浅谈 one-stage 与 two-stage 目标检测方法
由于目前实习及找工作的原因,博客更新的频率下降,而在面试过程中也发现,虽然论文是看过了,包括也有输出一些论文笔记,但是很多时候无法形成自己对该领域的一个概括性的认知,无法粗中有细,细中有粗,主要还是基本功不扎实。反应了自己在日常学习中的学习问题,所以错失一些很好的面试机会,回首发现每一次自己都是在这种地方跌倒的,痛定思痛,准备开启一系列的总结比较之旅,论文不仅仅是单个存在,博客只是一个整理自己思路,分享知识的方法,如果想形成自己对一个领域的理解,精力足够的话还是推荐各位自己从头到尾,认真阅读原论文+复现代码,遇到不理解的地方,再配合他人的文章进行理解会比较好。本系列文章会不定期更新,主要是想结合论文和相关复现代码,把一些经典的和新的框架,方法,相互之间的联系与区别,里面会贴出一些自己对于问题的见解,若有理解有误之处,还请留言指正。
下面言归正传。
不用多说,提到 one-stage,two-stage 这个方法,了解过一点目标检测的同学肯定都能朗朗上口,默背出来:
one-stage 就是: YOLOv1,YOLOv2, YOLOv3,SSD
two-stage 就是: R-CNN,fast R-CNN,faster R-CNN
(不能一口气吃个胖子,FPN,RetinaNet 等我们稍后再谈)
原文链接:https://pjreddie.com/publications/
参考代码:https://github.com/xiongzihua/pytorch-YOLO-v1
YOLO v1
首先 YOLO v1 的野心很大,论文里有提到人们看一眼图片基本就可以判断出有什么物体在图片里,并且知道它们在图片的什么的地方,快而准,正因为这样,才使人们可以在驾驶等场景中迅速做出反应,像这样快而准的目标检测系统无疑在自动驾驶或者机器人领域会解锁更多的可能。
而前面的 R-CNN 系列,再快,faster r-cnn 还是需要两个阶段,还是很慢,那么索性就一个网络直接分类和坐标一起出来算了,这样才更符合真是人类的检测系统,而且网络可以端到端,可以学习到更全局的特征,可以改善因为滑动窗口(因为其 region proposal 是 SS 方法)只有局部信息而带来的 fast r-cnn 背景错检率高的问题。
下面要详细介绍的一个就是数据预处理,还有就是最后 YOLO v1 Loss 的计算,然后就是网络结构。
网络结构
YOLO v1 整体的网络结构就是简单的 分类网络卷积部分 + 2 层全连接层 的结构,以文中结构为
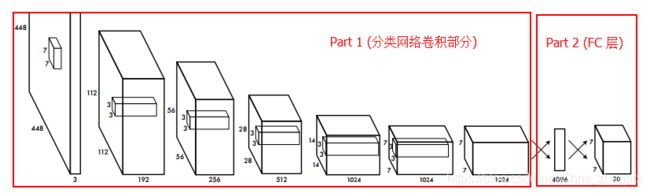
这里 Part 1 也很容易的替换成 VGGNet 13,VGG16,ResNet 50 等,只要按照规定尺寸输入降成 7x7 的之后接 Part 2 (2 个 fc 层):
classifier = nn.Sequential(
nn.Linear(C * 7 * 7, 4096), # C 代表输入通道数,上图为 1024, VGG16 则为 512
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 1470), # 1470 = 7x7x30
)
最后将 classifier 的输出经过 sigmiod 函数以后 reshape 成 batchsize x 7 x 7 x 30 输出即可。
数据预处理
这里主要是介绍文中网格化处理的方式,以及对原本数据集格式的修改,让其可以跟网络输出直接算 Loss。
以 VOC 为例,标准集提供的是图片及对应的 xml 文件,而 xml 文件中保存有图片中包含的真值框的坐标信息和类别信息,这里为了方便使用,可以现读取出来,保存成 txt 的文本文件,其格式为:
n0001.jpg,x1,y1,x2,y2,c,x1,y1,x2,y2,c
n0002.jpg,x1,y1,x2,y2,c,x1,y1,x2,y2,c,x1,y1,x2,y2,c
…
而这里对图片进行网格化处理,则是体现在坐标变换中,首先为了计算 loss 方便,文中把所有的坐标信息(即,cx,cy,cw,ch)都转换到了 0-1 之间, 以下面具体图片为例,假设有一张原图分辨率为 12 x 12,我们将它分割成 6x6 的网格。而其中有一个目标为红色虚线框位置:
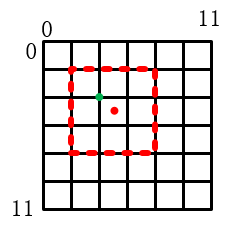
- 首先根据每一个 bbox 的 (x1,y1,x2,y2)= (2,2,8,8)得到这个坐标的中心点位置和宽高(cx,xy,cw,ch)=(5,5,6,6)
- 现在我们需要把刚才的 中心点位置和宽高(5,5,6,6)映射到 0-1 之间,其中心点所在的网格左上角为( 5 w \frac{5}{w} w5 , 5 h \frac{5}{h} h5, 6 w \frac{6}{w} w6 , 6 h \frac{6}{h} h6)= ( 5 12 \frac{5}{12} 125 , 5 12 \frac{5}{12} 125, 6 12 \frac{6}{12} 126 , 6 12 \frac{6}{12} 126),而负责这个 object 的网格的坐标为(( 5 12 \frac{5}{12} 125)*S = 2.5,( 5 12 \frac{5}{12} 125)*S = 2.5)向上取整为 (3,3),因为坐标从 0 开始,再各自减1,最后就是对于 6x6 的网格就是 [2,2] 的位置负责预测这个物体,而 [2,2] 位置的网格左上角坐标(绿点)为(4,4),归一化以后为:( 4 12 \frac{4}{12} 124, 4 12 \frac{4}{12} 124),所以最后转化后的坐标为 (( 5 12 \frac{5}{12} 125 - 4 12 \frac{4}{12} 124)*6,( 5 12 \frac{5}{12} 125 - 4 12 \frac{4}{12} 124)*6)=( 1 2 \frac{1}{2} 21 , 1 2 \frac{1}{2} 21),可以看到红色中心点确实是在 [2,2] 网格的正中心,所以相对左上角的偏移为网格宽度的一半,所以这个真值框,最后转化为( 1 2 \frac{1}{2} 21 , 1 2 \frac{1}{2} 21, 6 12 \frac{6}{12} 126 , 6 12 \frac{6}{12} 126)=(0.5,0.5,0.5,0.5)
未完待续…
YOLOv2
better
简单快速的 YOLO,相对于 two-stage 的方法,还是存在一定的问题的,例如有大量的定位错误,以及较低的召回率。
基于上述问题, YOLO v2 进行了如下改进:
- 加入了 BN 层来改善网络的性能(+2% mAP)。
- 并且使用更高分辨率的图片来训练网络(预训练分类时是 224 ,检测训练时,先在 448 的 ImageNet 上 微调 10 个 epoch 再用 448 检测训)(+ 4% mAP)。
- 加入 anchor boxes。(增加召回率)
在 加入 anchor 机制以后主要遇到如何选择更合适的预选框的问题,还有就是选择完预选框以后前期训练不稳定的问题。对于第一个问题,用 k-means 聚类来选取预设框尺寸。第二个,变换了数据的预处理方式,对坐标 tx,ty 预测加入了一个 sigmoid函数,让其对异常值进行一个平滑过滤,然后将 tw,th 映射到了一个对数域中,并且增加了多层的特征,26x26 直接下采样到 13x13 然后跟原来的 13x13 拼接在一起, 进行预测,多尺度大概加了 1% mAP。
…(边框回归后面将做详细介绍)
faster
这里主要提出了自己的网络,Darknet-19, 上面因为加入了 anchor 所以可以直接从卷积层预测,所以可以抛弃全连接层(降低网络参数量),然后 darknet 主要是在两个 3x3 之间使用 1x1 卷积层来降低通道数,然后加入了 ave pooling。
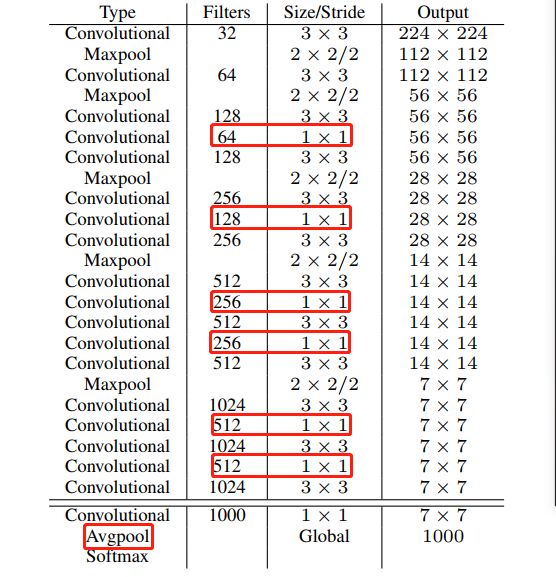
stronger
则是提出了新的合并策略,可以联合训练分类和检测的数据集,增加检测的类别,这里不过多介绍。
YOLOv3
YOLO v3 更像是一个集大成者,相对于 YOLO v2 又有了一定的变化,下面梳理一下:
- 预测的 4+1+ num_classes 的策略,前面 4 个还是没有变,分别是 tx,ty,tw,th,中间一个由之前的 IoU 值,直接变成了 objectness 分数,用 logistic 回归直接预测,表示是否是物体的分数,确定是物体应该为 1。
- 类别预测的话没有用 softmax,而是使用了二值交叉熵。因为使用 softmax 的一个假设就是类别之间相互独立,但是某些数据集是具有包含关系的(例如,狗和动物,女人和人,这种类别关系)。
- 从多尺度输出。这里类似于 SSD,YOLO v2 虽然有用多层信息,但是是变换尺寸以后合并在一起,仍然只从最后一层尺寸输出,而 YOLO v3 是从,52x52, 26x26, 13x13 三个分辨率分别输出,这里拼接方法是将 13 x 13 分辨率的结果(s1)上采样成 26 x 26,然后与原先的 26 x 26 拼接在一起得到 s2,把 s2 再上采样成 52 x 52,再与原先的 52 x 52 拼接的到 s3,结果输出是将 s1,s2,s3 并行的讲过 2 个 3 x 3 卷积层然后输出。
- anchor 的聚类中心从 5 个变为 9 个,可能也是为了方便均分在 3 个尺度上面。
- 在 DarkNet-19 中加入了 ResNet 结构,构建了更有效的 Darknet-59 。
SSD
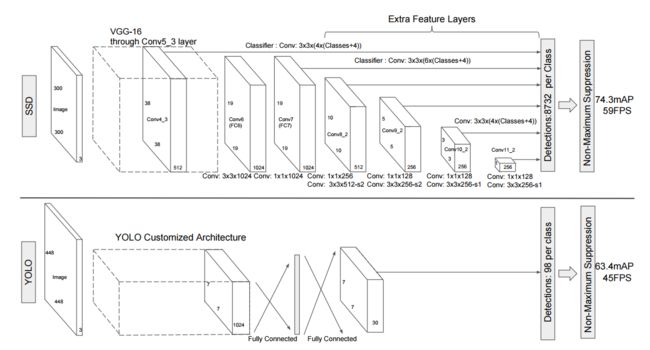
总的来说,对于 SSD 主要是将二阶分类器的 RPN 阶段去除,使用神经网络来进行坐标的回归,然后使用了多层网络的输出来进行不同尺度 bounding box 的预测,且他们都是相互独立的。然后就是与预选框尺寸的设定方案和训练时,选择正负样本的方式与 YOLO 方法都大不相同。
这里首先介绍一下 SSD 中的 loss 构成。
首先明确每一个预测框都有 4(location)+ 1(confidence)。

这里的 N 是所有符合条件的框,挑选这些框的过程主要是:
- 设置一个阈值(一般为 0.5),与 真值框 IoU 大于这个阈值的都视为正样本
- 负样本会很多,所以用 hard sample 的策略, 将所有负样本通过 confidence 进行排序,选择靠前面的负样本,比例大概为 正:负 = 1:3
- 由上面的 N 个框来构建 Loss, L l o c L_{loc} Lloc 是对所有正样本做 Smooth_L1_loss, L c o n f L_{conf} Lconf 则是交叉熵函数。

(图片来自:https://www.cnblogs.com/hellcat/p/9351802.html)
… … 未完待续 … …