Informer: Beyond Efficient Transformer for Long SequenceTime-Series Forecasting
Beyond Efficient Transformer for Long SequenceTime-Series Forecasting就是用Transformer的方法来对长时间的序列进行一个预测的问题。
这篇文章主要面向的问题是序列数据的预测,通过研究历史序列数据掌握其中的规律,进而去预测该序列未来的趋势;长时间序列包括它输入的时候是一个很长的序列,也包括输出的时候它预测一个很长的时间范围,比如说我们预测高速公路的车流量,可能是五分钟一个点,但是我要预测未来10天的或者半个月的那就相当于预测上千个点,这就是指这个长时间序列预测问题。
对长时间的序列进行预测有两个要求,一个是预测能力要比较好,还有一个是由于它的输入和输出序列是非常长的,所以对于这种长的输入输出要有比较高的效率。目前Transformer方法在序列预测上取得了比较好的效果,所以想用Transformer去解决一下这个问题,但是针对这种长时间序列预测的问题上,规范的Transformer有几个局限性。
Transformer的问题
1.计算self-attention的时间复杂度为O(L2)
2.输入长时间序列导致内存占用过大
3.对于长时间序列预测问题,预测速度下降
首先就是Transformer的时间复杂度和空间复杂度都是O(L2)(L序列长度)因为这个Transformer就是利用self-attention构成Encorder Decoder模型,self-attention就是对一个时刻计算其他所有的时刻与他的相似程度,就是重要性;Transformer是堆叠了好多个mult-head self-attention,如果你的时间序列很长的话,它堆叠多然后就导致它变量多,占用的内存过大;TF目前很多的深度网络模型一样是Encorder和Decoder的结构,它在解码的时候动态的,需要根据上一个Encoder输出然后输入到Decoder里面来逐步预测,所以当预测的时间点越长,速度越慢,这个结构在长序列的输入输出的情况下,效率就不是很好。
三个改进:
1. ProbSparse Self-attention
2. Self-attention Distilling
3.Generative Style Decoder
所以就引出了本篇文章,他用的方法就是Informer,通过改进TS模型,更好的预测能力。三个改进解决了上面的三个问题。1.在Self-attention的时候用了一个ProbSparse来降低时间复杂度;2.是做了一个Self-attention Distilling(蒸馏自注意),因为它输入的序列是非常长的,所以它认为信息在这些序列中是比较稀疏的,所以它进行了一个蒸馏提取,将输入的长序列信息进行一个浓缩;3.针对上面提到的这个预测的效率问题,对decoder提出了一个generative style decoder,不再使用step by step的方式,滚动预测,一步到位把未来的值全部计算出来,使得预测的效率会变得更高。这就是这篇文章整个的一个逻辑。

Informe整体框架图,提出的Informer模型整体上仍然保存了Encoder-Decoder的架构。 在上图左边为编码器,其编码过程为:编码器接收长序列输入(绿色部分),通过ProbSparse自注意力模块和自注意力蒸馏模块,得到特征表示。右边为解码器,解码过程为:解码器接收长序列输入(预测目标部分设置为0),通过多头注意力与编码特征进行交互,最后一次性直接预测输出目标部分(橙黄色部分)。

怎么把时序数据输入informer,首先把time series的data在scalar部分projection到需要的维度,然后给他position embedding加上位置信息,又加上了week month时间相关的embedding,如果你的数据不是和时间序列相关的,也可以按自己需要,数据和什么周期有关,可以自行的加上类似的embedding。(holiday)得到输入到informer的数据。
一、ProbSparse Self-attention
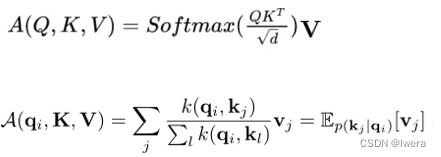
在运算过程中把attention可视化出来,发现邻接矩阵(相关系数矩阵)是非常稀疏的,有一些(概率)值是非常小的,对attention是不产生影响的,想把影响比较小的值给去掉,使得计算量变得比较小。
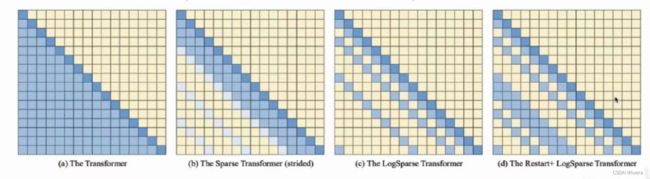
对于挑战1来说(a)每一对input之间都会进行一个attention的计算,那我们一个最基本的思路就是降低attention的计算量,仅计算一些重要的或者有代表性的attention即可。比如(b)这个方法涉及了一个稀疏化的attention方法,来减少attention的计算量,(c)是设计了一个呈log分布的稀疏化方法,更大程度上减少attention计算量,(d)在logsparse的基础上从一个位置重新restart,相比sparse增加了一些计算量,这些工作都是基于启发式的假设,计算不计算哪个attention是用一个规则来决定的,缺点:不能自适应的根据具体的情况去计算哪些attention。

假设他所有时刻一样重要,就是均匀分布的概率;但实际上某一个时刻比较重要的话,与均匀分布的差距比较大,(对比)用kl散度来评估观察得到的分布与假设的分布的差距,差距越大,kl值越大,这个时刻越重要,这个时刻的attention比较重要。常数项去掉。

利用稀疏性度量,算出不稀疏的(包含信息较多),u是给定的参数(c常数×整个数据量的Ln,c是一个常数采样因子),对于所有的query来说,我们选取M(qi,K)排名前u的若干query作为Q拔,这样就把稀疏的信息给提取出来了,对于每个key就只需要计算O(ln LQ)次点积。
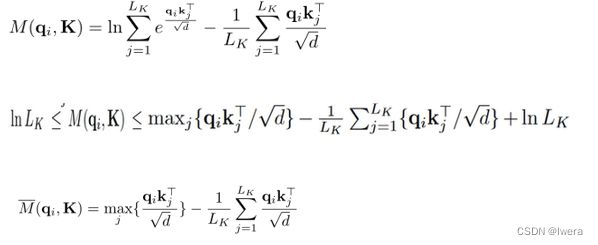
这里还有一个问题,还是计算了qi和kj所有的乘法,虽然在后面计算的时候是用的前u个,但是计算稀疏性的时候还是没有达到降低计算复杂度的目的。所以就用了一个理论性比较强的方法,近似计算,去近似的计算稀疏程度。这就是他做的第一个改进,通过该方法解决了Transformer的第一个问题,即:self-attention机制的二次计算复杂度问题。
二、Self-attention Distilling
接下来就是提出的第二个改进,就是Self-attention Distilling的过程,因为输入的序列很长,可能包含的信息不是很集中,所以就进行了一个稀疏信息的浓缩和蒸馏,用更低的一个维度来进行表示。
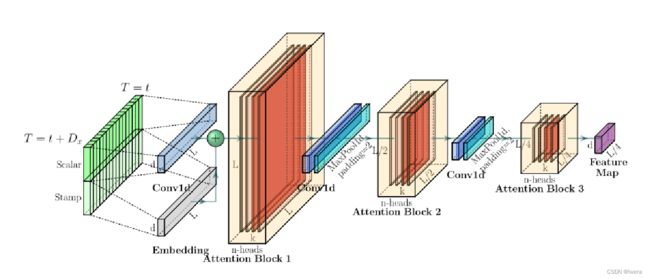
同时为了增强注意力蒸馏机制的鲁棒性,作者还构建了主序列的多个长度减半副本,每个副本是前一个副本长度的一半,这些副本序列和主序列经过同样的注意力蒸馏机制,从而构建多个长度为L/4的特征图。最后将这些特征图拼接起来,构成输入encoder最终的特征图。通过以上方法,可以逐级减少特征图的大小,在计算空间上不会耗费过多的内存,解决了Transformer的第二个问题:高内存使用量问题。

三、Generative Style Decoder
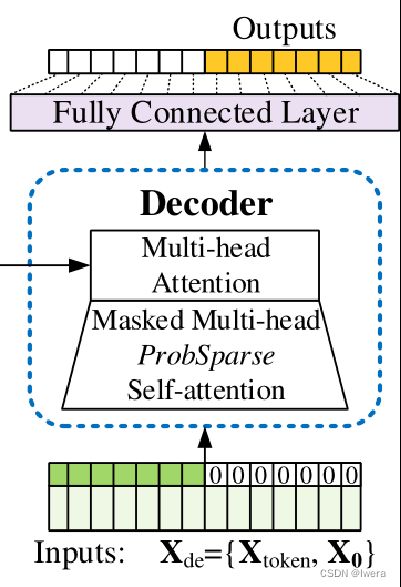
挑战3解决输出过长无法进行快速预测的问题,原因是因为原始的TF是动态解码的decoder,即一步一步进行迭代输出,不同的是,本文采用的是批量生成式预测直接输出多步预测结果。 通过多个output一起计算输出的方法,解决了Transformer在LSTF中的第三个问题:预测长期输出的效率问题。
Experiment
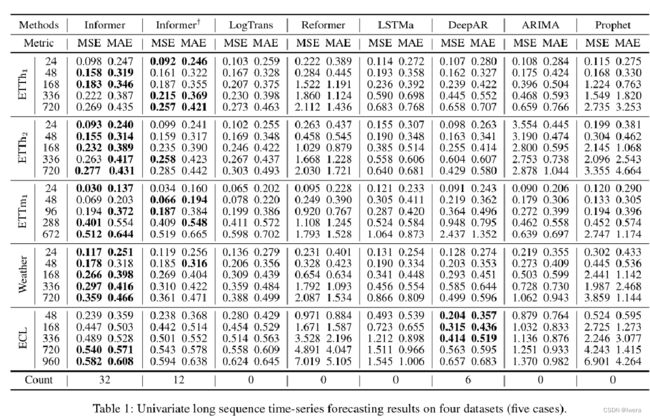
不光是对比不同模型不同数据集上,在不同的步长(不同采样粒度/频率)上进行了对比。单变量的时序预测任务上Informer在很大程度上都击败了baseline方法,最后一行是count(最好的+1)。Informer随着输出的长度的增加,预测的误差能够平稳而缓慢的上升,而不是说突增。Informer+在Informer的基础上去掉了ProbSparse Self-attention ,可以看到它在很多任务上表现出了和Informer差不太多的水平,但是在总的比分上可以看出12落后于32,也就说明了提出的第一个改进ProbSparse在很多数据集上是成立的。
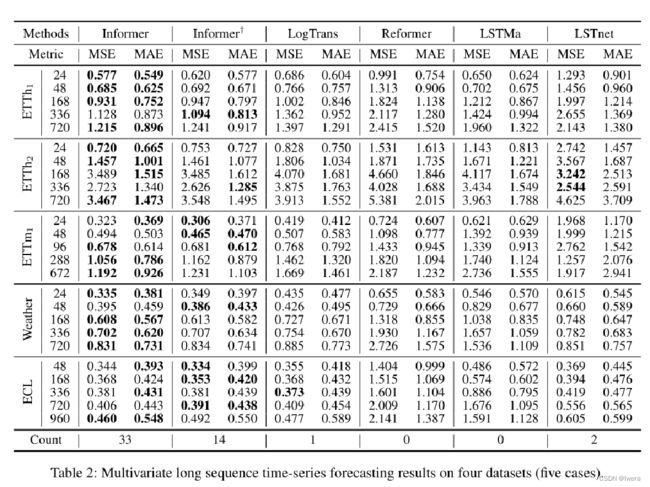
在多变量时序预测任务上,Informer依然击败了baseline,并且和刚才一样,Informer依然优于Informer+,同样可以得出:在多变量预测任务上,ProbSparse的假设也是成立的。
参数分析:
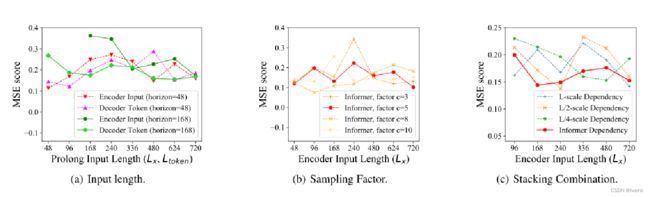
对于参数的敏感性做了三个实验。1.Input 当我预测短序列的时候(48),最初延长encoder的输入长度,会降低性能(MSE),但是进一步增加输入长度,会使结果变得更好,同时在预测长序列的时候,输入的时间越长,平均误差越低;2.c=3,随着input length的增加,性能逐渐变差,c=8/10时,性能不是太稳定,所以c设置为5;3.long stack对输入更敏感,部分原因是接收到的长期信息较多。

消融实验:首先测试的是ProbSparse Self-attention的效果,Informer+在Informer的基础上去掉了ProbSparse Self-attention,从这个实验可以看出informer在刚开始的时候和informer+比预测结果并不理想,但是随着encoder input的提高,informer的效果就比较好,并且在同样的预测长度下,informer能够达到更好的效果。(- 不能预测了,超过了最大内存,无法计算)informer可以游戏的减小内存的使用并且达到不错的效果。

然后测试了self-attention distilling的效果,将distilling从informer+中移除记为informer++,可以看到移除distilling后会达到更好的效果,但是他不能对较长的序列进行预测,(720,960),还有一个发现是当预测较长的序列时(480)更长的input是有助于提升模型的性能的。
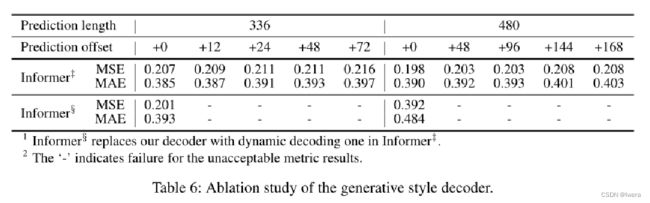
然后是测试生成式的decoder,在informer++的基础上,将decoder换成了transformer原始的dynamic decoding,可以看到最终的效果变差。 在预测480这里做了一个更大胆的尝试,偏移到了168个点,可以看到模型依然保持一个比较文档的结果。
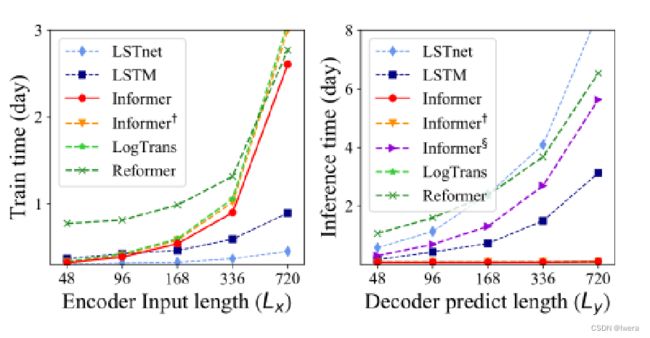
左边是训练过程,在基于transformer的模型中,informer获得了最佳的训练效率;右边是一个预测的图,informer是远远高于其他的方法的。