数据名
data_name = ["Sepal.Length","Sepal.Width","Petal.Length","Petal.Width"]
#提取4种数据
for i in range(len(list)):
for j in range(4):
data1[j].append(list[i][j+1])#数据特征
# arange(a,b,c)确定直方图x轴的范围及间距,a为最小值,b为最大值,c为间距
# 用plt.hist(a,b)绘制,a为数据,b为直方图的特性
for i in range(4):
print("序列", i)
plt.subplot(2, 2, i+1)
data = data1[i]
# print(data)
# 计算bin
a = int(max(data)*10/10)
b = int(min(data)*10/10)
c = a - b
bin = c + 1
#直接输出每个区间的值
num_count = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] #......代表统计范围是0-9
for j in range(len(data)):
flag = 0
# print("输入:",data[j], " 输出:", int(data[j]*10/10))
if int(data[j]*10/10) == b + flag:
num_count[b + flag] = num_count[b + flag] + 1
if int(data[j]*10/10) != b + flag:
for h in range(bin):
flag = flag + 1
if int(data[j]*10/10) == b + flag:
num_count[b + flag] = num_count[b + flag] + 1
break
#输出
x = []
y = []
for s in range(len(num_count)):
if num_count[s] != 0:
# print("区间: ", s, " 数量: ", num_count[s])
x.append(s)
y.append(num_count[s])
# print('max = ', max(data), 'min = ', min(data), 'minus = ', max(data) - min(data),'a = ', a, 'b = ', b, 'c = ', c, ' bin = ', bin)
plt.bar(x,y,align='center',color="c",tick_label=x)
# plt.hist(data, bin, (int(min(data)*10/10), int(max(data)*10/10)),rwidth = 0.6)
plt.xlabel('x')
plt.ylabel('num')
for X,Y in zip(x,y):
plt.text(X+0.05,Y+0.05,'%d' %Y, ha='center',va='bottom')
# plt.xticks(np.arange(int(min(data)*10/10), int(max(data)*10/10), 1))
plt.yticks(np.arange(0, 40, 2))
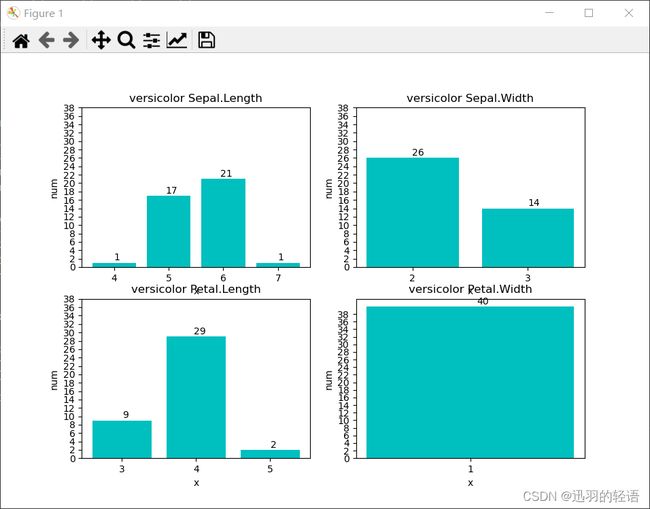
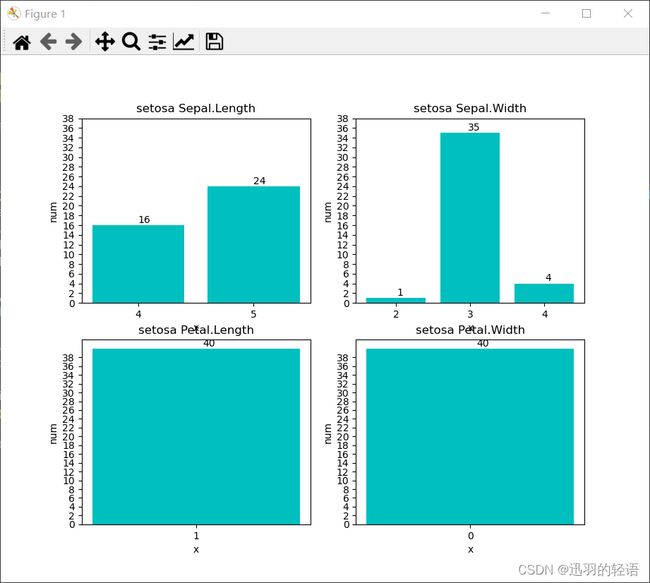
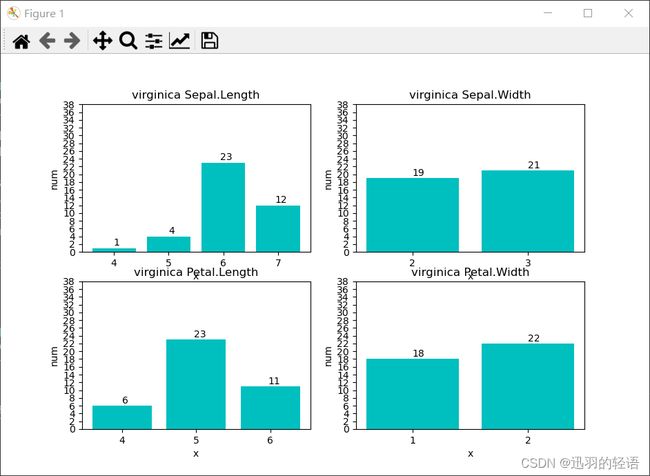
title = str(class_name + ' ' + data_name[i])
plt.title(title)
#计算概率估计表
for t in range(len(x)):
result1 = y[t] / max_num
print("范围", x[t], "Na/N", result1)
plt.show()
mission1(list1,'setosa')
mission1(list2,'versicolor')
mission1(list3,'virginica')