论文学习:《Objects as Points》
被大佬安利了这篇论文,花了整整一天的时间学习这篇论文,感觉非常妙。记录一下学习笔记,先推荐两篇个人觉得讲的非常好的文章,以下笔记有些内容摘自这里:
[1] https://zhuanlan.zhihu.com/p/66048276
[2] http://www.tensorinfinity.com/paper_189.html
[3] https://blog.csdn.net/c20081052/article/details/89358658
论文地址:https://arxiv.org/pdf/1904.07850.pdf
算法源码:https://github.com/xingyizhou/CenterNet
注:关于CenterNet网络有不同方法的两篇论文,只是撞了名字,另一篇叫《CenterNet:Keypoint Triplets for Object Detection》,这次学习的是《Objects as Points》中的CenterNet
1. CenterNet网络的核心思想与主要贡献
1.1 背景
和CornerNet的问政一样,文章第一段一上来就提到了One-Stage detector和Two-Stage detector的问题:没有拜托Anchor box和NMS等方法的问题,为了区分和训练anchor box的后处理存在一定难度(并且影响了定位精度)。这一部分在CornerNet的文章《CornerNet:Detecting Objects as Paired Keypoints》里详细介绍过,不再赘述,详见笔记:https://blog.csdn.net/weixin_42214565/article/details/100524611
文章第一段分析时提出了一种"端到端可训练"的概念,即对目标框的后处理参数也加入网络训练,这一点是One-Stage detector等方法没有做到的。
基于这么一个大问题,作者提出了CenterNet构架。
1.2 核心思想
摈弃了anchor box的概念和它的修正方法,将bounding box用特征中心点和宽高尺寸表示,把目标检测问题定义为一个标准关键点(中心点)的估计问题,借鉴了CornerNet的结构思路,用全卷积层(沙漏网络)预测heatmap,heatmap中包含中心点和宽高信息。整体的框架和损失函数一定程度上借鉴了CornerNet,并在其基础上做了一定改进。
1.3 主要贡献
CenterNet创新之处在于:
1. 用heatmap预测的目标中心点代替anchor预测目标,使用更大分辨率的输出特征图(缩放了4倍),因此无需用到多重特征图Anchor,整个框架真正做到了Anchor Free,实现了“端到端可训练”
2. 网络非常易于拓展,文中主要体现在了实现3D目标检测任务和人体姿态估计(关键点回归)的任务:
· 对于3D BBox检测,直接回归得到目标的深度信息,3D框的尺寸,目标朝向;
· 对于人姿态估计,将关节点关键点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值。
2. 网络设计
顺着文章结构理思路太麻烦了,还是直接顺着网络设计整理把。
2.1 网络框架
文章在附录中给出了CenterNet的结构图

CenterNet输入512*512的RGB图像,预测带有目标框的识别图像。网络预测2个预测的中心点坐标、2个中心点的偏置,80个分类。
整个网络依次由两组hourglass network(hourglass network-104)(a)、一组带有transpose convolutions 的ResNet-18(b)、一组经典 DLA-34 结构(c)和一组改进的 DLA-34结构组成,另外作者还从底层添加更多的直连结构(skip connection),并将上采样阶段的每个卷积改编为形变卷积层(deformable convolutional layer)。
特征主要由hourglass network来提取,后面三层构造输出预测值。
2.2 特征提取原理
这一部分CenterNet一定程度上借鉴了CornerNet的设计思路。
首先算法需要计算特征的中心点,并进行下采样,下采样因子R=4。
然后在下采样的特征图中将真实的中心点以2D高斯模型表示:

再次贴上对这部分讲解的链接:https://blog.csdn.net/baobei0112/article/details/94392343
以上步骤和CornerNet都是差不多的,不同的是,CornerNet检测的是边框的Top-left corner和Bottom-right corner,而CenterNet检测的是图像中心点。这里文章特地和one-stage系列方法比较了一下,强调了这一部分的特征提取更快。主要原因是每个目标仅生成一个中心,且不需要后续处理,而anchor则是生成了很多个,并进行NMS,拖慢了运行速度。
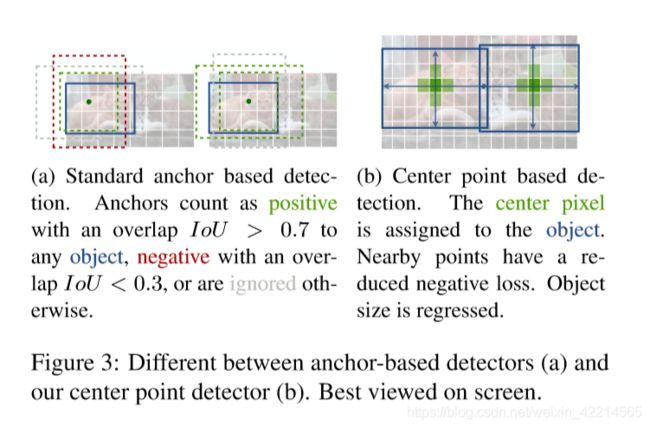
2.3 损失函数
类似于CornerNet,CenterNet的损失函数定义为三部分:中心回归损失L_k、目标尺寸损失L_size和中心点下采样偏置L_off。

2.3.1 中心回归损失L_k
定义如下:
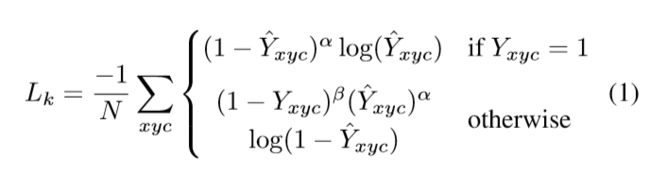
其中:1/N对损失进行了归一化,Y_xyc就是中心点,上面带一个^就是模型对它的预测。(x, y)是当前像素的坐标,c是分类通道。这一部分的损失分为两种情况:当前坐标(x, y)是c类目标的中点和当前坐标(x, y)不是c类目标的中点。
对于损失L_k的解释文章[1]解释的非常形象,这里直接引用一下:
和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值,当 Y_xyc=1 的时候, (1- ^Y_xyc)^α就充当了矫正的作用,假如 接近1的话,说明这个是一个比较容易检测出来的点,那么 ^Y_xyc就相应比较低了。而当 ^Y_xyc 接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此(1- ^Y_xyc)^α就会很大,α是超参数,这里取2。
再说下另一种情况,当otherwize的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到 (^Y_xyc)^α。因为当otherwise的时候,(^Y_xyc)^α的预测值理应是0,如果不为0的且越来越接近1的话,(^Y_xyc)^α的值就会变大从而使这个损失的训练比重也加大;而(1-Y_xyc)^β则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为Y_xyc在上文中已经提到,是一个高斯核生成的中心点,在中心点Y_xyc=1但是在中心点周围扩散Y_xyc会由1慢慢变小但是并不是直接为0,类似于上图,因此(1-Y_xyc)^β,与中心点距离越近,Y_xyc越接近1,这个值越小,相反则越大。那么(1-Y_xyc)^β和(^Y_xyc)^α是怎么协同工作的呢?
简单分为几种情况:
1. 对于距离实际中心点近的点,Y_xyc值接近1,例如Y_xyc=0.9,但是预测出来的这个点的值^Y_xyc比较接近1,这显然是不对的,他应该检测为0,因此用(^Y_xyc)^α惩罚一下,使其LOSS比重加大;但是因为这个检测到的点距离实际的中心很近了,检测到的^Y_xyc接近1也情有可原,那么我们再同情一下,用(1-Y_xyc)^β来安慰一下,使其LOSS比重减少一些。
2. 对于距离实际中心点远的点,Y_xyc的值接近0,例如Y_xyc=0.1,如果预测出来这个点的值^Yxyc(这里原文估计是笔误写的Y_xyc=0.1,此处纠正)比较接近1肯定不对,需要用(^Y_xyc)^α惩罚(原理同上)。如果预测出来的接近0,那么差不多了,拿(^Y_xyc)^α安慰一下,使其损失比重小一点;至于(1-Y_xyc)^β的话,因为此时预测距离中心点较远,所以这一项使距离中心点越远的点损失比重越大,而越近的点损失比重则越小,这相当于弱化了实际中心点周围其他负样本的损失比重,相当于处理正负样本的不平衡了。
3. 如果结合上面两种情况,那就是:(1-^Y_xyc)^α和(^Y_xyc)^α来限制easy example导致的gradient被easy example dominant的问题,而(1-Y_xyc)^β则用来处理正负样本的不平衡问题:因为没一个物体只有一个世纪中心点,而其余的都是负样本,因此负样本相较于一个中心点显得有很多。
2.3.2 目标损失 L_size
定义如下:
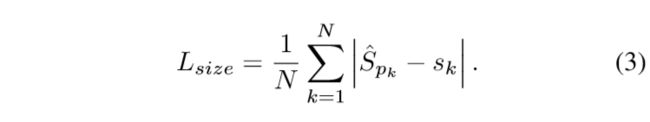
假设 是对象k的bounding box左上角角点和右下角角点的坐标,那么中心点P_k可表示为
是对象k的bounding box左上角角点和右下角角点的坐标,那么中心点P_k可表示为
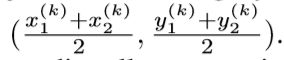
由此可以定义目标k的尺寸:
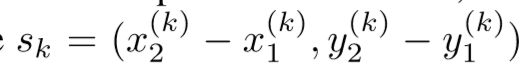
相对应的,网络还会预测出一个尺寸^S_k,基于以上定义,就可以定义出上述L_size的定义式了。这一部分很好理解,需要注意的是,Sk和^S_k应当是属于统一尺度的,文章中采用的是下采样后的尺度,![]() ,S_k同理。
,S_k同理。
2.3.3 中心点下采样偏置L_off
这一部分的原理和CornerNet的Offset是一样的,直接给出定义:

其中,![]() 代表预测的下采样偏置。
代表预测的下采样偏置。
3. 网络的拓展
关于CenterNet的拓展应用,文章介绍了单目3D目标识别和人体姿态识别的关键点检测两部分,由于项目需要以及学习时间有限,略过3D拓展的部分,以后有需要再做学习。
对于人体姿态识别的关键点,COCO数据集的每个人由k=17个关键点,CenterNet直接通过中心点预测出k个关键点的offset,这个过程类似于前文中中心点的检测。之后再预测heatmap做match,直接回归关键点没有heatmap准。具体方法如下:
首先定义中心点的姿态有k*2个维度,然后将每个关键点(关节点对应的点)参数化为相对于中心点的偏移。直接回归出关节点的偏移(像素单位)^J,损失函数采用L1 LOSS;通过给loss添加mask方式来无视那些不可见的关键点(关节点)。此处参照了slow-RCNN。
为了优化关键点(关节点),进一步估计k 个人体关节点热力图 ,使用的是标准的bottom-up 多人体姿态估计,网络训练人的关节点热力图使用focal loss和像素偏移量,这块的思路和中心点的训练雷同。我们找到热力图上训练得到的最近的初始预测值,然后将中心偏移作为一个grouping的线索,来为每个关键点(关节点)分配其最近的人。具体来说,令(^x, ^y)为检测到的中心点,回归得到的关节点为:
,使用的是标准的bottom-up 多人体姿态估计,网络训练人的关节点热力图使用focal loss和像素偏移量,这块的思路和中心点的训练雷同。我们找到热力图上训练得到的最近的初始预测值,然后将中心偏移作为一个grouping的线索,来为每个关键点(关节点)分配其最近的人。具体来说,令(^x, ^y)为检测到的中心点,回归得到的关节点为:
网络我们提取到的所有关键点:

其中关键点l_j是类似中心点检测用Heatmap回归得到的,所有关键点再Heatmap中的置信度都要大于0.1。然后将每个通过上述偏移回归的位置 l_j与最近的检测关键点(关节点)进行分配:
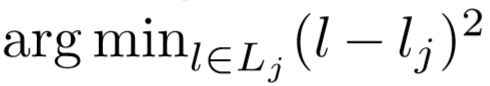
只对检测到的目标框中的关节点进行关联。
4. 算法效果和对比
目标检测效果:

拓展效果:

算法速度-准确度对比图:

更多的训练细节等以后实验结合代码再做学习(挖了个大坑)
5. 个人感想
终于找到了一个又快又准确还能结合关键点的算法了!泪流满面!
但是有一个重要的地方感觉还是没有搞太明白,就是CornerNet是利用Corner Pooling层实现联系目标特征和bounding box形状尺寸的,然后再在后续的三个输出层进行输出和计算损失,那么CenterNet具体是如何用网络进行实现的呢?用的是那部分网络,具体进行了一个怎样的卷积操作?关于理论部分在From points to bounding boxes里面提到了,但是我还是有点一知半解的感觉,等后续对源码进行了仔细地解读之后也许能够理解得透彻一点吧(继续挖坑...