[论文阅读:姿态识别&Transformer] TransPose: Keypoint Localization via Transformer 2021 ICCV
思路:将transformer引入姿态估计
方法:使用的CNN backbone + Transformer Encoder的结构。如果从原图开始直接使用transformer则计算量过大。最后使用transformer的输出reshape回2维图像,取其激活最大值坐标位置作为关节点坐标。
1.Top-down方式。使用卷积作为backbone进行特征图提取
2.Transformer编码层通过query-key-value注意力迭代地从序列中捕获依赖项,再用一个简单的head来预测关键点热图
1. 摘要
提出了一种名为TransPose的模型,将Transformer引入人体姿态估计。Transformer中内置的注意层使我们的模型能够有效地捕获长期关系,并且还可以揭示预测的关键点依赖于什么。为了预测关键点热图,最后的注意层充当了一个聚合器,它从图像线索中收集贡献,并形成关键点的最大位置。这种通过Transformer的基于热图的本地化方法符合激活最大化的原则。并且揭示的依赖关系是特定于图像的和细粒度的,这也可以提供模型如何处理特殊情况的证据,例如遮挡。
2.主要工作
卷积在提取底层特征方面具有优势,但在高层深度叠加卷积以扩大感受野并不能有效地捕获全局依赖关系。如下图所示,注意层使模型能够捕获任何成对位置之间的交互,它的注意图充当了存储这些依赖关系的即时记忆。
![[论文阅读:姿态识别&Transformer] TransPose: Keypoint Localization via Transformer 2021 ICCV_第1张图片](http://img.e-com-net.com/image/info8/09637f88c51140b692542702bde853a3.jpg)
CNN vs. Attention 左图:感受野在更深的卷积层中扩大。右:一个自我注意层可以捕捉任何位置的一对点之间的成对关系
3. Contributions
(1)引入了用于人体姿态估计的Transformer来预测基于热图的关键点位置,可以有效地捕捉人体各部位之间的空间关系。
(2)证明了我们基于Transformer的关键点定位方法符合激活最大化的可解释性[19,49]。定性分析揭示了直觉之外的依赖关系,这些依赖关系是特定于图像的和细粒度的。
4. 框架总览
![[论文阅读:姿态识别&Transformer] TransPose: Keypoint Localization via Transformer 2021 ICCV_第2张图片](http://img.e-com-net.com/image/info8/0c324230b58247519c50b3f22abc81a0.jpg)
首先,利用CNN骨干网络提取特征图并将其展开为序列。接下来,Transformer编码层通过query-key-value注意力迭代地从序列中捕获依赖项。然后,用一个简单的head来预测关键点热图。Transformer中的注意图可以揭示哪些依赖项(区域或关节点)对预测关键点热图中的激活最大位置有显著贡献
4.1. Architecture
TransPose模型由三个分量组成: 一是提取低层次图像特征的CNN主干; 一个Transformer编码器,捕捉跨位置的特征向量之间的远距离空间交互; 一个预测关键点热图的head
Backbone
为了更好的比较,我们选择了两种典型的CNN架构:ResNet和HRNet。
Transformer
我们尽可能地遵循标准的Transformer架构。 并且只使用了编码器,因为我们认为纯热图预测任务只是一个编码任务,它将原始图像信息压缩成关键点的紧凑位置表示。 给定一个输入图像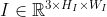 ,我们假设CNN主干输出一个二维空间结构图像特征
,我们假设CNN主干输出一个二维空间结构图像特征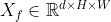 ,其特征维度已经通过1×1卷积转换为d。 然后,将图像特征图展平为序列
,其特征维度已经通过1×1卷积转换为d。 然后,将图像特征图展平为序列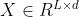 ,即 L个d 维特征向量,其中 L = H ×W。 它经过 N 个注意力层和前馈网络 (FFN)。
,即 L个d 维特征向量,其中 L = H ×W。 它经过 N 个注意力层和前馈网络 (FFN)。
Head
一个头附加到Transformer Encoder 的输出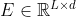 ,以预测 K 类型的关键点 heatmaps
,以预测 K 类型的关键点 heatmaps 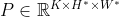 ,其中在默认情况下
,其中在默认情况下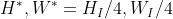 。 我们首先将 E 重新整形为
。 我们首先将 E 重新整形为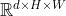 形状,然后我们主要使用1×1卷积将E的通道维度从d减少到K。如果H,W不等于
形状,然后我们主要使用1×1卷积将E的通道维度从d减少到K。如果H,W不等于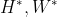 ,则使用额外的双线性插值或4×4转置卷积进行上采样。在 1×1 卷积之前。 请注意,1×1 卷积完全等效于位置线性变换层。
,则使用额外的双线性插值或4×4转置卷积进行上采样。在 1×1 卷积之前。 请注意,1×1 卷积完全等效于位置线性变换层。
4.2 Attentions are the Dependencies of Localized Keypoints
Self-Attention mechanism
multi-head self-attention是transformer的核心点。它首先将输入的序列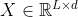 通过三个矩阵
通过三个矩阵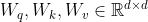 映射到
映射到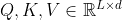 ,然后通过以下公式计算注意力得分矩阵
,然后通过以下公式计算注意力得分矩阵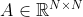
![]()
每个token的 xi ∈Rd(即位置 i 处的特征向量)的每个查询 qi ∈Rd 计算与所有key的相似度以获得权重向量 wi = Ai,: ∈ R1×L,这决定了需要多少依赖来自前一个序列中的每个token。然后通过将值矩阵 V 中的所有元素与 wi 中的相应权重进行线性求和并添加到 xi 来实现增量。 通过这样做,注意力图可以被视为由特定图像内容确定的动态权重,在前向传播中重新加权信息流。
Self-attention捕获并揭示从每个图像位置预测的贡献。来自不同图像位置的这种贡献可以通过梯度来反映。 因此,我们具体分析图像/序列位置 j 处的 xj如何影响预测关键点热图中位置 i 处的激活 hi,通过计算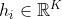 (K种关键点)对 xj 在位置 j 处的导数(最后一个注意力层的输入序列xj)。然后我们进一步假设函数
(K种关键点)对 xj 在位置 j 处的导数(最后一个注意力层的输入序列xj)。然后我们进一步假设函数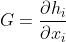 ,在给定注意力分数
,在给定注意力分数 下可以获得:
下可以获得:
![]()
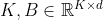 是静态权重(推断时固定)并且在所有图像位置之间共享。公式2的推导显示在补充中。 我们可以看到函数 G 与 Ai,j 近似线性,即对预测hi的贡献程度直接取决于其在图像位置的注意力分数。
是静态权重(推断时固定)并且在所有图像位置之间共享。公式2的推导显示在补充中。 我们可以看到函数 G 与 Ai,j 近似线性,即对预测hi的贡献程度直接取决于其在图像位置的注意力分数。
特别是,最后一个注意力层充当聚合器,它根据注意力收集所有图像位置的贡献,并在预测的关键点热图中形成最大激活。 尽管 FFN 和 head 中的层不能忽略,但它们是位置相关(position-wise)的,这意味着它们通过相同的变换近似线性地变换来自所有位置的贡献,而不改变它们的相对比例。
4.3The activation maximum positions are the keypoints’locations
激活最大化(AM)的可解释性在于:能够最大化给定神经元激活的输入区域可以解释这个被激活的神经元在寻找什么。
transPose 的学习目标是期望热图的位置 i* 处的神经元激活 hi* 被最大程度地激活,其中 i* 表示关键点的 groundtruth位置:
![]()
假设模型已经使用参数 θ∗ 进行了优化,并且它预测特定关键点的位置为 i(热图中的最大位置),那么为什么模型预测这样的预测可以通过以下事实来解释:那些位置 J,其元素j对i具有的较高注意力分数 (≥δ) 是对预测有显着贡献的依赖项。 可以通过以下方式找到依赖项:
![]()
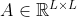 是最后一个注意力层的注意力图,也是一个关于 θ∗和I的函数。给定一张输入图像I和查询位置i,Ai:可以揭示预测位置i高度依赖于什么,将其定义为依赖区域
是最后一个注意力层的注意力图,也是一个关于 θ∗和I的函数。给定一张输入图像I和查询位置i,Ai:可以揭示预测位置i高度依赖于什么,将其定义为依赖区域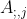 (dependency area),依赖区域可以揭示j主要影响的区域,定义为受影响区域(affected area)。
(dependency area),依赖区域可以揭示j主要影响的区域,定义为受影响区域(affected area)。
5. Experiments
Ablations
The importance of position embedding
在没有位置嵌入的情况下,2D 空间结构信息会在 Transformer 中丢失。 为了探索其重要性,我们对具有三种位置嵌入策略的 TransPose-R-A3 模型进行了实验:2D 正弦位置嵌入、可学习位置嵌入和无位置嵌入。 正如预期的那样,具有位置嵌入的模型表现更好,特别是对于 2D 正弦位置嵌入,如表 4 所示。但有趣的是,没有任何位置嵌入的 TransPose 仅损失 1.3 AP,这表明 2D 结构变得不那么重要了。

Scaling the Size of Transformer Encoder
我们研究了性能如何随着 Transformer Encoder 的大小而变化,如表 7 所示。对于 TransPose-R 模型,随着层数增加到 6,性能改进逐渐趋于饱和或退化。 但我们还没有在 TransPose-H 模型上观察到这种现象。 缩放 Transformer 明显提高了 TransPose-H 的性能。
![[论文阅读:姿态识别&Transformer] TransPose: Keypoint Localization via Transformer 2021 ICCV_第3张图片](http://img.e-com-net.com/image/info8/d4187809dbc744fba92f0b7e0cfcb4b3.jpg)
Position embedding helps to generalize better on unseen input resolutions
自上而下的范例将所有裁剪的图像缩放到固定大小。 但在某些情况下,即使输入大小固定或自下而上范式,输入中的主体大小也会有所不同; 对不同尺度的鲁棒性变得很重要。 所以我们设计了一个极端的实验来测试泛化性:我们在看不见的 128×96,384×288、512×388 输入分辨率上测试 SimpleBaseline-ResN50-Dark 和 TransPose-R-A3 模型,所有这些都只用 256×192 训练过 尺寸。 有趣的是,图 5 中的结果表明 SimpleBaseline 和 TransPose-R w/o position embedding 在不可见的分辨率上具有明显的性能崩溃,尤其是在 128×96 上; 但是具有可学习或 2D Sine 位置嵌入的 TransPose-R 具有明显更好的泛化能力,尤其是对于 2D Sine 位置嵌入。
![[论文阅读:姿态识别&Transformer] TransPose: Keypoint Localization via Transformer 2021 ICCV_第4张图片](http://img.e-com-net.com/image/info8/c9090e7514414ec5bffd7e364b8ef044.jpg)