Automatic Lip-reading with Hierarchical Pyramidal Convolution and Self-Attention for Image Sequences
标题:基于分层金字塔卷积和自注意力的无单词边界图像序列自动唇读
关键词:金字塔卷积(Pyramidal Convolution,Py Conv )、分层金字塔卷积(Hierarchical Pyramidal Convolution,HP Conv)、自注意力(self attention)、共识模块(Consensus Module)相当于融合模块
金字塔卷积论文:Pyramidal Convolution: Rethinking Convolutional Neural Networks
摘要:
在本文中,我们提出了一种新的深度学习架构来提高词级唇读。我们首先使用分层金字塔卷积(hierarchical pyramidal convolution,HPConv)和自注意力将多尺度处理结合到唇读的空间特征提取中。特别地,HPConv被提出来代替传统的卷积特征,导致模型发现精细嘴唇运动的能力的改进。接下来,为了处理表示给定数据库中单词的固定长度图像序列,提出了一种自注意机制来整合所有嘴唇帧中的局部信息,而无需假设已知的单词边界,以便我们的深度模型自动利用给定单词的相关帧中的关键特征。在LRW语料库上的实验表明,我们提出的体系结构达到了86.83%的准确率,相对于采用平均帧分数进行信息融合所获得的结果,错误率降低了约10%。对实验结果的详细分析还证实,从自注意力中学习到的权重在图像序列的两侧趋于零,并且将非零权重集中在给定单词的中间部分。
1 引言:
自动唇读,也称为视觉语音识别,旨在仅基于视觉信息来识别语音内容,尤其是由一系列基本视觉单元(也称为视位)组成的嘴唇运动[1]。由于视位和音素之间的一对多映射[2]所引入的歧义,唇读对于人和机器来说都是一项具有挑战性的任务。然而,当音频数据不可用时,鲁棒的唇读系统具有广泛的应用,例如无声语音控制系统[3],在嘈杂环境中辅助基于音频的语音识别[4],以及生物特征认证[5]。
自动唇读的传统方法(例如[6,7])通常包括空间特征提取器,例如感兴趣的嘴唇区域(RoIs)的离散余弦变换[8,9,10],然后是序列建模方案,例如隐马尔可夫模型[11,12,13,14],以捕捉嘴唇运动的时间动态。最近,由于两个方面的进步,自动唇读已经得到显著改善,即:(1)使用深度神经网络模型[15,16,17,18,19,20],以及(2)大规模可用的数据集用于训练[21,22,23,24,25]。大多数基于深度学习的模型通常由前端和后端组成,分别类似于传统方法中的特征提取器和顺序模型。然而,使用端到端训练,前端模块通常可以提取比在传统提取器中获得的图像特征更好的图像特征,以便后端模块捕捉用于改进唇读的有区别的时间信息。
在这项研究中,我们侧重于词级唇读,并采用野生唇读(LRW) [21]语料库进行实验。LRW是第一个也是最大的公开可用的英文单词级标签数据集。它由从BBC新闻和脱口秀中提取的固定长度的片段(1.16秒的29个图像帧,每秒25帧,没有指定的单词边界)组成。有超过1000个说话者和500个目标单词,这比现有的用于单词识别的唇读数据库要高得多。该集合中总共538,766个片段被分成三个子集,分别由488,766,25,000和25,000个样本组成,用于训练、验证和测试。这项任务非常具有挑战性,因为LRW语料库中使用的视频在头部姿势和灯光照明方面存在很大差异。
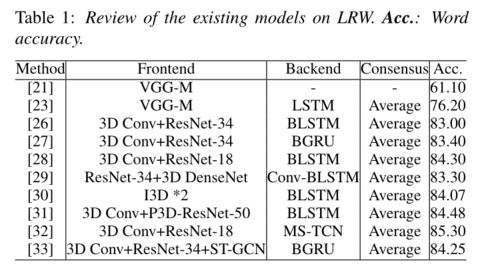
自从LRW发布以来,已经提出了许多新的模型。除了上面提到的前端和后端模块外,词级读唇模型通常还包含一个额外的共识模块,该模块在所有时间步骤中合并帧级的分数,以获得序列级的总体分数,从而预测所识别的单词。如表1所示,我们列出了现有的系统及其各自的前端、后端、共识和在LRW数据集上评估的单词准确性。我们观察到,所有的模型在前端都有单一空间大小的卷积核,而在共识决策中则沿时间维度平均。
在LRW[32]上的最先进的性能是由一个三维卷积层之后的18层残差网络(ResNet-18)[34]作为前端和一个多尺度时间卷积网络(MS-TCN)的后端组成的系统实现。要预测的500个词在序列层面的最终得分向量是通过沿时间维度对后端输出进行平均得到的。它是我们进行性能比较的基线。在本文中,我们通过提出一种新型的分层金字塔卷积(HPConv)来改进基线前端,它能够以多种空间分辨率处理输入,以取代ResNet-18中的标准二维卷积。此外,我们提出的后端利用自注意力来替代基线平均的共识,并专注于对应于口语的相关视频段的帧,以实现更好的分类精度。据我们所知,这是第一项将多尺度处理纳入前端并在单词级唇语的共识中采用非均匀的自注意力权重的工作。
2:提出的方法:
如图1所示,我们的系统可以分为三个主要部分:前端、后端和共识模块。前端模块将唇部RoIs X∈R^T×H×W的灰度序列作为输入,产生一个特征矩阵F2∈R^T×C1,其中T表示时间维度,H、W分别代表灰度唇部图像的高度和宽度。然后,通过应用空间维度的平均池化,总结出空间知识F2。接下来采用后端模块对时间动态进行建模。然后,输出的分数矩阵F3∈RT×C2被传递给共识模块以合并时间信息。最后,每个词的后验概率P是由随后的全连接和SoftMax层预测的。
图1:提出的系统的框图。每个箭头下方还显示了每个模块的输入及其对应的维度。我们的贡献是用黄色突出显示的前端和共识模块

基线[32]中的MS-TCN模块被保留为我们的后端,我们通过用我们提出的分层金字塔卷积取代ResNet-18中的标准卷积来改变前端,并将共识从平均化修改为我们提出的基于自我注意的共识。
2.1 分层金字塔卷积:
基线前端的ResNet-18使用标准的二维卷积来提取空间特征图。它只包含一个具有单一空间大小(K1,K1)的卷积核类型(在方形卷积核的情况下)。由于所有卷积核都具有相同的空间分辨率,所以提取的特征图只包含固定大小的空间背景信息。
我们分析了基线产生的一些错误,发现一个词的分类准确率随着该词中包含的视觉数量的增加而提高,也就是说,该模型在视觉内容少的词上表现得很差。这是有道理的,因为视觉内容较少的词往往意味着相应图像片段中的嘴唇运动较少,使得模型对这些样本进行正确分类具有挑战性。因此,我们建议使用不同的空间大小的卷积核来提取互补的上下文信息,使前端能够获得有鉴别力的特征图。这些增强的特征有助于提高对细粒度唇部运动的建模能力,并提高对只有几个视素的单词的分类精度。

为了验证多尺度处理的有效性,我们首先将金字塔卷积(PyConv)[35]纳入前端,如图2所示。它包含一个有n个不同类型卷积核的金字塔(我们在实验中默认设置n=4,这与图中一致)。每一级的卷积核包含的空间大小从金字塔的底部到顶部不断增加(我们在实验中默认设置K1,2,3,4=3,5,7,9)。空间大小较小的卷积核可以专注于提取具有局部背景信息的特征图,而大尺寸的卷积核可以提供更多的全局背景信息。该模型可以通过学习探索不同卷积核类型的良好组合。对于ResNet-18的每一个基本块,我们用PyConv代替第二个标准卷积层。我们称这种修改为金字塔式ResNet-18(Py-ResNet-18)。
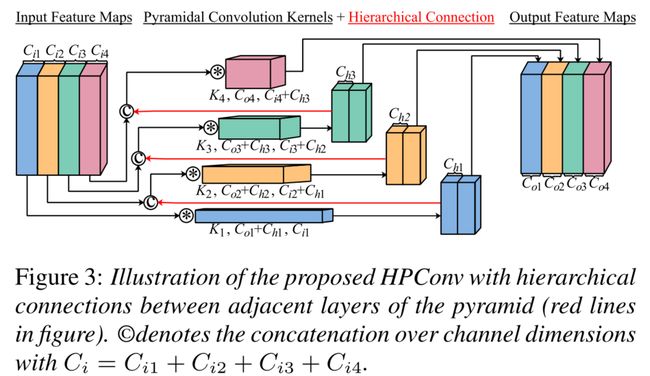
基于PyConv,我们提出分层金字塔卷积(HPConv),如图3所示。这里的创新之处在于,我们在金字塔的相邻层之间建立了一个分层连接(图3中的红线)。如上所述,PyConv中的局部和全局特征图是从输入特征图中提取的。与分层连接一样,局部特征图被用作输出的一部分,同时也作为全局特征提取的输入。这种自下而上的信息聚合可以进一步提高模型的分类性能,特别是对于只有几个视点的词。对于ResNet-18的每一个基本块,我们用HPConv替换第二个卷积层,并将这种修改称为分层金字塔式ResNet-18(HP-ResNet-18)。
2.2 基于自注意力的共识模块:

目前使用的最流行的共识方法是对所有时间步骤产生的分数进行平均,如表1中所有系统所示。给定帧级的特征图F3 ∈ R^T ×C2,序列级的最终得分向量F4 ∈ R^C3计算如下:

基于平均的共识假设每一帧对最终决定提供相等的贡献,这对于这里使用的LRW数据通常不是一个好方法。如图4所示,标注为“大约”的视频样本总共包括29个帧,但是只有在中间红色虚线框中突出显示的时间步长T = 9~19的帧与单词“大约”相关。在标注中,单个单词的准确单词边界通常很难定位。因此,我们提出了一种基于自注意力[36]的共识机制,以确保该模型更多地关注与注释单词更相关的帧,而较少关注其他不相关的帧。所提出的基于非一致自注意的共识可以表示为:
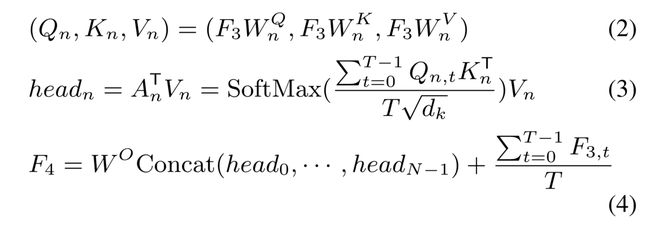

3 实验:
在本节中,我们将我们提出的框架与已经在LRW任务中获得最佳单词准确性的基线系统进行比较[32]。我们预处理每个固定长度的视频片段,并按照基线中使用的相同程序训练所有模型。读者可以参考[32]了解更多细节。为了更好地理解图1中强调的两种提出的前端和共识方法,我们还提供了对实验结果的深入分析,以说明HPConv和自注意力的贡献。
表2:不同系统单词准确率的比较。为了简单起见,前端的3D Conv被省略。Acc:单词准确性。

表2列出了所有系统的结果。与基线模型相比,我们在N3提出的HPConv比在N2提出的PyConv表现更好,我们在N1提出的自我关注比基线中的“平均”表现更好。整个系统(表示为N4)实现了86.83%的准确度,在LRW上获得了最好的性能。已知N5-N8的单词边界,我们可以看到N6、N7和N8都比N5好。
3.1 分层金字塔卷积分析:
图5:基线、N2和N3在不同类别上的准确率比较,标注词中的视位数量相同。
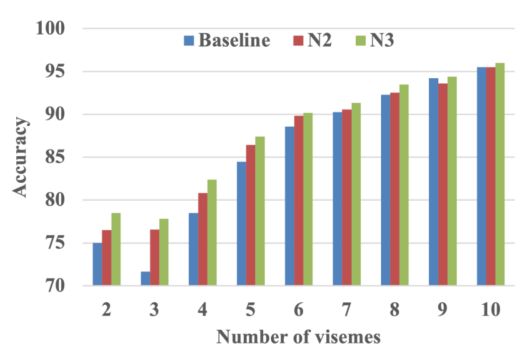
为了验证我们提出的HPConv前端的有效性,我们将只使用HPResNet-18的系统结果(表2中表示为N3)与使用Py-ResNet-18的结果(表示为N2)进行比较,两者都进行了多尺度特征提取。与使用ResNet-18的基线相比,应用多尺度卷积核比没有多尺度空间特征提取的基线提高了模型分类性能。此外,我们提出的HPConv(N3)比PyConv(N2)更能从中受益。
我们进一步分析了用不同前端特征得到的错误样本。根据注释词中的视觉数量,我们将整个测试集分为9个类别,并在图5中绘制了相应的准确率。我们可以看到,N2和N3在几乎所有的语素长度的情况下都比基线表现更好。语素数量较少的词比语素较多的词有更明显的改善。此外,我们提出的HPConv引入了从局部到全局信息的分层连接,这进一步提高了对只有几个视点的单词的分类准确率比PyConv高。
3.2 基于自注意力共识的分析:
我们提出的框架与以前的方法之间最显著的区别之一是提出了基于自我注意的共识。它确保了模型在分类过程中对相关帧给予更多的关注。因此在表2中,只使用自我注意的系统(表示为N1)的结果比基线中基于平均的共识提高了分类性能。为了进一步分析为什么我们提出的自我注意能够超过传统的基于平均数的共识,我们使用[21]提供的词边界信息对Baseline、N1、N3和N4中使用的模型进行了重新训练,得到了四个改进的系统,分别表示为N5、N6、N7和N8。这里的主要区别是只对与注释词有关的帧应用平均或基于自我注意的共识。我们可以观察到,在使用人工词界的情况下,在比较N5与N6和N7与N8时,平均和基于自我注意力的共识所获得的准确率几乎相同。据推测,学到的注意力权重就像 "软词界"。虽然不是精确的,但它们的功能与人工词界相似。
图6:基线模型在人工和学习到的单词边界之间的不同编辑距离上的分类精度。

为了验证我们的假设,我们通过手动词边界向量Bman = [0, - - , 0, 1, - - , 1, 0, - - , 0]T ∈ RT和具有平均性的词边界向量之间的编辑距离[37]将所有测试样本分类。Bavg = [1, - -, 1]T ∈ RT,以及带有自我注意的学习向量

其中u(-)是使用阈值常数α=0.01的单位阶梯函数。首先,我们在图6中绘制了基线模型的分类准确率与编辑距离的关系。我们观察到,随着学习到的和手工操作的单词边界之间的编辑距离的增加,准确性趋于下降。接下来在图7中,我们绘制了每个编辑距离对应的基线和N1系统获得的样本数。很明显,基于自我注意的共识可以更好地学习词的边界,并导致比基于平均的共识小得多的编辑距离。这两个观察结果可以很好地解释基于自注意力的共识机制的有效性。
图8显示了在图4的例子中,用建议的自注意力共识学到的权重。我们可以发现,即使每个头有不同的焦点,所有不相关的帧上的attention权重都相当小(大部分等于0),这有助于模型忽略噪声信息以获得更好的分类性能。
图7:基线和N1之间的样本数量在人工和学习的单词边界之间的不同编辑距离上的比较。
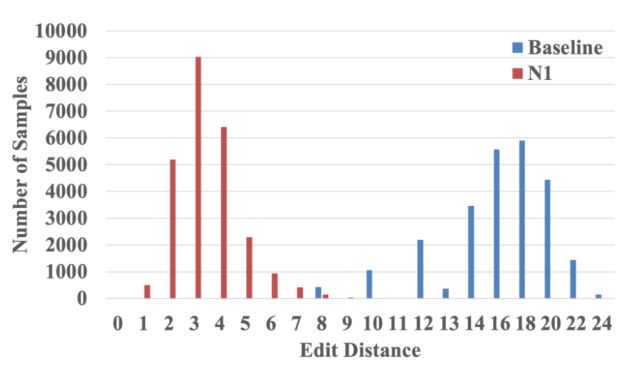
图8:在图4的例子中,用自我注意学到的每一帧的权重。不同颜色的茎叶图显示了每一帧的不同注意力头的学习权重。红色虚线表示所有权重都等于1的手动单词边界。

4 结论:
我们提出了分层金字塔卷积和基于自我注意的共识,以取代标准卷积和基于平均的共识,这在先进的唇读系统中是常用的。广泛的实验和分析经验证明,我们提出的HPConv提高了我们的模型对轻微唇部运动的利用率,而基于自注意力的共识确保了模型对相关图像帧的关注。总之,我们的系统在LRW读唇任务上达到了最佳的单词准确率。
在未来,探索更有效的网络结构以同时利用多尺度处理的空间和时间背景信息将是有趣的。而且我们还进一步研究如何提高学习到的单词边界的准确性。