HALCON 20.11:深度学习笔记(6)---有监督训练
HALCON 20.11:深度学习笔记(6)---有监督训练
HALCON 20.11.0.0中,实现了深度学习方法。不同的DL方法有不同的结果。相应地,它们也使用不同的测量方法来确定网络的“好坏”。在训练一个网络时,不同的模型会有不同的行为和缺陷,我们将在这里进行描述。
训练中的验证
当涉及到网络性能验证时,重要的是要注意,这不是一个纯粹的优化问题(参见上面的“网络和训练过程”和“设置训练参数”部分)。
为了观察训练过程,通常可视化验证措施是有帮助的,如对于分类网络的训练,批样本的误差。
由于样本不同,分配任务的难度也可能不同。
因此,与另一批样本相比,网络对某批样本的性能可能更好,也可能更差。因此,验证度量在迭代过程中不会平稳地改变是很正常的。但总的来说,它应该有所改善。
调整超参数'learning_rate'和'momentum'可以帮助再次改进验证度量。
下面的图显示了可能的场景。
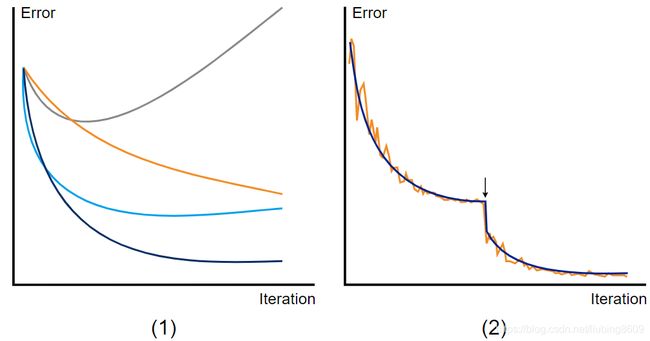
Sketch of an validation measure during training, here using the error from classification as example
(1) General tendencies for possible outcomes with different 'learning_rate' values. dark blue: good learning rate; gray: very high learning rate; light blue: high learning rate, orange: low learning rate
(2) Ideal case with a learning rate policy to reduce the 'learning_rate' value after a given number of iterations. In orange: training error, dark blue: validation error. The arrow marks the iteration, at which the learning rate is decreased.
欠拟合和过拟合的风险
如果模型不能捕获任务的复杂性,就会发生欠拟合。这直接反映在训练集的验证测度上,该测度保持较高。
当网络开始“记忆”训练数据,而不是学习如何归纳时,就会发生过拟合。
这可以通过训练集上的验证度量来证明,当验证集上的验证度量变差,而训练集上的验证度量保持良好甚至有所改善。
在这种情况下,正规化可能会有所帮助。请参阅“设置训练参数:超参数”一节中对超参数“weight_prior”的解释。
请注意,当模型容量相对于数据过高时,也会出现类似的现象。

Sketch of a possible overfitting scenario, visible on the generalization gap (indicated with the arrow). The error from classification serves as an example for a validation measure.
混淆矩阵(Confusion Matrix)
一个网络为一个实例推断出一个顶级预测,即推断出最高亲和力的类。当我们知道了它的ground truth class,我们可以比较两个类的关系:预测值和正确值。因此,实例在不同类型的方法之间是不同的,例如,在分类实例是图像,在语义分割实例是单个像素。
当两个以上的类被区分时,也可以将比较化为二值问题。这意味着,对于一个给定的类,你只需要比较它是相同的类(积极的)还是任何其他类(消极的)。对于这种二元分类问题,比较简化为以下四种可能的实体(其中并不是所有的都适用于每一种方法):
真阳性(TP:预测阳性,标记阳性),
真阴性(TN:预测阴性,标记阴性),
假阳性(FP:预测阳性,标记阴性),
假阴性(FN:预测阴性,标记阳性)。
混淆矩阵就是具有这种比较的表格。
这个表可以很容易地看到网络对每个类的执行情况。
对于每个类,它列出了预测到哪个类的实例的数量。
例如,对于区分“苹果”、“桃子”和“橘子”这三个类别的分类器,混淆矩阵显示了有多少带有ground truth class从属关系的“苹果”被分类为“苹果”以及有多少被分类为“桃子”或“橘子”。
当然,这也列出了其他类。这个例子如下图所示。在HALCON中,我们在一列中为每个类表示带有这个ground truth标签的实例,并在一行中预测属于这个类的实例。
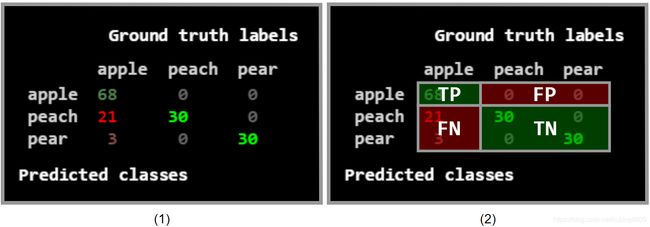
An example for a confusion matrices from classification. We see that 68 images of an 'apple' have been classified as such (TP), 60 images showing not an 'apple' have been correctly classified as a 'peach' (30) or 'pear' (30) (TN), 0 images show a 'peach' or a 'pear' but have been classified as an 'apple' (FP) and 24 images of an 'apple' have wrongly been classified as 'peach' (21) or 'pear' (3) (FN). (1) A confusion matrix for all three distinguished classes. It appears as if the network 'confuses' apples and peaches more than all other combinations. (2) The confusion matrix of the binary problem to better visualize the 'apple' class.