task9
Attention原理:
基本思想:打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。通俗解释就是将encoder的么一个隐藏状态设定一个权重,根据权重的不同决定decoder输出更侧重于哪一个编码状态。
实现方法:通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。
模型图:

attention其实就是一个当前的输入与输出的匹配度。在上图中,即为h1和z0的匹配度( h1为当前时刻RNN的隐层输出向量,而不是原始输入的词向量,z0初始化向量,如rnn中的initial memory,图片中的这一部分是encode的部分 ),其中的match为计算这两个向量的匹配度的模块,出来的α10即为由match算出来的相似度。好了,基本上这个就是attention-based model 的attention部分了。那么,match什么呢? 对于“match”, 理论上任何可以计算两个向量的相似度都可以,比如:余弦相似度。
HAN原理:

该结构有五个模块:
1、词序列编码器
2、基于词级的注意力层
3、句子编码器
4、基于句子级的注意力层
5、分类
整个结构由双向GRU网络和注意力机制组合而成,结构公式如下:
a、词序列编码器
给定一个句子中的单词w it ,其中 i 表示第 i 个句子,t 表示第 t 个词。通过一个词嵌入矩阵 We,将单词转换成向量表示,具体如下所示:

利用双向GRU实现的整个编码流程
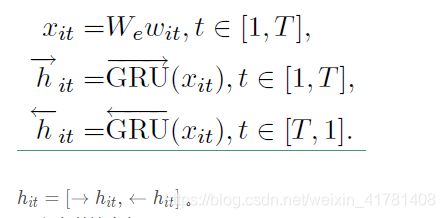
b、词级的注意力层
但是对于一句话中的单词,并不是每一个单词对分类任务都是有用的。公式如下:

其中uit 是 hit 的隐层表示,ait是经 softmax 函数处理后的归一化权重系数,uw是一个随机初始化的向量,之后会作为模型的参数一起被训练,si 就是我们得到的第 i 个句子的向量表示。
c、句子编码器
也是基于双向GRU实现编码的,公式如下: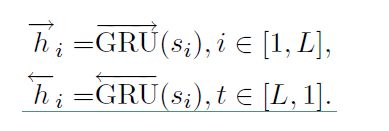
公式和词编码类似,最后的 hi 也是通过拼接得到的。
d、句子级注意力层
注意力层的公式如下:

最后得到的向量 v 就是文档的向量表示,这是文档的高层表示。接下来就可以用可以用这个向量表示作为文档的特征。
分类
使用最常用的softmax分类器对整个文本进行分类了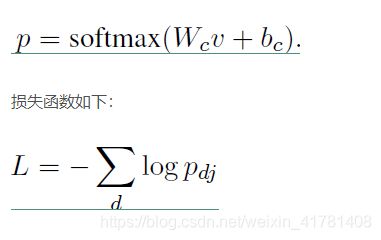
文本分类代码:
class Attention(nn.Module):
def __init__(self, feature_dim, step_dim, bias=True, **kwargs):
super(Attention, self).__init__(**kwargs)
self.supports_masking = True
self.bias = bias
self.feature_dim = feature_dim
self.step_dim = step_dim
self.features_dim = 0
weight = torch.zeros(feature_dim, 1)
nn.init.xavier_uniform_(weight)
self.weight = nn.Parameter(weight)
if bias:
self.b = nn.Parameter(torch.zeros(step_dim))
def forward(self, x, mask=None):
feature_dim = self.feature_dim
step_dim = self.step_dim
eij = torch.mm(
x.contiguous().view(-1, feature_dim),
self.weight
).view(-1, step_dim)
if self.bias:
eij = eij + self.b
eij = torch.tanh(eij)
a = torch.exp(eij)
if mask is not None:
a = a * mask
a = a / torch.sum(a, 1, keepdim=True) + 1e-10
weighted_input = x * torch.unsqueeze(a, -1)
return torch.sum(weighted_input, 1)
class GRU_Attention(nn.Module):
def __init__(self,word_embeddings,hidden_size = 40):
super(GRU_Attention, self).__init__()
self.embed_size = 200
self.hidden_size = hidden_size
self.maxlen = 400
self.label_num =10
self.embeddings = nn.Embedding(len(word_embeddings),self.embed_size)
self.embeddings.weight.data.copy_(torch.from_numpy(word_embeddings))
self.embeddings.weight.requires_grad = False
self.embedding_dropout = nn.Dropout2d(0.1)
self.gru = nn.GRU(self.embed_size, self.hidden_size, bidirectional=True, batch_first=True)
self.gru_attention = Attention(self.hidden_size * 2, self.maxlen)
self.linear1 = nn.Linear(self.hidden_size * 4, self.hidden_size // 2)
self.linear2 = nn.Linear(self.hidden_size // 2, self.label_num)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.1)
def forward(self, input):
h_embedding = self.embeddings(input)
# h_embedding = torch.squeeze(
# self.embedding_dropout(torch.unsqueeze(h_embedding, 0)))
h_gru, hh_gru = self.gru(h_embedding)
h_gru_atten = self.gru_attention(h_gru)
# global max pooling
gru_max_pool, _ = torch.max(h_gru, 1)
conc = torch.cat((h_gru_atten, gru_max_pool), 1)
conc = self.relu(self.linear1(conc))
conc = self.dropout(conc)
out = self.linear2(conc)
return out