大数据Flink电商实时数仓实战项目流程全解(四)动态分流详解
DWD层业务数据分流
回顾一下之前业务数据的处理;
首先把脚本生成的业务数据发送到MySql数据库中,在表gmall0709中可以看到数据:

这里就是生成的对应数据表,然后通过Maxwell把数据输入到Kafka中,保存在ods_base_db_m主题中;此时我们需要把这个kafka主题中的数据进行过滤和分流处理,过滤处理很容易,这里我们过滤掉data为空,或者是长度<3的数据内容,当然这个数据过滤部分可以由自己来定;
//过滤部分的代码内容;
SingleOutputStreamOperator<JSONObject> filteredDS = jsonObjDS.filter(
jsonObj -> {
boolean flag = jsonObj.getString("table") != null
&& jsonObj.getJSONObject("data") != null
&& jsonObj.getJSONObject("data").size() >= 3;
return flag;
});
接下来的内容就是本文的重点部分,也是本实时数仓项目中的一个重要内容:动态分流;
动态分流意义及其实现
动态分流是什么意思呢?
这里我以一个业务场景为例子来讲解,假如现在公司有一个实时数仓已经搭建完毕了,各项业务场景代码已经写好,就像之前的日志数据分流一样,业务数据也按照不同的方法进行分流。如果公司这时候有了一个新的需求,比如此时业务部分创建了一张新的明细表(对应一个新业务),然后需要数仓能实时地把所需要的数据导入到这张表中来;按照传统的思路,此时我们应该将分流处的代码进行改写,然后重启集群,但这样就会造成一个很大的问题,公司的业务变更一次,集群就要重启一次,耗时耗力还容易出问题;
那么此时就产生一种思考,能不能让数据自己找到对应的表,然后输出呢?
这就是动态分流的意义了;
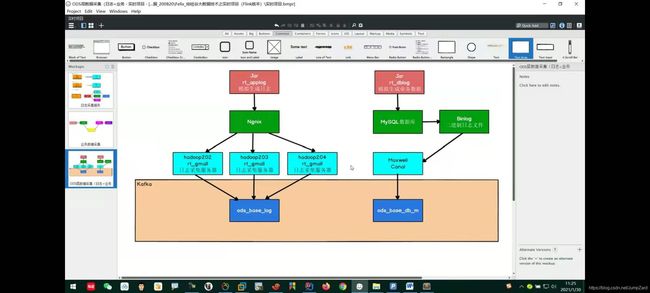
我们通过一张图来帮助理解这个概念:

当ods层中的业务层数据被Flink读取到之后,我们为其动态地生成一张表;然后把这张表动态地保存在MySql中的一个特定数据库内,每过一段时间,Flink就会去动态的获取这个数据库中的配置表信息,然后告诉数据应该进行什么样的操作;
那么这个数据库的配置表应该保存什么样的数据才能让业务数据完成动态地分流呢?很容易可以想到,首先需要一个对应业务的表名,其次需要一个操作名称,目的是为了匹配我们对这张表做了什么样的操作,然后还需要指明这些数据应该被写到什么位置,这里我们把维度和事实数据分别写入到Hbase和Kafka中,所以我们还需要主题名或者是表名,但光这些还不够对应存储,因为我们的数据不止一个特征,所以我们还需要指定对应的表的字段是哪些;综上,我们的配置表至少需要5个列,为了和项目统一,我们在这里还设定了主键和extend两个列;
虽然在这里后续的维度宽表和主题宽表都还没有做,但是可以提前看一下配置表的内容:
//配置信息表:
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
//来源表就是指是事实表还是维度表;
//对于kafka,输出表就是主题名;对于HBase,输出表就是对应的表;
//输出字段就是指给定需要输出的字段
//主键字段就是指输出的主键字段(比如HBase表的rowKey)
//建表扩展就是指ENGINE=InnoDB DEFAULT CHARSET=utf8语句;
最后的数据样式大概长这个样子(后面还有主键列和Extend列没有展示出来):

Flink会阶段性地去读取这个表中的内容,然后
阶段小结
讲完了动态分流功能的概念和意义之后,接下来就是如何实现的问题了,这也是难点所在;
//主流kafkaDS
SingleOutputStreamOperator<JSONObject> kafkaDS = filteredDS.process(
new TableProcessFunction1(hbaseTag)
);
//5.3获取侧输出流 写到Hbase的数据
DataStream<JSONObject> hbaseDS = kafkaDS.getSideOutput(hbaseTag);
//得到了Hbase数据之后,再把Hbase数据和kafka数据保存起来;
hbaseDS.addSink(new DimSink());
kafkaDS.addSink(kafkaSink);
这段代码还是很容易懂的,那么这个TableProcessFunction如何实现呢?
DimSink和kafkaSink对象又如何实现呢?
TableProcessFunction的实现
这里的TableProcessFunction其实就是配置表的处理函数,即我们应该如何根据配置表的信息把数据进行动态分流;对于kafka的数据,比较容易处理,直接把数据发往对应主题即可,但是对于要保存在Hbase中的维度数据就比较麻烦了,获取和保存都是一个比较麻烦的事情,所以这里应用了Phoenix框架来帮助处理Hbase数据,具体安装和使用见本文末尾;
Hbase数据处理思路
首先,当我们从MySql中查询配置表的具体信息,获取每一行的数据以及字段名,这样我们就相当于把所有在工作的表都得到了,然后把这些表存储起来;同时开启一个定时任务,每过5秒定期访问一次配置表,如果发生了更新,则在对应的Hbase中创建表,字段就用从配置表中读取到的字段,同时把这个表也保存起来,方便下次查询;
说起来很容易,但实现起来的过程并不简单:首先要从MySql中定期获取配置表的信息,然后封装成一个对象,所以这里需要一个MySql的工具类和一个对应的Bean对象;
其次就是如何去通过字段,去合成对应的建表语句,这里也是一个很复杂的代码编写过程;
其次,在processElement方法中,对数据做对应的过滤,只保留所需的字段,然后根据配置表中sinkType的值,对应输出数据到Hbase或是kafka;
细节内容和注释见代码,这里就不展开讲解代码编写了,注释应该写得很详细了;
总结
到这里为止,维度数据和事实数据的动态分流就实现了,接下来就是把他们保存到Hbase和Kafka中,那么接下来还会面临一个大难点,即Hbase表和kafka主题都是不确定的,如何准确地动态写入这两个内容呢?这就是下一篇内容讲解的重点。
Phoenix的安装和使用
安装Phoenix:
1.解压
2.复制server包到各个节点的hbase/lib
cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
scp phoenix-5.0.0-HBase-2.0-server.jar hadoop103:/opt/module/hbase/lib/
scp phoenix-5.0.0-HBase-2.0-server.jar hadoop104:/opt/module/hbase/lib/
3.配置环境变量
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
//连接phoenix:
/opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
开启hbase和zookeeper后也可以直接 bin/sqlline.py
//phoenix基本使用:
创建表 create table person (id integer not null primary key,info1.name varchar,info2.name varchar,age integer);//这里的info1和info2就是列族名;表名默认大写,双引号括起来后是小写;
create table person (id integer not null primary key,name varchar,age integer);
插入数据 upsert into person values (1,'zhangsan' ,18);
查询 select * from person;
删除数据 delete from person where name='zhangsan';
查看表结构 !describe 表名
查看表 !tables show tables;
删除表 drop table 表名
退出phoenix !exit
//为了支持动态分流时,设定数据进入哪个命名空间的功能,这里需要加入两个额外配置到hbase的配置文件hbase-site.xml中;
//修改配置文件时,hbase服务要先停下来;
//同样,在phoenix的bin目录下的hbase-site.xml文件中也要加上;(102上配置phoenix即可)
//开启了这两个之后,在客户端上就不能再开启了;
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
//动态分流时,在hbase中创建不同的命名空间:
create schema GMALL20210709_REALTIME; //与代码中的HABSE_SCHEMA = "GMALL0709_REALTIME"保持一致;