变分自编码器VAE ——公式推导(含实现代码)
目录
- 一、什么是变分自编码器
- 二、VAE的公式推导
- 三、重参数化技巧
一、什么是变分自编码器
在讲述VAE(variational auto-encoder)之前,有必要先看一下AE(auto-encoder)。AE采用自监督学习的方式对高维数据进行高效的特征提取和特征表示,AE的结构中包含一个编码器(encoder)和解码器(decoder),其中encoder的作用是将我们的数据空间映射到另一个隐变量(latent variable)空间上去,具体来说,我们的一个输入数据样本将被被编码成一个vector,这个vector中的每一维度就是一些该样本的属性;而decoder要干的事则刚好与encoder相反,它可以接受一个latent vector,并且重新变回到原样本空间上去,其中编码器和解码器一般通过神经网络进行实现。

这里我们可以看到,AutoEncoder在优化过程中无需使用样本的label,本质上是把样本的输入同时作为神经网络的输入和输出,通过最小化重构误差希望学习到样本的抽象特征表示z。这种自监督的优化方式大大提升了模型的通用性。上述模型是自编码器的原始形式,容易过拟合,一般会噪声、正则化等提升模型的鲁棒性。
变分自编码器,英文名为variational auto-encoder,简称VAE,同GAN一样都属于生成模型,希望从训练数据中来建模真实的数据分布,然后反过来再用学习到的模型和分布去生成、建模新的数据。其网络结构同AE非常类似,但其编码器并不是直接输出一个隐变量,而是一个多维高斯分布的均值( u u u)和方差( δ δ δ),然后在由 u u u和 δ δ δ确定的分布中进行采样一个 z z z,送入到解码器中进行解码,目标同AE类似,即将 z z z还为原始的输入。通过上述的描述我们可以看出,VAE可以做到一个输入对应多个输出,并且希望这些输出之间尽可能类似,而AE的输入输出是一一对应的,因此值得注意的是VAE为生成模型,而AE并不是生成模型,前者可以生成新的数据,而后者不能。

二、VAE的公式推导
VAE的重点在于建模 Z Z Z服从的分布,因为知道了 Z Z Z的分布,我们就可以从其中进行采样,按照AE的套路,既可重建输入 X X X。由于隐变量 Z Z Z同输入 X X X是紧密相关的,因此我们假设:
z ∼ p ( z ∣ x ) z\sim p(z|x) z∼p(z∣x)
绝大数情况下,我们所拥有的数据是非常有限的,导致 p ( z ∣ x ) p(z|x) p(z∣x)的真实分布总是未知的,因此我们希望基于已有的数据,通过一个神经网络即编码器来近似该分布,假设为:
z ∼ q ( z ∣ x ) z\sim q(z|x) z∼q(z∣x)
通过KL离散度,我们可以衡量两个分布的差异,即最小化下式:
K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) = ∫ q ( z ∣ x ) log q ( z ∣ x ) p ( z ∣ x ) d z KL(q(z \mid x) || p(z \mid x))=\int q(z \mid x) \log \frac{q(z \mid x)}{p(z \mid x)} d z KL(q(z∣x)∣∣p(z∣x))=∫q(z∣x)logp(z∣x)q(z∣x)dz (1)
接下来对(1)式进行变换:
( 1 ) = ∫ q ( z ∣ x ) log q ( z ∣ x ) p ( x ∣ z ) p ( z ) p ( x ) d z = ∫ q ( z ∣ x ) log q ( z ∣ x ) d z + ∫ q ( z ∣ x ) log p ( x ) d z − ∫ q ( z ∣ x ) log [ p ( x ∣ z ) p ( z ) ] d z = ∫ q ( z ∣ x ) log q ( z ∣ x ) d z + log p ( x ) ∫ q ( z ∣ x ) d z − ∫ q ( z ∣ x ) log [ p ( x ∣ z ) p ( z ) ] d z (注意 ∫ q ( z ∣ x ) d z = 1 ) = log p ( x ) + ∫ q ( z ∣ x ) log q ( z ∣ x ) d z − ∫ q ( z ∣ x ) log [ p ( x ∣ z ) p ( z ) ] d z (把第二项提前) \begin{aligned} (1) &=\int q(z \mid x) \log \frac{q(z \mid x)}{\frac{p(x \mid z) p(z)}{p(x)}} dz \\ &=\int q(z \mid x) \log q(z \mid x) d z+\int q(z \mid x) \log p(x) dz-\int q(z \mid x) \log [p(x \mid z) p(z)] dz \\ &=\int q(z \mid x) \log q(z \mid x) d z+\log p(x) \int q(z \mid x) d z-\int q(z \mid x) \log [p(x \mid z) p(z)] d z \text { (注意 } \int q(z \mid x) d z=1 \text { ) }\\ &=\log p(x)+\int q(z \mid x) \log q(z \mid x) d z-\int q(z \mid x) \log [p(x \mid z) p(z)]dz \text { (把第二项提前) }\end{aligned} (1)=∫q(z∣x)logp(x)p(x∣z)p(z)q(z∣x)dz=∫q(z∣x)logq(z∣x)dz+∫q(z∣x)logp(x)dz−∫q(z∣x)log[p(x∣z)p(z)]dz=∫q(z∣x)logq(z∣x)dz+logp(x)∫q(z∣x)dz−∫q(z∣x)log[p(x∣z)p(z)]dz (注意 ∫q(z∣x)dz=1 ) =logp(x)+∫q(z∣x)logq(z∣x)dz−∫q(z∣x)log[p(x∣z)p(z)]dz (把第二项提前)
我们需要最小化(2)式,其中 l o g p ( x ) logp(x) logp(x)为一个定值,因此最小化(1)式等价于最小化(2)式的最右边两项,做个正负变换,即最大化下式:
L = ∫ q ( z ∣ x ) log [ p ( x ∣ z ) p ( z ) ] d z − ∫ q ( z ∣ x ) log q ( z ∣ x ) d z = ∫ q ( z ∣ x ) log p ( x ∣ z ) d z + ∫ q ( z ∣ x ) log p ( z ) d z − ∫ q ( z ∣ x ) log q ( z ∣ x ) d z = ∫ q ( z ∣ x ) l o g p ( x ∣ z ) d z − ∫ q ( z ∣ x ) log q ( z ∣ x ) p ( z ) d z = E z 服从 q ( z ∣ x ) [ log p ( x ∣ z ) ] − D K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ( 3 ) \begin{aligned} L &= \int q(z \mid x) \log [p(x \mid z) p(z)] d z - \int q(z \mid x) \log q(z \mid x) dz \\ &=\int q(z \mid x) \log p(x \mid z) d z + \int q(z \mid x) \log p(z)dz - \int q(z \mid x) \log q(z \mid x) d z &=\int q(z \mid x) \ logp(x \mid z)dz - \int q(z \mid x) \log \frac{q(z \mid x)}{p(z)} dz \\ &= E_{z \text { 服从 } q(z \mid x)}[\log p(x \mid z)]- D_{KL}(q(z \mid x) || p(z))\ \ \ \ \ \ \ (3) \end{aligned} L=∫q(z∣x)log[p(x∣z)p(z)]dz−∫q(z∣x)logq(z∣x)dz=∫q(z∣x)logp(x∣z)dz+∫q(z∣x)logp(z)dz−∫q(z∣x)logq(z∣x)dz=Ez 服从 q(z∣x)[logp(x∣z)]−DKL(q(z∣x)∣∣p(z)) (3)=∫q(z∣x) logp(x∣z)dz−∫q(z∣x)logp(z)q(z∣x)dz
(3)式有个特别的名字Evidence Lower BOund(ELBO)。
分析下(3)式,第一项即为不断的从样本 x x x确定的分布 Z Z Z中不断的采样一个 z z z,希望从z重建输入x的期望最大,因此 p ( x ∣ z ) p(x|z) p(x∣z)即为解码器,由于期望不好直接求,我们可以将该问题专化为求损失,对于分类问题,E为交叉熵损失,对于连续值问题,E为MSE损失。
(3)式的第二项为由 x x x生成 Z Z Z的分布(论文中假设服从高斯分布)同真实Z的分布之间的差异, p ( z ) p(z) p(z)的真实分布是未知的,论文中假设 p ( z ) p(z) p(z)服从一个标准正态分布,从神经网络的角度看,可以认为(3)式的第二项为一个正则项,对编码器进行约束,防止采样结果过于极端,导致生产的图像不真实。
接下来对(3)式的第二项进行化简,其中J为Z的维度:
∫ q θ ( z ) log p ( z ) d z = ∫ N ( z ; μ , σ 2 ) log N ( z ; 0 , I ) d z = − J 2 log ( 2 π ) − 1 2 ∑ j = 1 J ( μ j 2 + σ j 2 ) \begin{aligned} \int q_{\boldsymbol{\theta}}(\mathbf{z}) \log p(\mathbf{z}) d \mathbf{z} &=\int \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) \log \mathcal{N}(\mathbf{z} ; \mathbf{0}, \mathbf{I}) d \mathbf{z} \\ &=-\frac{J}{2} \log (2 \pi)-\frac{1}{2} \sum_{j=1}^{J}\left(\mu_{j}^{2}+\sigma_{j}^{2}\right) \end{aligned} ∫qθ(z)logp(z)dz=∫N(z;μ,σ2)logN(z;0,I)dz=−2Jlog(2π)−21j=1∑J(μj2+σj2)
且
∫ q θ ( z ) log q θ ( z ) d z = ∫ N ( z ; μ , σ 2 ) log N ( z ; μ , σ 2 ) d z = − J 2 log ( 2 π ) − 1 2 ∑ j = 1 J ( 1 + log σ j 2 ) \begin{aligned} \int q_{\boldsymbol{\theta}}(\mathbf{z}) \log q_{\boldsymbol{\theta}}(\mathbf{z}) d \mathbf{z} &=\int \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) \log \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2}\right) d \mathbf{z} \\ &=-\frac{J}{2} \log (2 \pi)-\frac{1}{2} \sum_{j=1}^{J}\left(1+\log \sigma_{j}^{2}\right) \end{aligned} ∫qθ(z)logqθ(z)dz=∫N(z;μ,σ2)logN(z;μ,σ2)dz=−2Jlog(2π)−21j=1∑J(1+logσj2)
因此有:
− D K L ( ( q ϕ ( z ) ∣ ∣ p θ ( z ) ) = ∫ q θ ( z ) ( log p θ ( z ) − log q θ ( z ) ) d z = 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ) 2 ) − ( μ j ) 2 − ( σ j ) 2 ) \begin{aligned} -D_{K L}\left(\left(q_{\boldsymbol{\phi}}(\mathbf{z}) || p_{\boldsymbol{\theta}}(\mathbf{z})\right)\right.&=\int q_{\boldsymbol{\theta}}(\mathbf{z})\left(\log p_{\boldsymbol{\theta}}(\mathbf{z})-\log q_{\boldsymbol{\theta}}(\mathbf{z})\right) d \mathbf{z} \\ &=\frac{1}{2} \sum_{j=1}^{J}\left(1+\log \left(\left(\sigma_{j}\right)^{2}\right)-\left(\mu_{j}\right)^{2}-\left(\sigma_{j}\right)^{2}\right) \end{aligned} −DKL((qϕ(z)∣∣pθ(z))=∫qθ(z)(logpθ(z)−logqθ(z))dz=21j=1∑J(1+log((σj)2)−(μj)2−(σj)2)
综上,如果将AVE用于图像生成领域,则(3)式可以具体化下如下:
L = 1 n ∑ ( x i − y i ) − 1 2 ∑ j = 1 J ( 1 + log ( ( σ j ) 2 ) − ( μ j ) 2 − ( σ j ) 2 ) L= \frac{1}{n}\sum{(x_i - y_i)} - \frac{1}{2} \sum_{j=1}^{J}\left(1+\log \left(\left(\sigma_{j}\right)^{2}\right)-\left(\mu_{j}\right)^{2}-\left(\sigma_{j}\right)^{2}\right) L=n1∑(xi−yi)−21∑j=1J(1+log((σj)2)−(μj)2−(σj)2)
三、重参数化技巧
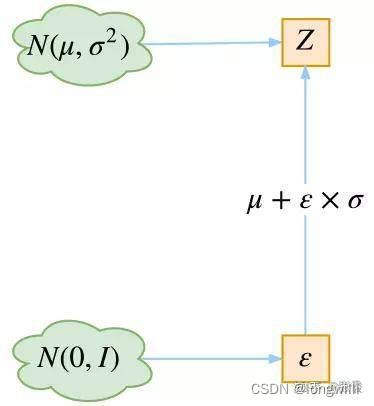
由于z是从分布中进行采样得到的,而采样过程是不可导的,而我们需要梯度的反传优化,因此,我们需要换一种思路,直接从标准正态分布中采样,利用如下的事实:
从 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2)中采样一个Z,相当于从 N ( 0 , I ) N(0, I) N(0,I)中采样一个 ϵ \epsilon ϵ,然后让 Z = μ + ϵ ∗ θ Z = \mu + \epsilon * \theta Z=μ+ϵ∗θ。
证明参考:


实现代码:
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
import utils
class VAE(nn.Module):
"""Implementation of VAE(Variational Auto-Encoder)"""
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 200)
self.fc2_mu = nn.Linear(200, 10)
self.fc2_log_std = nn.Linear(200, 10)
self.fc3 = nn.Linear(10, 200)
self.fc4 = nn.Linear(200, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
mu = self.fc2_mu(h1)
log_std = self.fc2_log_std(h1)
return mu, log_std
def decode(self, z):
h3 = F.relu(self.fc3(z))
recon = torch.sigmoid(self.fc4(h3)) # use sigmoid because the input image's pixel is between 0-1
return recon
def reparametrize(self, mu, log_std):
std = torch.exp(log_std)
eps = torch.randn_like(std) # simple from standard normal distribution
z = mu + eps * std
return z
def forward(self, x):
mu, log_std = self.encode(x)
z = self.reparametrize(mu, log_std)
recon = self.decode(z)
return recon, mu, log_std
def loss_function(self, recon, x, mu, log_std) -> torch.Tensor:
recon_loss = F.mse_loss(recon, x, reduction="sum") # use "mean" may have a bad effect on gradients
kl_loss = -0.5 * (1 + 2*log_std - mu.pow(2) - torch.exp(2*log_std))
kl_loss = torch.sum(kl_loss)
loss = recon_loss + kl_loss
return loss
VAE的训练为无监督,但现实情况是我们可以获取少量的有标签数据,因此可以利用这部分有标签数据促进网络的学习,这就导出了Conditional VAE,或者叫 CVAE,具体可以参考文献5。
类似的有GAN,Conditional GAN
Batch Normalization,或BN,Conditional BN。
--------以下搬运自变分自编码器VAE:原来是这么一回事 | 附开源代码,有助于直观理解VAE的原理。-----------------
首先我们有一批数据样本 {X1,…,Xn},其整体用X来描述,我们本想根据 {X1,…,Xn} 得到X的分布p(X),如果能得到的话,那我直接根据 p(X) 来采样,就可以得到所有可能的X了(包括 {X1,…,Xn} 以外的),但由于我们的数据总是有限的,因此很难实现。
p ( X ) = ∑ Z p ( X ∣ Z ) p ( Z ) p(X)=\sum_{Z} p(X \mid Z) p(Z) p(X)=∑Zp(X∣Z)p(Z)
这里我们就不区分求和还是求积分了,意思对了就行。此时 p(X|Z)就描述了一个由Z来生成X的模型,而我们假设Z服从标准正态分布,也就是p(Z)=N(0,I)。如果这个理想能实现,那么我们就可以先从标准正态分布中采样一个 Z,然后根据Z来算一个 X,也是一个很棒的生成模型。我们将该过程表示为下图:
 看出了什么问题了吗?如果像这个图的话,我们其实完全不清楚:究竟经过重新采样出来的 Z k Z_k Zk,是不是还对应着原来的 X k X_k Xk,所以我们如果直接最小化 D ( X ^ k , X k ) 2 D(X̂_k,X_k)^2 D(X^k,Xk)2(这里 D 代表某种距离函数)是很不科学的。
看出了什么问题了吗?如果像这个图的话,我们其实完全不清楚:究竟经过重新采样出来的 Z k Z_k Zk,是不是还对应着原来的 X k X_k Xk,所以我们如果直接最小化 D ( X ^ k , X k ) 2 D(X̂_k,X_k)^2 D(X^k,Xk)2(这里 D 代表某种距离函数)是很不科学的。
在整个 VAE 模型中,我们并没有去使用 p ( z ) p(z) p(z)(先验分布)是正态分布的假设,我们用的是假设p(Z|X)(后验分布)是正态分布。具体来说,给定一个真实样本 X k X_k Xk,我们假设存在一个专属于 X k X_k Xk的分布 p ( Z ∣ X k ) p(Z|X_k) p(Z∣Xk)(学名叫后验分布),并进一步假设这个分布是(独立的、多元的)正态分布。为什么要强调“专属”呢?因为我们后面要训练一个生成器 X=g(Z),希望能够把从分布 p ( Z ∣ X k ) p(Z|X_k) p(Z∣Xk) 采样出来的一个 Z k Z_k Zk还原为 X k X_k Xk。

参考文献:
[1]普通正态分布转换到标准正态分布
[2]https://arxiv.org/pdf/1312.6114.pdf
[3]https://github.com/dragon-wang/VAE
[4]https://www.jeremyjordan.me/variational-autoencoders/
[5]https://zhuanlan.zhihu.com/p/34998569
[6] 张俊: 变分自编码器VAE:原来是这么一回事
[7]https://www.zhihu.com/question/317623081