Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks论文分享
Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
发表会议: IEEE Symposium on Security and Privacy 2019
会议评级:CCF-A
研究背景
当时对于DNN的后门攻击已经有了一定的方法,例如BadNet等可以有效的将后门插入到DNN中,使得对于正常的输入神经网络的输出是正确的,而遇到在输入数据中包含触发器的输入则会输出实现在后门攻击中实现确定好的输出。面对这种情况,因为神经网络的缺乏透明度所以在这篇论文发表之前没有一种能够对于后门攻击进行有效遏制和清除的方法。
现状及问题
在对于神经网络的后门攻击中,尤其是对于应用于计算机视觉的神经网络的后门攻击中没有有效的识别和防御方法(主要是无法理解神经网络的行为)。很多的神经网络体积十分的庞大没有办法找到对于后门触发器“帮助”比较大的神经元。之前提出的对于后门攻击的防御措施都是基于神经元的修剪,但是效率都很低,都会降级后门触发器的同时大幅度降低神经网络正常识别的能力。
神经网络后门攻击的鼻祖badnet:

方法模型
于是作者提出了一套包含对于后门攻击触发器的检测、识别和缓解的高效方法。
首先是对于后门攻击触发器的检测和识别工作,作者通过对于带有后门的神经网络的直观理解提出了如下的方法模型:
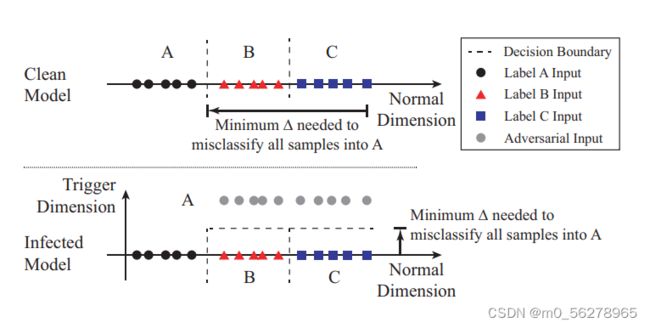
如果这个神经网络是一个存在这已经植入的后门且这个后门的作用就是将带有触发器的输入的输出变化为C,那么这种情况需要改变的变下化量一定是很小的(主要的修改就是在于触发器维度上,触发器本身很小所以在其他维度上的变化应该不大)。
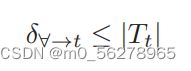
但是如果在没有后门的情况下想要将某一个输入(正确的标签是C)的输出强行改成A,那么在训练集的向量空间之中所需要改变的变化量(向量)一定是很大的。
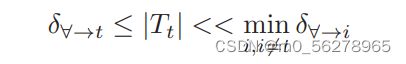
所以可以检测后门的方法就是根据这一原理产生的
对于每一个不来自于目标标签的输入计算其强行改成该输出所需要改变的变量的大小,如果有的改变值明显小于其他的输入数据那么就需要特别关注。然后对于每一个输出标签都进行一遍之前的操作。最后如果存在那种特别小的变化就能完成转变的标签就是触发器的目标标签。也就能够表示该神经网络已经被植入了后门。
识别后门:如果在视觉上触发器比较明显的话可以直接进行人工检查,但是现在很多的研究都可以把触发器做的很隐蔽,与环境融合的很好。所以就需要基于神经网络去想办法。作者提出的方案是使用反向工程技术从数据集拟合一个最优的触发器。期望通过这种方式能够完成识别后门的工作。
这里面就需要用到反向工程技术:
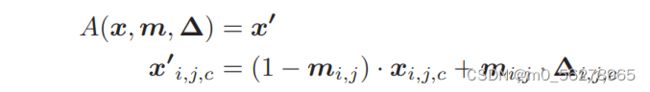
上图所示就是插入后门的模型。其中A(⋅)表示将触发应用于原始图像x的函数,∆是触发图案,它是一个像素颜色强度与输入图像的维数相同的三维矩阵(高度、宽度和颜色通道)。M是一个叫做掩码的2D矩阵,它决定触发能覆盖多少原始图像。这里,我们考虑二维掩码(高度、宽度),其中在像素的所有颜色通道上施加相同的掩码值。掩码中的值从0到1不等。这种连续的掩码形式也使得掩码具有可微性,并有助于将其集成到优化目标中。

然后就是对于后门触发器进行拟合取最优解。
f是DNN自己的预测函数,l函数则表示分类误差的损失。λ是控制m的权重的函数。较小的λ对触发器大小的控制具有较低的权重,但会有较高的成功率产生错误分类。X是我们用来解决优化任务的一组干净的图像。它来自用户可以访问的干净数据集。在实验中,我们使用训练集并将其输入到优化过程中,直到收敛为止。
为了检测异常值,作者使用了一种基于中位绝对偏差的技术。首先计算所有数据点与中位数之间的绝对偏差。这些绝对偏差的中值称为MAD,然后,将数据点的异常指数定义为数据点的绝对偏差,除以MAD。当假定基础分布为正态分布时,应用常数估计器(1.4826)对异常指数进行规范化。任何异常指数大于2的数据点都有>95%的异常值概率。我们将任何异常指数大于2的标记为孤立点和受感染的标记。
实验评估
首先使用BadNet方法对于(1)手写体数字识别(MNIST);(2)交通标志识别(GTSRB);(3)具有大量标签的人脸识别(YouTube人脸);(4)基于复杂模型的人脸识别(PubFig)进行后门的植入(可以看出研究主要集中在计算机视觉领域)。一下显示的是实验模型(数据集)的基本信息:
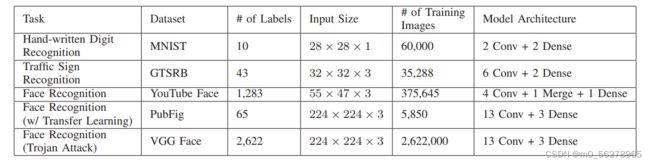
攻击这些模型的后门触发器和最后的后门植入效果如图所示:


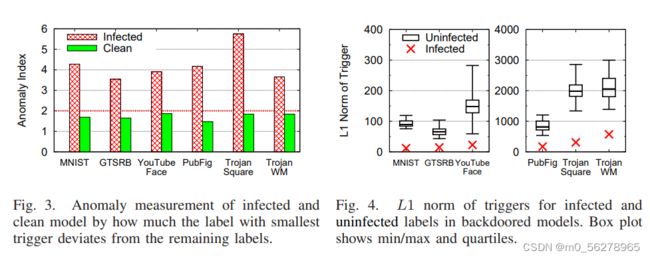
首先,先进行检测后门的相关操作,计算出每一个被植入了后门的模型之前的干净模型的异常值(根据之前的检测后门的算法给出),以及它们的L1范数。可以看出干净模型的异常值普遍是要小于被植入了后门的模型,在之前作者将异常值大于2的模型作为被检测出后门的模型在这里看也是符合预期的(虽然我觉得选择2作为阈值有一点小,但是这种筛选本着宁可多不可少的原则选择2作为阈值也算是合理)。还有就是由后门产生的转换的L1范数也是要比正常转换要小非常多。
然后就是利用反向工程得出最优触发器,来达到识别后门功能。具体就是根据上文所提到的方法选取一些干净的数据作为数据集对于模型进行训练。结果如下:



可以发现前面3个模型生成出来的触发器和原本的触发器之间还是比较相似的,但是后三个尤其是后两个模型的触发器就不太能够匹配。这代表着反向工程在同样的数据域中找到了一个和最初的触发器功能相同但是大小更优的触发器。但是在功能上是相似的,主要被激活的神经元也是相似的。
还有就是缓解后门了,作者提出了两种方法:阻止带有触发器的数据输入还有就是对DNN进行修改以彻底根除后门。作者建立了基于神经元激活轮廓的反向触发滤波器。这个滤波器是由在神经网络中神经元激活值位于前1%的神经元组成的。在给定某些输入时,过滤器将潜在的对抗性输入识别为具有高于某一阈值的激活轮廓的输入。激活阈值可以使用干净输入(已知没有触发器的输入)的测试来校准。
还有一种思路就是对于被感染的神经网络进行修补。第一种方法就是直接将触发器相关神经元激活值较高的神经元直接切除掉(前10%到30%)。这种方法可以有效的抑制后门但是也会对于神经网络的正常功能产生比较大的影响。经过作者的研究,对于卷积神经网络,在最后一个卷积层进行修建会产生最后的效果(对正常的输入影响最小)。当然这种方法只能在原始的触发器和我们利用反向工程推出来的最优触发器大致相同的形况下使用(因为我们是利用拟合的触发器统计神经元激活值)。如果两者相差很多,那么这种方法的效果一定是比较不理想的。
第二种方法是unlearning。就是构建带有和触发器功能相反的反向触发器的数据来对被感染的模型进行输入。这个方法对于所有的模型都适用,但是需要更长的时间。
个人想法
这篇文章对于触发器的检测工作的思路非常的新颖且有效,但是最大的问题还是通过反向工程构建的触发器有可能和原触发器的结构完全不同。如果使用神经元切除来进行防御的话成功率不能保证,而如果要使用比较稳妥的unlearning方法的话就需要更大的时间代价。现在还没有既能够保证成功率又能够是时间代价较小的对于后门攻击的防御机制。
对于一个DNN中包含多个功能相同或者不同的触发器的复杂情况,这种方法的效率和效果就无法保证。
对于触发器较大导致对于的L1范数较大的情况下后门检测的成功率会下降。