【PyTorch深度学习实践】深度学习之多维特征输入和加载数据集
文章目录
- 前言
- 一、多维特征输入的处理
- 二、加载数据集
- 总结
前言
本章我们将讲述一下多维特征输入和加载数据集的相关问题
提示:以下是本篇文章正文内容,下面案例可供参考
一、多维特征输入的处理
在之前的文章中,我们输入的数据集和输出结果都是一维的。但当我们的数据集是多维的,如下图,输入是八维的,要使输出是一维的,应该怎么处理呢

很简单,遇到这个问题我们可以用矩阵相乘进行维度的变化,通过相应维度的输入值x的矩阵,和相应维度的权重w的矩阵相乘,再加上相应维度的偏置量b的矩阵,就能得到最终需要相应维度的输出y的矩阵,如下图所示:

要由八维空间转变为一维空间,本文章采用三层神经网络一步步转变,先由八维到六维的非线性空间变换,再有六维到四维的非线性空间变换,最后由四维到一维的非线性空间变换,如下图:

代码与之前文章讲述的过程一致,有四步,准备数据集,设计模型,构造损失函数和优化器,训练。代码如下:
import numpy as np
import torch
import matplotlib.pyplot as plt
# 准备数据集
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取数据中的所有行项,第二个‘:’是指从数据项的第一列开始,最后一列不取
y_data = torch.from_numpy(xy[:, [-1]]) # [-1]表示只需最后一列
#设计模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 三层神经网络
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数和优化器
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
#训练
for epoch in range(10000): #训练1000次和10000次的效果不一样
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
除了sigmoid函数可以做激活函数,还有很多函数也可以,如下图:

二、加载数据集
在本节中,我们将在加载数据集上做些处理,以提高运行速率,类似于batch和mini batch,详情可看这篇博客:http://t.csdn.cn/RydjA
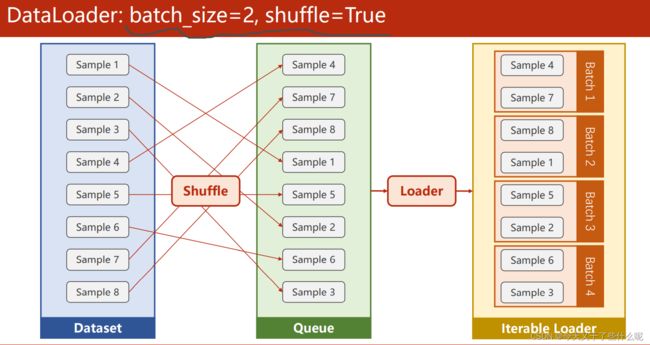
图中batch_size=2指的是将数据两两进行加载处理,shuffle=True是打乱数据的顺序,使数据集具有随机性
在多为特征输入的代码中,只在数据加载部分稍作修改,如下图:

代码如下:
import numpy as np
import torch
from torch.utils.data import Dataset,DataLoader
import matplotlib.pyplot as plt
#准备数据集
class DiabetesDataset(Dataset): #继承自Dataset
def __init__(self,filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:, :-1])
self.y_data=torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index): #是能够支持索引操作
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset=DiabetesDataset('diabetes.csv.gz')
train_loader=DataLoader(dataset=dataset,
batch_size=32, #分成32份
shuffle=True, #打乱数据集
num_workers=2) #并行读取数据,提高读取效率
#设计模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 三层神经网络
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
#训练
if __name__=='__main__': #不加这一句会报错
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 1.inputs是输入x,labels是y
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
总结
在多维特征输入一节,我们讲述了如何将多维的输入转变为一维的输出,并进行了代码实现,在加载数据集一节中,我们讲述了如何将通过设计类来加载数据