【pytorch】使用tensorboard进行可视化训练
【pytorch】使用tensorboard进行可视化训练
PyTorch 从 1.2.0 版本开始,正式自带内置的 Tensorboard 支持了,我们可以不再依赖第三方工具来进行可视化。此处例行介绍一下我使用的工具版本:
pycharm 2020.2.3 x64
pytorch 1.7.0
Anaconda3-5.2.0-Windows-x86_64
tensorboard官方教程地址:https://github.com/tensorflow/tensorboard/blob/master/README.md
目录
- 【pytorch】使用tensorboard进行可视化训练
-
- 1、tensorboard 下载
- 2、tensorboard 的使用
-
- 2.1 tensorboard 的打开
- 2.2 tensorboard 的用法
-
- SummaryWriter类
- add_scalar()和add_scalars()
- add_histogram()
- add_image()
- add_graph()
- 3、tensorboard 的实战演练
-
- 3.1 创建SummaryWriter对象
- 3.2 计算图的可视化
- 3.3 训练过程loss的可视化
- 3.4 训练过程卷积核以及输入输出图像的可视化
- 3.5 训练过程输出值的可视化
- 总结
- 参考资料
1、tensorboard 下载
step 1
此次tensorboard在pycharm的终端里下载。点击pycharm的终端(红圈处),并且输入activate pytorch激活之前安装了pytorch的环境。
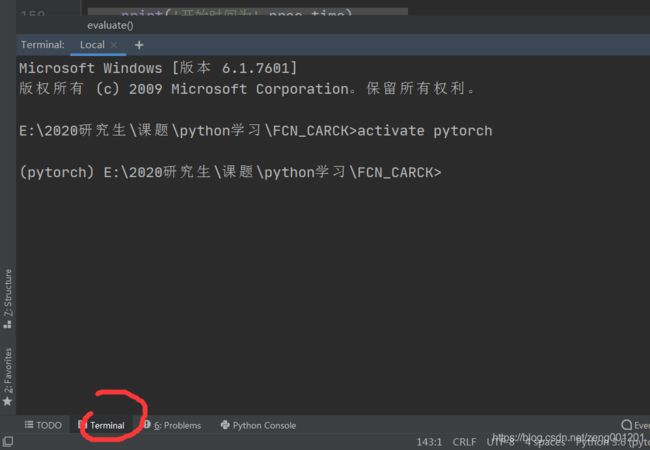
step 2
这里使用pip安装tensorboard,输入 pip install tensorboard
等待安装完后,再安装另外一个他需要依赖的库。
输入 pip install future.
安装完毕后,输入pip list查看是否安装成功。
下载成功后可用下述代码进行测试:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
2、tensorboard 的使用
2.1 tensorboard 的打开
这里也在pycharm的终端中打开tensorboard工具去读取event file。
step 1
打开pycharm的终端
step 2
在终端中输入 dir查看项目当前文件夹里的文件
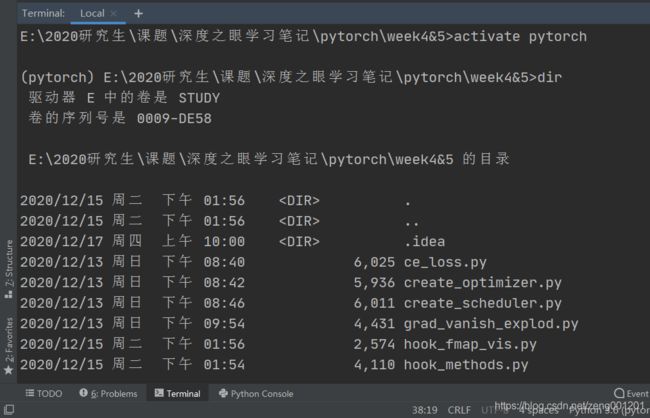
step 3
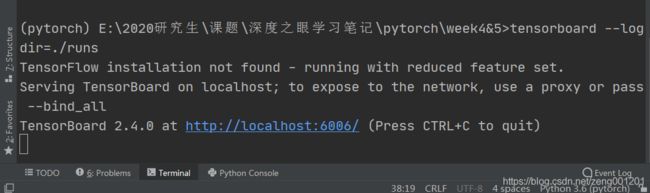
设置路径,输入tensorboard --logdir=./runs
./runs为想要可视化数据所在的文件夹路径
step 4
点击网址,打开tensorboard页面
2.2 tensorboard 的用法
SummaryWriter类
tensorboard 的SummaryWriter类:提供创建event file的高级接口,主要属性为:
主要的方法有:
add_scalar()和add_scalars()

add_scalars()用于创建多条曲线,用字典来记录数据与数据名。
add_histogram()

add_image()

add_graph()

3、tensorboard 的实战演练
3.1 创建SummaryWriter对象
一般在train.py中,在开始迭代计算前,创建SummaryWriter对象:
# 生成tensorboard可视化文件
ut = cfg.use_tensorboard
if ut:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='./tensorboard event file', filename_suffix=str(cfg.EPOCH_NUMBER),flush_secs = 180)
# log_dir 里为可视化文件所在位置路径,可用绝对路径,默认在runs
# filename_suffix 设置event file文件名后缀
# flush_secs 设置每隔多久将数据写入可视化文件中,默认120
3.2 计算图的可视化
在定义完网络后,在网络的.py文件中:
if __name__ == "__main__":
rgb = torch.randn(1,3,360, 640)
net = FCN_8s(2)
out = net(rgb)
print(out.shape)
# ________________________查看模型计算图
# 生成tensorboard可视化文件
ut = cfg.use_tensorboard
if ut:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir='./tensorboard event file',
filename_suffix=str(cfg.EPOCH_NUMBER),
flush_secs=180)
writer.add_graph(net, rgb)
writer.close()
运行后,点开pycharm的终端:
点击网址:
另外一种用于debug检查模型的方法:
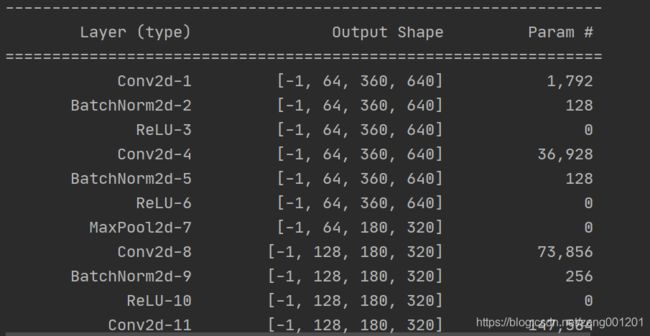
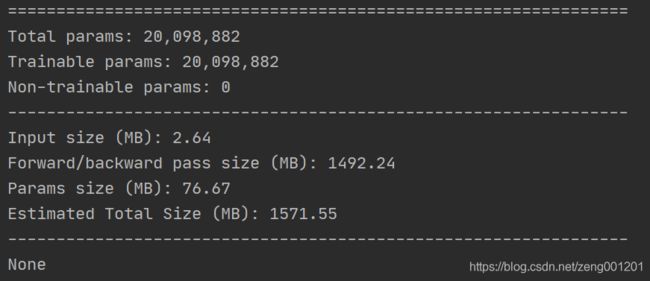
summary()可输出模型每层输入输出的shape以及模型总量。使用前需要在终端pip install torchsummary。

from torchsummary import summary
print(summary(net, (3, 360, 640), device="cpu"))
运行得到:
3.3 训练过程loss的可视化
在训练train.py文件中的,每次计算完loss后输出:
print(metric_description)
# 用tensorboard可视化Train Loss
if ut:
writer.add_scalar('Train Loss', train_loss / num_mini_batch, epoch)
writer.flush()
验证同理
3.4 训练过程卷积核以及输入输出图像的可视化
查看输出图像以及卷积核图像对语义分割具有重要作用。
1、对输入图片进行可视化:
import cfg
import data
from torch.utils.data import DataLoader
import torchvision
import kk_tools
train_img_path = cfg.TRAIN_ROOT
train_label_path = cfg.TRAIN_LABEL
transform_img = torchvision.transforms.Compose(
[
torchvision.transforms.Resize(32),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
traindata_path = data.CRACKdataset_path([train_img_path,
train_label_path],
cfg.crop_size,
transform_img)
train_loader = DataLoader(traindata_path,
batch_size=cfg.BATCH_SIZE,
shuffle=True,
num_workers=0)
# del_file(log_dir) # 删除原来存在的数据,删除文件夹
from torch.utils.tensorboard import SummaryWriter
logdir = 'checkphoto'
kk_tools.del_file(logdir)
writer = SummaryWriter(log_dir = logdir,
filename_suffix=str(cfg.EPOCH_NUMBER),
flush_secs=cfg.refresh_time)
i, sample = next(enumerate(train_loader))
img = sample['img'] # torch.Size([4, 3, 240, 360])
import torchvision.utils
img_grid = torchvision.utils.make_grid(img,nrow = 2,
normalize= False,
scale_each=False)
# nrow = 2 设置有2行
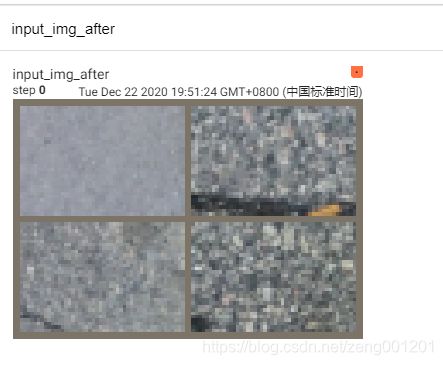
writer.add_image('input_img',img_grid,str(i))
_ = kk_tools.transform_invert(img_grid, transform_img ) # 处理normolize
kk_tools.dshow_picture(img_grid)
writer.add_image('input_img_after', img_grid, str(i))
writer.close()

2、对卷积核可视化:这里使用 torchvision.utils.make_grid()会有bug,详情看网址:https://github.com/pytorch/vision/issues/3025
要使用pytorch1.5版本的就不报错。
然后问了一个大神,改成酱就行了。改的方法看上面网址。下面是对第一个卷积进行是可视化,但是需要输入通道数是3的才可以,其他通道数不行,除非改成3通道数的。
from FCN_8s import FCN_8s
import torch
from torch import nn
import torchvision.utils
from torch.utils.tensorboard import SummaryWriter
net = FCN_8s(2)
net.load_state_dict(torch.load('best.pth'))
print(net.parameters())
kernel_num = -1 # 当前可视化层
vis_max = 1 # 最大可视化层
log_dir = 'kernelphoto'
del_file(log_dir)
writer = SummaryWriter(log_dir=log_dir)
for sub_module in net.modules():
if isinstance(sub_module,nn.Conv2d):
kernel_num += 1
if kernel_num > vis_max:
break
kernels = sub_module.weight # torch.Size([64, 3, 3, 3])
c_out,c_int,k_w,k_h = tuple(kernels.shape)
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
with torch.no_grad():
kernel_grid = torchvision.utils.make_grid(kernel_idx,nrow=c_int,
normalize=True,
scale_each=True,
)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, w
with torch.no_grad():
kernel_grid = torchvision.utils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()

3、对输出图像进行可视化:
需要借助hook函数来提取特征图进行可视化,在前向传播或者反向传播时,通过hook函数机制挂上额外的函数,获取或者改变特征图梯度。感觉这个对后续特征图的可视化不靠谱,因为这里的输出往往不是3通道的,酱如何可视化???

针对tensor张量的hook函数:

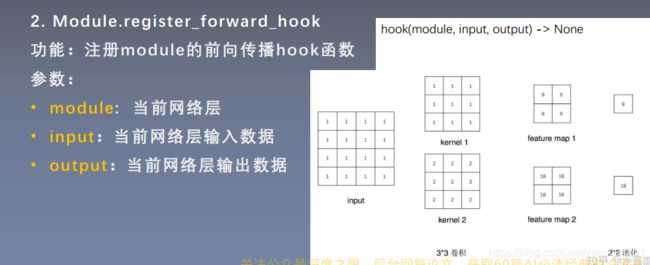
针对module网络模型的hook函数:


flag = 0
flag = 1
if flag:
import cfg
import data
from torch.utils.data import DataLoader
import torchvision
from FCN_8s import FCN_8s
from torch import nn
import torchvision.utils
import numpy as np
train_img_path = cfg.TRAIN_ROOT
train_label_path = cfg.TRAIN_LABEL
transform_img = torchvision.transforms.Compose(
[
torchvision.transforms.Resize(32),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
traindata_path = data.CRACKdataset_path([train_img_path,
train_label_path],
cfg.crop_size,
transform_img)
test_loader = DataLoader(traindata_path,
batch_size=cfg.BATCH_SIZE,
shuffle=True,
num_workers=0)
from torch.utils.tensorboard import SummaryWriter
logdir = 'checkphoto'
kk_tools.del_file(logdir)
writer = SummaryWriter(log_dir=logdir)
net = FCN_8s(2)
net.eval()
net.load_state_dict(torch.load('best.pth'))
fmap_dict = dict()
for name, sub_module in net.named_modules():
print(name)
if isinstance(sub_module, nn.Conv2d) or isinstance(sub_module, nn.ConvTranspose2d):
key_name = str(sub_module.weight.shape)
fmap_dict.setdefault(key_name, list())
def hook_func(m, inputd, outputd):
key_name = str(m.weight.shape)
fmap_dict[key_name].append(outputd)
if '.' in name:
n1, n2 = name.split(".")
net._modules[n1]._modules[n2].register_forward_hook(hook_func)
else:
net._modules[name].register_forward_hook(hook_func)
i, sample = next(enumerate(test_loader))
out = net(sample['img'])
# add image
for layer_name, fmap_list in fmap_dict.items():
fmap = fmap_list[0]
nrow = int(np.sqrt(fmap.shape[0]))
with torch.no_grad():
fmap_grid = torchvision.utils.make_grid(fmap,
normalize=True,
scale_each=True,
nrow=nrow)
writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)
# 需要特征图输出通道数为3才可以可视化
writer.close()
print('完成')
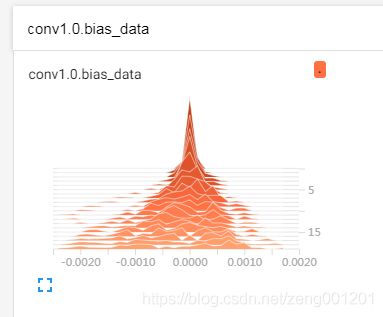
3.5 训练过程输出值的可视化
为避免出现梯度消失或者梯度爆炸,需要保持方差一致性原则,尽量使输出层的方差为1,这里可用直方图直观的查看输出值的分布情况。
在训练train.py文件中的,每次输出完loss的可视化文件后:
if ut_w:
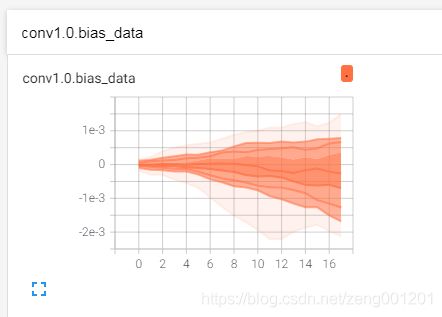
for name, param in net.named_parameters():
writer.add_histogram(name + '_grad', param.grad, epoch)
writer.add_histogram(name + '_data', param, epoch)
得到多分位数折线图:观察方差情况
得到直方图:
总结
感觉尝试了一些tensorboard的可视化后,最有用的是loss和weight的可视化,其他用处不大。
参考资料
1、https://www.pytorchtutorial.com/pytorch-builtin-tensorboard/
2、https://ai.deepshare.net/page/464096
3、https://blog.csdn.net/qq_36533552/article/details/102486823