PyTorch单卡/多卡下模型保存/加载
由于训练和测试所使用的硬件条件不同,在模型的保存和加载过程中可能因为单GPU和多GPU环境的不同带来模型不匹配等问题。这里对PyTorch框架下单卡/多卡下模型的保存和加载问题进行排列组合(=4),样例模型是torchvision中预训练模型resnet152,不尽之处欢迎大家补充。
1 数据格式与存储内容
1.1 模型存储格式
PyTorch存储模型主要采用pkl,pt,pth三种格式。就使用层名来说没有区别,这里不做具体的讨论。第5部分中列出了笔者查阅到的一些资料,感兴趣的读者可以进一步研究,欢迎留言讨论。
1.2 模型存储内容
一个PyTorch模型主要包含两个部分:模型结构和权重。其中模型是继承nn.Module的类,权重的数据结构是一个字典(key是层名,value是权重向量)。存储也由此分为两种形式:存储整个模型(包括结构和权重),和只存储模型权重。
from torchvision import models
model = models.resnet152(pretrained=True)
# 保存整个模型
torch.save(model, save_dir)
# 保存模型权重
torch.save(model.state_dict, save_dir)对于PyTorch而言,pt, pth和pkl三种数据格式均支持模型权重和整个模型的存储,因此使用上没有差别。
2 单卡和多卡模型存储的区别
PyTorch中将模型和数据放到GPU上有两种方式——.cuda和.to(device),笔者一般使用前者。之后如果要使用多卡训练的话,需要对模型使用torch.nn.DataParallel。示例如下:
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 如果是多卡改成类似0,1,2
model = model.cuda() # 单卡
model = torch.nn.DataParallel(model).cuda() # 多卡之后我们把model对应的layer名称打印出来看一下,可以观察到差别在于多卡并行的模型每层的名称前多了一个“module”:

单卡模型的层名
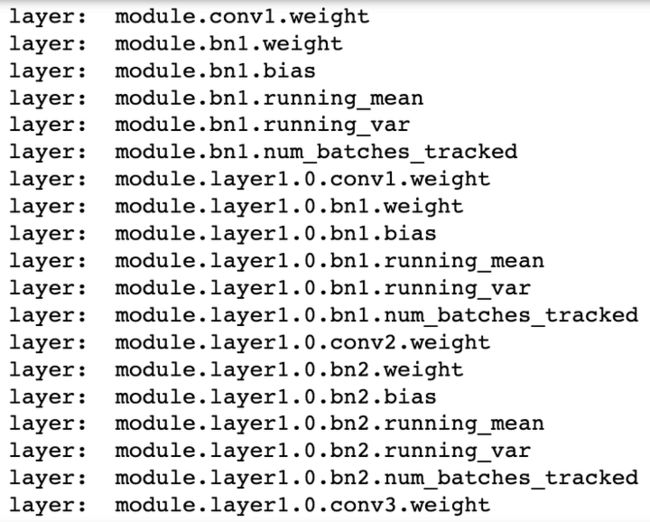
多卡模型的层名
这种模型表示的不同可能会导致模型保存和加载过程中需要处理一些conflicts,下面对各种 可能的情况做分类讨论。
3 情况分类讨论
3.1 单卡保存+单卡加载
在使用os.envision命令指定使用的GPU后,即可进行模型保存读取操作。注意这里即便保存和读取时使用的GPU不同也无妨。
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
loaded_model = torch.load(save_dir)
loaded_model.cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_dict
loaded_model.cuda()3.2 单卡保存+多卡加载
这种情况的处理比较简单,读取单卡保存的模型后,使用nn.DataParallel函数进行分布式训练设置即可(相当于3.1代码中.cuda()替换一下):
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = nn.DataParallel(loaded_model).cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_dict
loaded_model = nn.DataParallel(loaded_model).cuda()3.3 多卡保存+单卡加载
这种情况下的核心问题是:如何去掉权重字典键名中的"module",以保证模型的统一性。
对于加载整个模型,直接提取模型的module属性即可:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = loaded_model.module对于加载模型权重,有以下几种思路:
-
(推荐)去除字典里的module麻烦,往model里添加module简单:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model = nn.DataParallel(loaded_model).cuda()这样即便是单卡,也可以开始训练了(相当于分布到单卡上)
-
遍历字典去除module
from collections import OrderedDict
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
new_state_dict = OrderedDict()
for k, v in loaded_dict.items():
name = k[7:] # module字段在最前面,从第7个字符开始就可以去掉module
new_state_dict[name] = v #新字典的key值对应的value一一对应
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = new_state_dict
loaded_model = loaded_model.cuda()3.4 多卡保存+多卡加载
由于是模型保存和加载都使用的是多卡,因此不存在模型层名前缀不同的问题。但多卡状态下存在一个device(使用的GPU)匹配的问题,即保存整个模型时会同时保存所使用的GPU id等信息,读取时若这些信息和当前使用的GPU信息不符则可能会报错或者程序不按预定状态运行。具体表现为以下两点:
-
读取整个模型再使用nn.DataParallel进行分布式训练设置
这种情况很可能会造成保存的整个模型中GPU id和读取环境下设置的GPU id不符,训练时数据所在device和模型所在device不一致而报错。
-
读取整个模型而不使用nn.DataParallel进行分布式训练设置
这种情况可能不会报错,测试中发现程序会自动使用设备的前n个GPU进行训练(n是保存的模型使用的GPU个数)。此时如果指定的GPU个数少于n,则会报错。在这种情况下,只有保存模型时环境的device id和读取模型时环境的device id一致,程序才会按照预期在指定的GPU上进行分布式训练。
相比之下,读取模型权重,之后再使用nn.DataParallel进行分布式训练设置则没有问题。因此多卡模式下建议使用权重的方式存储和读取模型:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取模型权重,强烈建议!!
torch.save(model.state_dict(), save_dir)
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model = nn.DataParallel(loaded_model).cuda()
loaded_model.state_dict = loaded_dict如果只有保存的整个模型,也可以采用提取权重的方式构建新的模型:
# 读取整个模型
loaded_whole_model = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_whole_model.state_dict
loaded_model = nn.DataParallel(loaded_model).cuda()
------
另外,上面所有对于loaded_model修改权重字典的形式都是通过赋值来实现的,在PyTorch中还可以通过"load_state_dict"函数来实现:
loaded_model.load_state_dict(loaded_dict)4 测试环境
OS: Ubuntu 20.04 LTS
GPU: GeForce RTX 2080 Ti (x3)
5 参考
pytorch 中pkl和pth的区别?
What is the difference between .pt, .pth and .pwf extentions in PyTorch?