自监督的三维重建论文总结(MVSNet系列)
目前我看到的无监督的方法就是这么几篇,会持续更新相关论文。
其实都是基于第一篇提出的基于光度一致性做文章,在那个基础上使用各种层面上的光度一致性约束。
- Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
- MVS2: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
- M3VSNet: Unsupervised Multi-metric
Multi-view Stereo Network - Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation
MVSNet系列方法比较
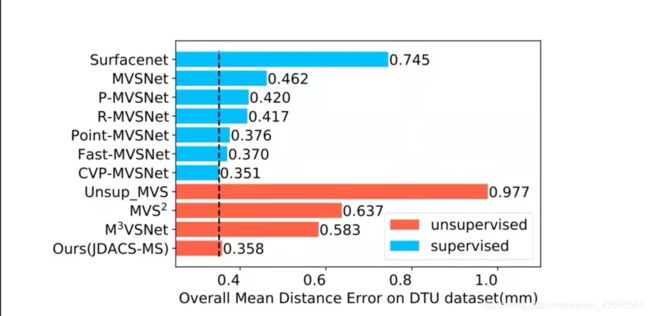
图来自论文(盗图一下)链接:https://www.aaai.org/AAAI21Papers/AAAI-2549.XuH.pdf
附:深度采样范围中各个参数的解释计算

Learning Unsupervised Multi-View Stereopsis via Robust Photometric Consistency
Khot, Tejas, et al. “Learning unsupervised multi-view stereopsis via robust photometric consistency.” arXiv preprint arXiv:1905.02706 (2019).
1 论文贡献
虽然目前的深度MVS方法取得了非常好的结果,但它们都依赖于真实的3D数据,也就是都需要监督的。而3D GT通常需要非常大的工作量,因此本文提出了一种无监督的方法来训练网络。他利用多个视图之间的光度一致性并加入了像素梯度差异作为监督信号,来预测深度图。
2 Method
首先是深度图预测
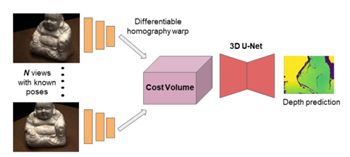
取一个场景的N幅图像作为输入。图像特征是使用CNN生成的。利用可微单应性变换,通过在深度值范围内对图像特征进行映射来构造时差体积。然后使用3D U-Net的CNN来细化成本量。最后的输出是一个缩小分辨率的深度图。
然后保持光度一致性
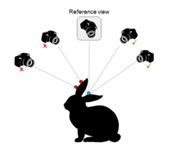
使用其他视角的图像去监督预测的深度图,要做到这一步就需要结合预测的深度图去获得视差值和参考视角图像从而通过单应性变换去将参考视角图像像素映射到其他视角。
过程如下:
映射(这里借鉴了STN)
![]()
双线性插值
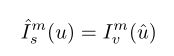
这里还生成了一个二进制有效性掩膜V,当一些像素投影到新视图中的图像边界外时,表示合成视图中的不是“有效”像素。Loss如下:
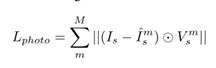
但是这个公式存在几个问题,例如无法解决遮挡和光照变化。在一些视角下,参考视角像素点在其他视角是看不到的。因此使用一个更好的一致性约束:
首先考虑进像素梯度差异
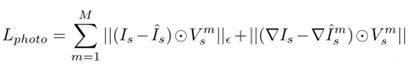
然后解决不同图像中的3D结构遮挡所带来的问题
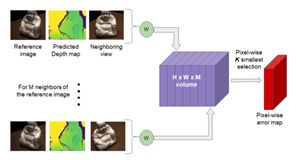
只使用top-K(从M个视图中)视图。如上图所示,这些M个损失映射连接成H×W×M的体积,其中H和W是图像的尺寸。这个体积被用来执行像素级的选择来挑选K个“最佳”(最低损耗)值,沿着体积的第三维(即在M个损耗映射上),使用它的平均值来计算稳健的光度loss。
MVS2: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
Dai, Yuchao, et al. “Mvs2: Deep unsupervised multi-view stereo with multi-view symmetry.” 2019 International Conference on 3D Vision (3DV). IEEE, 2019.
1 论文作用
这个方法同样是无监督的三维重建。网络在同时预测所有视图的深度图时是对称的,即使用了多视图深度图的交叉视图一致性。这个多视图一致性发挥了两个作用,一个是在监督方面实现了自监督,另一方面还使网络还学习了多视图遮挡的mask,这进一步提高了网络处理真实世界遮挡的鲁棒性。
2 Method
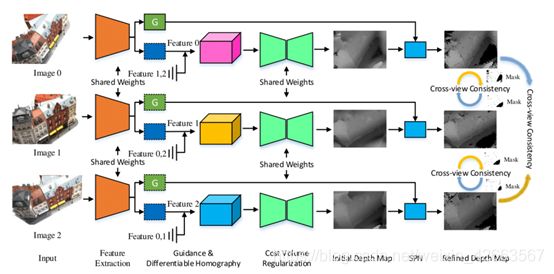
网络由五个模块组成,分别是特征提取、导引与可微分单应性、代价量正则化、spn和交叉视图一致性损失评估。在对称设计下,网络为每个图像输出一致的深度映射。
前面部分代价体积构建都是mvsnet一样的,每幅图像的代价量是通过计算变形特征图和参考特征图的方差来构造的。
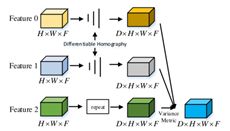
成本容积正规化
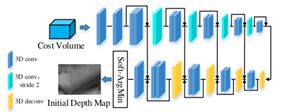
利用3D CNN对每个原始成本量进行规格化,生成一个概率量。之后,应用ArgMin操作来回归当前视图的深度映射。
之后是深度图优化,即使初始深度图已经是一个合格的输出,物体的重建边界可能会由于上采样而过度平滑。为了解决这一问题并提高性能,采用空间传播网络(SPN)来细化初始深度映射。
多视角遮挡推理
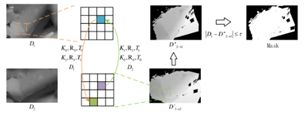
就是推理出一个mask,来表示在两个视角下均可见的点。
首先,将深度图映射到其他视图。然后,重新映射深度图映射回当前视图。最后,比较原始的深度图和映射回来的深度图从而得到掩模。
对于invalid的点公式如下:
|Di- D‘’j→i| > τ
τ = 5.
Loss部分即实现无监督
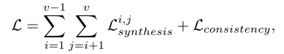
两部分,一个是View Synthesis Loss,另一个是Cross-view Consistency Loss:
![]()
其中Lu包含了视图映射的loss,SSIM以及Census transformation 的loss
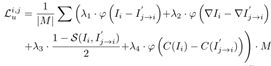
Ls是深度梯度,使其平滑
![]()
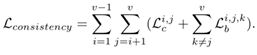
这里运用了一种新的交叉视图一致性损失
![]()
其中:
Lm: 原图像和重映射回来的图像loss
![]()
以及深度loss
![]()
Lb:另一部分是多视图亮度一致性损失,即
![]()
将其他视角的图像都映射到一个视角
M3VSNet: Unsupervised Multi-metric Multi-view Stereo Network
Huang, Baichuan, et al. “M^ 3VSNet: Unsupervised Multi-metric Multi-view Stereo Network.” arXiv preprint arXiv:2005.00363 (2020).
1 论文作用
无监督重在loss实现
这个方法在继续丰富loss函数,为了提高点云重构的鲁棒性和完整性,提出了一种新的多度量损失函数,结合像素和特征损失函数,从匹配对应的不同角度学习内在约束。
此外,该论文还在三维点云格式中加入了法向深度一致性,以提高深度估计图的准确性和连续性。
2 Method
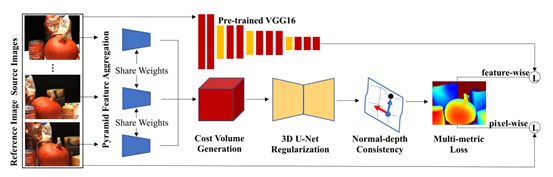
M3VSNet的基本架构由三部分组成,即金字塔特征聚合、基于方差的成本量生成和3D U-Net正则化,如图所示。金字塔特征聚合从低级到高级表示中提取特征,并具有更多的上下文信息。然后,使用与MVSNet相同的基于方差的成本量生成和3D U-Net正则化方法生成初始深度图。M3VSNet的高级体系结构由两部分组成,即标准深度一致性和多度量损耗。在生成初始深度图后,考虑到法向和局部表面切线的正交性,引入新的法向深度一致性来细化初始深度图。最后,构造了多度量损失,包括像素级损失和特征级损失。
金字塔特征聚合

使用的预训练的VGG16。这个结构主要是将高层特征和底层特征做了融合,从而获得更多上下文信息,更好提取特征。
之后的操作和mvsnet一样,最终构建成本体积,正则化形成初始的预测深度图。
法线深度一致性
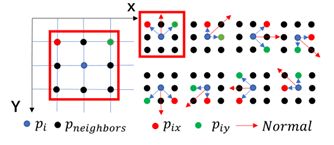
法线深度一致性可分为两个步骤。首先,通过深度的正交性计算法线;然后根据投影关系,由法线深度和初始深度推算出细化后的深度。
1)计算法线
根据向量叉乘,选择一个点为中心点,周围八个点为相邻点。
![]()
从而获得了i这个中心点的法线。
2)计算细化后的深度
那么对于每一个点,他都有作为八个相邻点的机会,从而根据周围八个点的法线,计算自己的refined的深度值。但是要考虑一个问题,更大的梯度表示获得的深度的不可靠性。所以加一个权重w‘。
首先计算梯度的影响
![]()
获得这个w后还要看他在八个点中的权重
![]()
最后计算出refined的深度值
![]()
Loss
实现无监督的
![]()
像素级别的,考虑光度一致性,结构一致性,以及深度平滑约束
![]()
特征级别,对网络中间提取的特征进行一致性约束(实际上借助语义进行监督)
![]()
![]()
Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation
这篇是AAAI2021
1 论文贡献
这个综合了数据增强和光度一致性以及语义的自监督,通过各种方式对自监督的效果进行增强。
同时指出使用这种方法的原因,因为不同视角下同一个点可能会出现光照强度不一致从而使光度一致性约束不够准确。
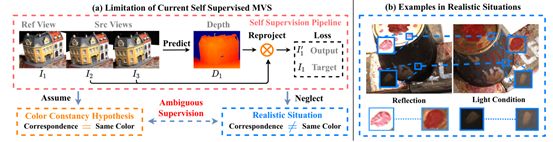
2 Method
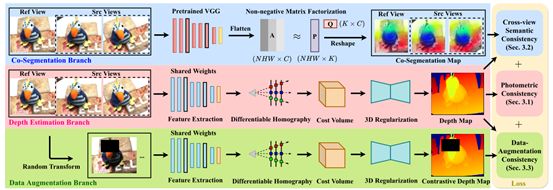
该方法分有三个分支,分别进行一个任务进行自监督。分别是深度估计、分割以及数据增强。
深度估计
老生常谈,与mvsnet方法相同,预测出一个深度图。然后使用光度一致性进行自监督。
联合分割
先是采用预训练的VGG16提取特征,然后使用非负矩阵分解。
非负矩阵分解是指能将一个矩阵A分解成两个矩阵P和Q,并且这三个矩阵都是所有元素非负的。通过最小化下式实现。
![]()
最终是要对特征图进行分解的,首先将多视角特征图连接在一起,(H,NW,C)→(NHW,C)非负矩阵分解→ (N HW, K) matrix P 和 (K, C) matrix Q 其中K就是类别的个数,这里指语义簇
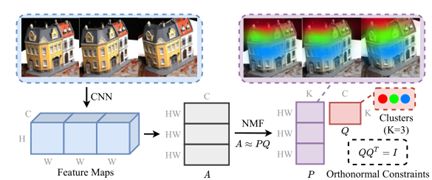
Q矩阵的每一行可以被视作每一个簇在通道维度上的簇心
P矩阵和行数就是就是像素的空间位置,然后P矩阵可以继续reshape成N个热图(H,W,K)。然后经过softmax层,获得N个热图S。那么就可以从语义上进行光度一致性约束,因为经过softmax归一化了,这里使用crossentropy
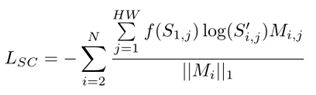
数据增强
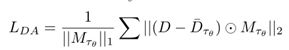
就是对图像加一个mask,这个预测出的深度图和不加mask预测出的深度图一样的。
具体来说有三个操作,加mask,伽马矫正调整图像亮度,像素值扰动。