特征工程:时序特征分析的奇技淫巧

最近在做时间序列的项目,所以总结一下构造的特征的方法和一些经验。
先放上大纲:
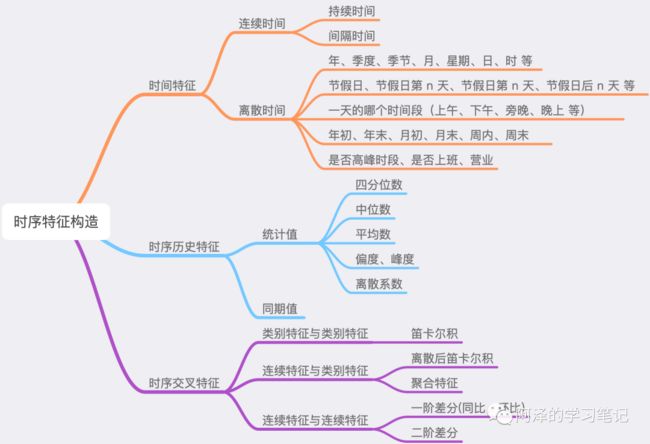
1.时间特征
1.1 连续时间
持续时间:
-
浏览时长;
间隔时间:
-
购买/点击距今时长;
距离假期的前后时长(节假日前和节假日后可能会出现明显的数据波动);
1.2 离散时间
年、季度、季节、月、星期、日、时 等;
-
基本特征,如果用 Xgboost 模型可以进行 one-hot 编码;
如果类别比较多,可以尝试平均数编码(Mean Encoding)。
或者取 cos/sin 将数值的首位衔接起来,比如说 23 点与 0 点很近,星期一和星期天很近。
节假日、节假日第 n 天、节假日前 n 天、节假日后 n 天;
-
数据可能会随着节假日的持续而发生变化,比如说递减;
节假日前/后可能会出现数据波动;
不放假的人造节日如 5.20、6.18、11.11 等也需要考虑一下;
一天的某个时间段;
-
上午、中午、下午、傍晚、晚上、深夜、凌晨等;
年初、年末、月初、月末、周内、周末;
-
基本特征;
高峰时段、是否上班、是否营业、是否双休日;
-
主要根据业务场景进行挖掘。
# 年、季度、季节、月、星期、日、时
data_df['date'] = pd.to_datetime(data_df['date'], format="%m/%d/%y")
data_df['quarter']=data_df['date'].dt.quarter
data_df['month'] = data_df['date'].dt.month
data_df['day'] = data_df['date'].dt.day
data_df['dayofweek'] = data_df['date'].dt.dayofweek
data_df['weekofyear'] = data_df['date'].dt.week # 一年中的第几周
# Series.dt 下有很多属性,可以去看一下是否有需要的。
data_df['is_year_start'] = data_df['date'].dt.is_year_start
data_df['is_year_end'] = data_df['date'].dt.is_year_end
data_df['is_quarter_start'] = data_df['date'].dt.is_quarter_start
data_df['is_quarter_end'] = data_df['date'].dt.is_quarter_end
data_df['is_month_start'] = data_df['date'].dt.is_month_start
data_df['is_month_end'] = data_df['date'].dt.is_month_end
# 是否时一天的高峰时段 8~10
data_df['day_high'] = data_df['hour'].apply(lambda x: 0 if 0 < x < 8 else 1)
# 构造时间特征
def get_time_fe(data, col, n, one_hot=False, drop=True):
'''
data: DataFrame
col: column name
n: 时间周期
'''
data[col + '_sin'] = round(np.sin(2*np.pi / n * data[col]), 6)
data[col + '_cos'] = round(np.cos(2*np.pi / n * data[col]), 6)
if one_hot:
ohe = OneHotEncoder()
X = OneHotEncoder().fit_transform(data[col].values.reshape(-1, 1)).toarray()
df = pd.DataFrame(X, columns=[col + '_' + str(int(i)) for i in range(X.shape[1])])
data = pd.concat([data, df], axis=1)
if drop:
data = data.drop(col, axis=1)
return data
data_df = get_time_fe(data_df, 'hour', n=24, one_hot=False, drop=False)
data_df = get_time_fe(data_df, 'day', n=31, one_hot=False, drop=True)
data_df = get_time_fe(data_df, 'dayofweek', n=7, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'season', n=4, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'month', n=12, one_hot=True, drop=True)
data_df = get_time_fe(data_df, 'weekofyear', n=53, one_hot=False, drop=True)
2.聚合特征
2.1 统计值
基于历史数据构造长中短期的统计值,包括前 n 天/周期内的:
四分位数;
中位数、平均数、偏差;
偏度、峰度;
-
挖掘数据的偏离程度和集中程度;
离散系数;
-
挖掘离散程度
这里可以用自相关系数(autocorrelation)挖掘出周期性。
除了对数据进行统计外,也可以对节假日等进行统计,以刻画历史数据中所含节假日的情况。(还可以统计未来的节假日的情况。)
# 画出自相关性系数图
from pandas.plotting import autocorrelation_plot
autocorrelation_plot(data['value'])
# 构造过去 n 天的统计数据
def get_statis_n_days_num(data, col, n):
temp = pd.DataFrame()
for i in range(n):
temp = pd.concat([temp, data[col].shift((i+1)*24)], axis=1)
data['avg_'+ str(n) +'_days_' + col] = temp.mean(axis=1)
data['median_'+ str(n) +'_days_' + col] = temp.median(axis=1)
data['max_'+ str(n) +'_days_' + col] = temp.max(axis=1)
data['min_'+ str(n) +'_days_' + col] = temp.min(axis=1)
data['std_'+ str(n) +'_days_' + col] = temp.std(axis=1)
data['mad_'+ str(n) +'_days_' + col] = temp.mad(axis=1)
data['skew_'+ str(n) +'_days_' + col] = temp.skew(axis=1)
data['kurt_'+ str(n) +'_days_' + col] = temp.kurt(axis=1)
data['q1_'+ str(n) +'_days_' + col] = temp.quantile(q=0.25, axis=1)
data['q3_'+ str(n) +'_days_' + col] = temp.quantile(q=0.75, axis=1)
data['var_'+ str(n) +'_days_' + col] = data['std_'+ str(n) +'_days_' + col]/data['avg_'+ str(n) +'_days_' + col] # 离散系数
return data
data_df = get_statis_n_days_num(data_df, 'num_events', n=7)
data_df = get_statis_n_days_num(data_df, 'num_events', n=14)
data_df = get_statis_n_days_num(data_df, 'num_events', n=21)
data_df = get_statis_n_days_num(data_df, 'num_events', n=28)
此外,还可以对这些统计值进行分桶,增强模型的鲁棒性。
2.2 同期值
前 n 个周期/天/月/年的同期值;
# n 个星期前同期特征
data_df['ago_7_day_num_events'] = data_df['num_events'].shift(7*24)
data_df['ago_14_day_num_events'] = data_df['num_events'].shift(14*24)
data_df['ago_21_day_num_events'] = data_df['num_events'].shift(21*24)
data_df['ago_28_day_num_events'] = data_df['num_events'].shift(28*24)
# 昨天的同期特征
data_df['ago_7_day_num_events'] = data_df['num_events'].shift(1*24)
3.交叉特征
类别特征间组合构成新特征:
-
笛卡尔积,比如星期和小时:Mon_10(星期一的十点);
类别特征和连续特征:
-
连续特征分桶后进行笛卡尔积;
基于类别特征进行 groupby 操作,类似聚合特征的构造;
连续特征和连续特征:
-
同比和环比(一阶差分):反应同期或上一个统计时段的变换大小;
二阶差分:反应变化趋势;
比值;
特征交叉一般从重要特征线下手,慢工出细活。
# 一阶差分
data_df['ago_28_21_day_num_trend'] = data_df['ago_28_day_num_events'] - data_df['ago_21_day_num_events']
data_df['ago_21_14_day_num_trend'] = data_df['ago_21_day_num_events'] - data_df['ago_14_day_num_events']
data_df['ago_14_7_day_num_trend'] = data_df['ago_14_day_num_events'] - data_df['ago_7_day_num_events']
data_df['ago_7_1_day_num_trend'] = data_df['ago_7_day_num_events'] - data_df['ago_1_day_num_events']
4.写在最后
构造时序特征时一定要算好时间窗口,特别是在工作的时候,需要自己去设计训练集和测试集,千万不要出现数据泄露的情况(比如说预测明天的数据时,是拿不到今天的特征的);
针对上面的情况,可以尝试将今天的数据进行补齐;
有些特征加上去效果会变差,大概率是因为过拟合了;
有些特征加上去效果出奇好,第一时间要想到是不是数据泄露了;
拟合不好的时间(比如说双休日)可以分开建模;
ont-hot 对 xgboost 效果的提升很显著;
离散化对 xgboost 效果的提升也很显著;
对标签做个平滑效果可能会显著提升;
多做数据分析,多清洗数据;