AlexNet 学习笔记
- by Xie Zhe & One Way
AlexNet 简记
简介
12年,神经网络大概经历了 Perceptron - LeNet - AlexNet 的演变。AlexNet 在ILSVRC-2012大赛取得好成绩(15.3%)。也容易发现,AlexNet 与LeNet 极其相似,或许是受到了老师LeCun的启发,或许是在实现LeNet的过程中优化了结构,诞生了AlexNet。两者的结构图如下:

- Average Pooling
- Sigmoid or tanh nolinearity
- Fully connected layers at the end

- Max pooling, ReLu nolineariy
- More data and bigger model
- GPU implementation( trained on two GPUs)
- Dropout regularization
如果AlexNet 没有因为GPU的限制而放在一个GPU中跑,结构很相似,既有传承性,又有区别。AlextNet适宜的添加合适的卷积核,增加网络深度,调整pooling方法,改变激活函数,运用了Data Augmentation 及dropout等方法,扩大了分类器分类的种类,提高了正确率。
结构
-LeNeT
LeNet的结构比较简洁:
L e N e t = ( c o n v + a v e r a g e p o o l i n g × T a n h ) × 2 + f c × 2 + G a u s s i a n c o n n e c t i o n LeNet=(conv + average\ pooling \times Tanh)\times 2+fc\times 2+ Gaussian\ connection LeNet=(conv+average pooling×Tanh)×2+fc×2+Gaussian connection
用5x5的kernel作卷积,用均值法作下采样。整体思路应该是: 特征提取 + 特征分类。前半部的卷积网络用作特征提取,后半部的全连接层用作特征分类。 最后的Gaussian 层,做了个 y i = ∑ j ( x j − w i j ) 2 y_i =\sum_{j}(x_j-w_{ij})^2 yi=∑j(xj−wij)2 每个输出ERBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,ERBF输出越大。类似匹配程度的惩罚项。原文中说:
- Finally,the output layer is composed of Euclidean Radial Basis Function units(RBF), one for each class, with 84 inputs each.
- Can be interpreted as the unnormalized negative log-likelihood of Gaussian distribution in the space of configuration of layer F6
-AlexNet
AlexNet 把卷积层提高到了5层,后加3层全连接层:
A l e x N e t = ( c o n v + R e L u + N o r m + M a x p o l i n g ) × 2 + c o n v × 3 + f c × 3 + s o f t m a x AlexNet=(conv+ReLu+Norm+Maxpoling)\times2+conv\times3+fc\times3+softmax AlexNet=(conv+ReLu+Norm+Maxpoling)×2+conv×3+fc×3+softmax
AlexNet 则是增加了卷积层的深度, 224x224x3 的图象输入网络中,经过卷积,激活,在激活的同时使用LRN最大化提取feature map,最后连接dropout的全连接层防止过拟合。
特点
- 使用了ReLu
- 加入Local Response Normalization
- GPU并行训练
- Data Augmentation
- Dropout
为什么?
为什么LeNet 要是这种结构?
LeNet的大体结构依然是 特征提取+特征分类。传统算法诸如模糊,增强,滤波皆有用到kernel。或许LeCun 试图用卷积神经网络的办法,去寻找一个可能减少手动算法的设计。LeCun 把网络结构中每层的channel 称作 feature map。 随着每层的加深,他试图去通过控制感受野来控制feature map 关联的区域大小,试图通过卷积提取出众多的局部特征,通过Fc进行分类。
为什么LeNet 要加下采样(sub-sampling)?
- 目的 1.
我查看论文原文,LeCun说:Once a feature has been detected, its exact location becomes less important. Only its approximate position relative to other features is relevant …(举了一个“7”的例子)… potential harmful because the positions are likely to vary for different instances of the character. 他试图去通过下采样的方式提高模型泛化能力,原文中用了 2x2 receptive field 平均采样。 - 目的 2.
个人认为是为了更好地提取重要信息从而进行特征分类。通过减少node个数,更方便的进行 10 class 分类。
为什么最大池化比平均池化效果要好?
- 个人认为 pooling的主要作用是为了更好降维。那么max pooling 取最大,如果改成可训练的加权pooling效果会不会更好?
- 进一步的,用无overlap的2x2的卷积kernel代替pooling 会取得什么样的结果?
为什么AlexNet 选择ReLu?


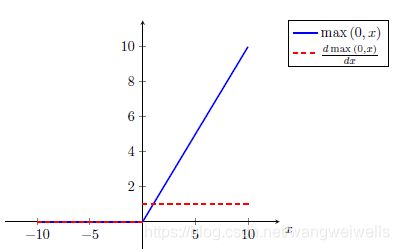
s i g m o i d : σ ( x ) = 1 1 + e x p ( − x ) sigmoid: \sigma(x) = \frac{1}{1+exp(-x)} sigmoid:σ(x)=1+exp(−x)1 t a n h : t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) tanh: tanh(x) = \frac{exp(x)-exp(-x)}{exp(x)+exp(-x)} tanh:tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x) R e L U : ( x ) = m a x ( 0 , x ) ReLU: (x)=max(0,x) ReLU:(x)=max(0,x)
由图可知,当x过大时,梯度容易出现饱和(梯度消失)。虽然可以通过预先Normalize 来规避,但是计算 e x p exp exp会影响计算速度。ReLu 可以避免梯度消失并可以更好的加速拟合提高速率。
ReLu优点:
- 当x较大时,不会出现饱和
- 计算效率高
- 实际情况中ReLu收敛速度更快
为什么要dropout?
dropout出自Hinton在2012年的一篇paper[4],它的作用是防止过拟合。前面提到卷积层的作用是特征提取,全连接层的作用是特征分类,特征提取不存在过拟合的问题,所以更确切的说,dropout解决的是全连接层的过拟合问题。全连接网络具有很强的学习能力,神经元数量足够的情况下,通常有很多组参数weights都可以使模型很好的拟合训练数据,特别是当训练数据较少时。但是通常训练出来的weights在测试集上效果不如训练集,也就是训练过拟合了。过拟合的一个原因就是同一层神经元的co-adaptation,它是指多个神经元重复的检测了同一个特征,所以co-adaptation会使得网络不能发挥它最大的能力,并且存在计算的浪费,理想状态下,我们希望每个神经元都是一个独立的feature detector。dropout通过以0.5的概率断开每个神经元解决神经元的co-adaptation问题。
虽然每次训练出来的模型都会过拟合,但是由于每次过拟合的方向不一样,所以将多次训练的模型的输出平均也是个解决过拟合的方法,这种方法的时间代价比较大。从这个角度看,由于dropout的存在,对每个训练case,都是一个不同的网络模型去拟合它,而在预测阶段,采用所有神经元的输出,并将输出乘以dropout的系数0.5,类似于多模型的平均,但是时间代价要小得多。
Data Augmentation中有什么值得注意的?
分为两部分,首先是图片的截取和水平的镜像,通过这种方式可以将一张训练图像增强到2048张,但是在测试时,可能考虑到计算量,只将一张测试图像增强到10张,取10张图像softmax输出的平均作为最终的预测概率。
第二部分是RGB通道强度的亮度变化。先对所有的train set图像做PCA,得到train set中最常见的亮度情况,然后对于每张训练图像,按一定的强度高斯随机地加入这个亮度。(作者似乎是想通过对所有train set 作PCA来获取自然图象的scheme,这种自然图象的scheme不会随亮度对比度变化而变化。个人认为作者是为了模拟自然情况下光线对识别物体产生的影响-待研究)
为什么要使用三层全连接层?
使用多层全连接层或许是为了更好的进行特征分类。但数量过多的fc层又会占用过多的训练参数。
思考
-
LeNet 感觉上和传统算法有一丝又一丝的联系。思想上依然保留着传统算法的直觉,比如先特征提取,再分类。LeCun 力求在是在可理解的合理的范围内进行的。设计的结构也力图通过卷积层级的加深扩大感受野,并“扩散”出于“合理”感受野下的众多相关特征图力求“Different feature mas are forceed to extract different features”。这种特征图小而多,包含了众多目标图象的局部信息。LeCun通过调整kernel大小,调整subsampling,特征提取的感受野控制到自己认为的合理的范围内。 然后进一步把包含众多特征的特征图输入全连接层达到分类的目的。
-
AlexNet 是在原有神经网络基础上的开拓和加深。AlexNet 在前人的基础上(从他引用的文献可以看出)的创新融合性尝试非常多,很多都行之有效。有两个似乎目前来说并不是很常用但印象最深的是:
-
GPU的并行训练:从论文中可以看出,实验结果两个GPU训练的kernel学习到了频率、旋转、边沿及颜色信息。但是GPU1学习到的kenerl核与颜色不相关,GPU2 却与颜色相关。这种现象且不随初始化的改变所改变。(待研究)
-
Local Response Normalization(局部响应标准化)是在feature map的通道上做归一化操作,灵感来源于真是神经元的侧位抑制机制。LRN在相邻kernel生成feature map 之间引入竞争。个人认为LRN与Dropout 有相似之处, dropout 避免了同层神经元feature的相似,LRN则避免了相邻feature map 的相似。
-
- Activation function
Kind of motivated by this biological analogy of neurons either being inactive or active. 设定了一种使节点在给定阈值下是呈active 或inactive。
代码
待二次阅读时添加
附录:
-
参数设定:
- Dropout training with p = 0:5
- Batch size: 128
- Mini-batch GD + Momentum with alpha = 0:9
- Learning rate initialized: 1e-2; divided by 10 when validation accuracy plateaus.
- L2 weight decay 5e-40
-
结构设定:
ans =
25x1 Layer array with layers:
1 'data' Image Input 227x227x3 images with 'zerocenter' normalization
2 'conv1' Convolution 96 11x11x3 convolutions with stride [4 4] and padding [0 0 0 0]
3 'relu1' ReLU ReLU
4 'norm1' Cross Channel Normalization cross channel normalization with 5 channels per element
5 'pool1' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
6 'conv2' Convolution 256 5x5x48 convolutions with stride [1 1] and padding [2 2 2 2]
7 'relu2' ReLU ReLU
8 'norm2' Cross Channel Normalization cross channel normalization with 5 channels per element
9 'pool2' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
10 'conv3' Convolution 384 3x3x256 convolutions with stride [1 1] and padding [1 1 1 1]
11 'relu3' ReLU ReLU
12 'conv4' Convolution 384 3x3x192 convolutions with stride [1 1] and padding [1 1 1 1]
13 'relu4' ReLU ReLU
14 'conv5' Convolution 256 3x3x192 convolutions with stride [1 1] and padding [1 1 1 1]
15 'relu5' ReLU ReLU
16 'pool5' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
17 'fc6' Fully Connected 4096 fully connected layer
18 'relu6' ReLU ReLU
19 'drop6' Dropout 50% dropout
20 'fc7' Fully Connected 4096 fully connected layer
21 'relu7' ReLU ReLU
22 'drop7' Dropout 50% dropout
23 'fc8' Fully Connected 1000 fully connected layer
24 'prob' Softmax softmax
25 'output' Classification Output crossentropyex with 'tench' and 999 other classes
参考文献:
- http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
- https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- http://yeephycho.github.io/2016/08/03/Normalizations-in-neural-networks/
- Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. arXiv preprint arXiv:1207.0580, 2012.(https://arxiv.org/pdf/1207.0580.pdf)