【机器学习算法】逻辑回归为什么叫逻辑回归
文章目录
- 逻辑回归以及为什么叫逻辑回归
-
- 从sigmoid函数引出
- 逻辑回归的统计学模型:伯努利分布
- 线性回归模型的通式:广义线性模型
-
- 指数族分布
逻辑回归以及为什么叫逻辑回归
逻辑回归虽然名字里有回归(logistic regression),实则它是个二分类算法。
从sigmoid函数引出
同多元线性回归一样,逻辑回归也具有它的函数表达式:
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_{\theta}(x)=g\left(\theta^{T} x\right)=\frac{1}{1+e^{-\theta^{T} x}} hθ(x)=g(θTx)=1+e−θTx1
仔细观察这个表达式,会发现里面其实有我们见过的形式,右下角那个θᵀx不就是多元线性回归嘛。是的,没错,所以逻辑回归实则就是在多元线性回归的基础上,多嵌套了一个函数。我也不卖关子了,这个函数就是sigmoid函数,也被称作S型曲线:
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
x = np.linspace(-5,5,100)
sigmoid = 1/(1+np.exp(-x))
plt.plot(x,sigmoid)
plt.show()
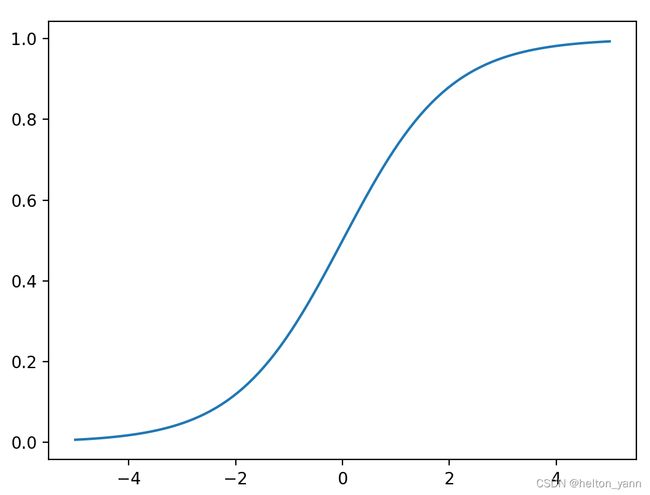
可以看到sigmoid函数的值域为(0,1)。因此逻辑回归就是在多元线性回归基础上把结果缩放到 0 到 1 之间。 我们可以简单的先通过这个函数自我脑补一下逻辑回归为什么是一个分类算法:通过线性函数得到一个结果,这个结果越小于0,函数输出就越接近0,结果越大于0,函数输出就越接近1,而分类算法的输出一般情况下都会是input属于某个类别的概率大小,因此0到1之间的范围可以表示概率。中间的0.5则将结果划分为两个类别。所以我们可以简单的将sigmoid函数理解成是一个将输出转化为属于某个类别的概率的函数。
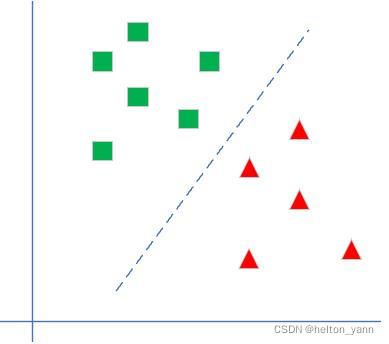
所以逻辑回归的大体思想就是,多元线性回归算法回归出一个分类超平面,预测样本通过代入这个超平面,如果是负的就说明在超平面下方,如果是正就说明是超平面上方。再通过sigmoid转化为概率,最后通过概率输出类别:
那为什么是sigmoid,为什么sigmoid的输出就一定能表示概率,别的函数不行吗?
当然,任何算法一经给出,我们都需要知其然且知其所以然,即使不能窥其所有也要至少心里有个底。
逻辑回归的统计学模型:伯努利分布
我们知道,对于二分类算法,样本只有两个标签,要么是0要么是1,并且二分类有一个特点,那就是我们最终预测样本的概率,正例加上负例的概率总和为1。即每一次预测我们都可以这么表示:
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p , 0 < p < 1 \operatorname{P}(X=1)=p, \operatorname{P}(X=0)=1-p, 0
这个公式看着是不是有点眼熟,这不就是伯努利分布(0-1分布)嘛!
对,因此,对于模型每一次预测的输出,我们都可以写成伯努利分布的形式:
f ( x ∣ p ) = { p x q 1 − x , x = 0 , 1 0 , x ≠ 0 , 1 f(x \mid p)= \begin{cases}p^{x} q^{1-x}, & x=0,1 \\ 0, & x \neq 0,1\end{cases} f(x∣p)={pxq1−x,0,x=0,1x=0,1
伯努利分布有一个很典型的例子,就是抛硬币,只不过在抛硬币当中我们已经假设概率是对半分,但在逻辑回归中,概率是需要通过每一次模型预测给出的。
其实上面这一步,我们实则是为了给出P(y|x,p)服从伯努利分布的结论,这一结论实则是为了引出一个更强大的数学武器(接下来看不懂也无妨,我也只能在我理解的基础上尽量解释清楚。毕竟只是为了更好的知道sigmoid函数是怎么来的,觉得没太大意义的可以略过)
【这里再解释下,上述条件概率中的y就是模型预测的y,x就是输入x,y是x的函数,条件概率P的意思就是:在给定参数p(p也是待估计参数)以及输入的x的前提下,y发生的概率。而这里的结论是逻辑回归的二分类任务的输出是服从伯努利分布的】
线性回归模型的通式:广义线性模型
首先通俗解释下什么是广义线性模型,比如说家喻户晓的多元线性回归,它的形式是y = wTx+b,更一般的,考虑到某可微函数g(.),令:
g ( y ) = w T x + b g(y)=w^Tx+b g(y)=wTx+b
即
y = g − 1 ( w T x + b ) y = g^{-1}(w^Tx+b) y=g−1(wTx+b)
对于逻辑回归而言,其g(.)满足:
g ( y ) = l n ( y 1 − y ) g(y) = ln(\frac{y}{1-y}) g(y)=ln(1−yy)
现在,考虑一个分类或回归问题,我们就是想预测某个随机变量 y,y 是某些特征 x 的函数。广义线性模式遵循如下三个假设:
1.p(y|x;θ)服从指数族分布,θ就是模型中待学习的变量
2.我们的目的是为了预测T(y)在条件x下的期望,并且一般情况下T(y)=y,即y_hat=E(y|x)
3.参数η和输入x是线性相关的,即η=θᵀx
指数族分布
这里首先解释下什么是指数族分布,指数族分布有:高斯分布、二项分布、伯努利分布、多项分布、泊松分布、指数分布、beta 分布、拉普拉斯分布、gamma 分布。
对于回归来说,如果因变量 y 服从某个指数族分布,那么我们就可以用广义线性回归来建模。比如说如果 y 是服从伯努利分布,我们可以使用逻辑回归(也是一种广义线性模型),或者如果y服从高斯分布,那可以用线性回归。
这里直接给出指数族分布的通用形式:
p ( y ; η ) = b ( y ) exp ( η T T ( y ) − a ( η ) ) p(y ; \eta)=b(y) \exp \left(\eta^{T} T(y)-a(\eta)\right) p(y;η)=b(y)exp(ηTT(y)−a(η))
η 是 自然参数(natural parameter)。
T(y) 是充分统计量 (sufficient statistic) ,一般情况下就是 y。
b(·)和a(·)都是函数。a(η) 是 对数部分函数(log partition function),这部分确保 Y 的分布 p(y:η) 计算的结 果加起来(连续函数是积分)等于 1。
我们上面其实已经给出了结论,那就是伯努利分布就是指数族分布的一种,不过这里再证明下也无妨:
伯努利分布(φ就是概率):
p ( y ; ϕ ) = ϕ y ( 1 − ϕ ) 1 − y p(y ; \phi)=\phi^{y}(1-\phi)^{1-y} p(y;ϕ)=ϕy(1−ϕ)1−y
可以把上式右边改写成指数分布族的形式(以e为底):
p ( y ; ϕ ) = exp ( y ln ϕ + ( 1 − y ) ln ( 1 − ϕ ) ) = exp ( ( ln ( ϕ 1 − ϕ ) ) y + ln ( 1 − ϕ ) ) \begin{aligned} &p(y ; \phi)=\exp (y \ln \phi+(1-y) \ln (1-\phi)) \\ &=\exp \left(\left(\ln \left(\frac{\phi}{1-\phi}\right)\right) y+\ln (1-\phi)\right) \end{aligned} p(y;ϕ)=exp(ylnϕ+(1−y)ln(1−ϕ))=exp((ln(1−ϕϕ))y+ln(1−ϕ))
这里我们就可以一一对照一下,
b ( y ) = 1 η T = ln ( p 1 − p ) = θ T x T ( y ) = y a ( η ) = − ln ( 1 − ϕ ) \begin{aligned} & b(y)=1 \\ &\eta^T=\ln \left(\frac{p}{1-p}\right)=\theta^{T} x\\ &T(y)=y\\ &a(\eta)=-\ln (1-\phi) \end{aligned} b(y)=1ηT=ln(1−pp)=θTxT(y)=ya(η)=−ln(1−ϕ)
这里η是个数值,所以转不转置都没关系。
由此可知:
η T = θ T x = ln ( p 1 − p ) e θ T x = p 1 − p p = e θ T x − e θ T x ⋅ p = e θ T x 1 + e θ T x = 1 1 + e − θ T x \begin{aligned} &\eta^T=\theta^{T} x=\ln \left(\frac{p}{1-p}\right)\\ &e^{\theta^{T} x} =\frac{p}{1-p} \\ &p =e^{\theta^{T} x}-e^{\theta^{T} x} \cdot p \\ &=\frac{e^{\theta^{T} x}}{1+e^{\theta^{T} x}} \\ &=\frac{1}{1+e^{-\theta^{T} x}} \end{aligned} ηT=θTx=ln(1−pp)eθTx=1−ppp=eθTx−eθTx⋅p=1+eθTxeθTx=1+e−θTx1
啊哈,最下面那个形式不就是sigmoid吗,顺便一提,这里的ln[p/(1-p)]在数学上还有个名字,叫做对数几率。然后我又顺带一查,惊喜的发现,原来对数几率回归的英文名就是logistic regression!
这下子,虽然对上面的推导过程还有些一知半解,但是至少明白了逻辑回归中的回归到底在回归些什么。
我们知道,多元线性回归的表达式是在拟合那条直线。其实逻辑回归就是用着多元线性回归的表达式,在拟合对数几率,只不过这个拟合的过程只是作为一个中间步骤,最后拟合出的对数几率又通过sigmoid函数转化为二分类的概率,所以本质上逻辑回归还是一个披着分类的大衣的回归算法。
既然都提到了广义线性回归,那我们这里再提一下多元线性回归也无妨,毕竟多元线性回归是假设样本的误差服从高斯分布,高斯分布也是指数族分布的一种。
因为多元线性回归假设样本同方差,所以我们假设方差为1不影响:
p ( y ; μ ) = 1 2 π exp ( − 1 2 ( y − μ ) 2 ) p(y ; \mu)=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{1}{2}(y-\mu)^{2}\right) p(y;μ)=2π1exp(−21(y−μ)2)
写成指数族分布的形式就是;
= 1 2 π exp ( − 1 2 y 2 ) ⋅ exp ( μ y − 1 2 μ 2 ) =\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{1}{2} y^{2}\right) \cdot \exp \left(\mu y-\frac{1}{2} \mu^{2}\right) =2π1exp(−21y2)⋅exp(μy−21μ2)
由广义线性模型的假设,我们是为了预测y在条件x下的期望,这里期望其实就是μ。并且μ=η=θᵀx
所以y_hat=θᵀx。这也就是多元线性回归的表达式。