单目图像3D检测内容说明
文章目录
-
-
- 数据部分
-
- label部分
- calib部分
- yolo3D
- Deep3Dbox
-
- 解决什么问题
- 本文创新点
- 核心思想
- 目标
- MultiBin loss
- 3D到2D影射的要求
- 训练和损失
- 姿态估计(求解T矩阵)
- 推导过程
- 上面整个转换过程的代码
- centernet 3D检测部分
-
数据部分
label部分
参考链接
一般都是使用kitti来作为数据训练和测试

16个数代表的含义:
第1个字符串:代表物体类别
‘Car’, ‘Van’, ‘Truck’,‘Pedestrian’, ‘Person_sitting’, ‘Cyclist’,‘Tram’, ‘Misc’ or ‘DontCare’
注意,’DontCare’ 标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略’DontCare’ 区域的预测结果。
第2个数:代表物体是否被截断
从0(非截断)到1(截断)浮动,其中truncated指离开图像边界的对象
第3个数:代表物体是否被遮挡
整数0,1,2,3表示被遮挡的程度
0:完全可见 1:小部分遮挡 2:大部分遮挡 3:完全遮挡(unknown)
第4个数:alpha,物体的观察角度,范围:-pi~pi
是在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角
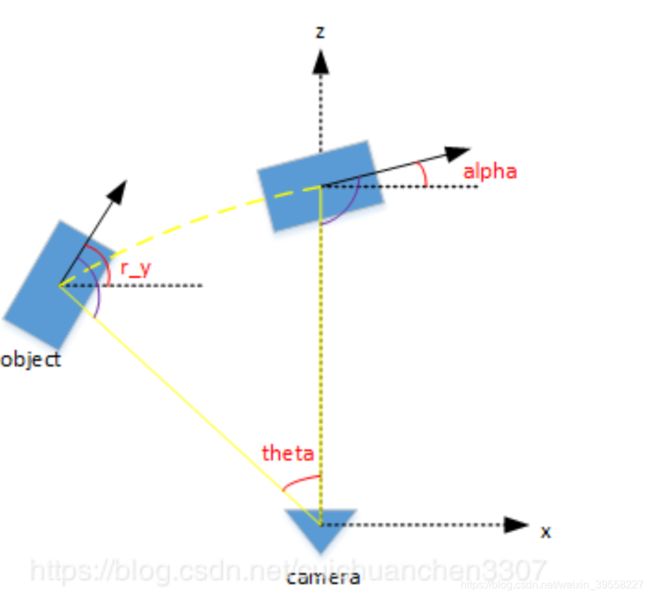
这里用的坐标系和kitti标准一致,如下图所示


r_y + pi/2 -theta = alpha +pi/2(即图中紫色的角是相等的)
所以alpha = r_y - theta

第5~8这4个数:物体的2维边界框
xmin,ymin,xmax,ymax
第9~11这3个数:3维物体的尺寸
高、宽、长(单位:米)
第12~14这3个数:3维物体的位置
x,y,z(在照相机坐标系下,单位:米)
第15个数:3维物体的空间方向:rotation_y
在照相机坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角),范围:-pi~pi
第16个数:检测的置信度
注意:各类3D算法中,朝向用kitti数据集label格式里的第4个参数来表示,即alpha,不要用最后的角度参数r_y(关于这些角度的定义,大家自行查一下吧)。因为alpha与观察者的视角有关,而r_y木有,下图中车的r_y基本是相同的,但随着观察者的相对位置变化,alpha是变的
theta角度的求解方法:theta就是那个车框中心距离图像中轴线的角度,用相机视场角乘以那个比例就行,那个比例就是框中心距离中轴线的距离占图宽的比例
请注意,KITTI只提供偏航角,而其他两个角度假定接近零。
calib部分
kitti数据集,calib解析

要将Velodyne坐标中的点x投影到左侧的彩色图像中y:
使用公式:y = P2 * R0_rect *Tr_velo_to_cam * x
将Velodyne坐标中的点投影到右侧的彩色图像中:
使用公式:y = P3 * R0_rect *Tr_velo_to_cam * x
Tr_velo_to_cam * x :是将Velodyne坐标中的点x投影到编号为0的相机(参考相机)坐标系中
R0_rect *Tr_velo_to_cam * x :是将Velodyne坐标中的点x投影到编号为2的相机(参考相机)坐标系中
P2 * R0_rect *Tr_velo_to_cam * x :是将Velodyne坐标中的点x投影到编号为2的相机(参考相机)坐标系中,再投影到编号为2的相机(左彩色相机)的照片上
注意:所有矩阵都存储在主行中,即第一个值对应于第一行。 R0_rect包含一个3x3矩阵,需要将其扩展为4x4矩阵,方法是在右下角添加1,在其他位置添加0。 Tr_xxx是一个3x4矩阵(R | t),需要以相同的方式扩展到4x4矩阵!
通过使用校准文件夹中的3x4投影矩阵,可以将相机坐标系中的坐标投影到图像中,对于提供图像的左侧彩色相机,必须使用P2。rotation_y和alpha之间的区别在于rotation_y直接在相机坐标中给出,而alpha也会考虑从相机中心到物体中心的矢量,以计算物体相对于相机的相对方向。 例如,沿着摄像机坐标系的X轴面向的汽车,无论它位于X / Z平面(鸟瞰图)中的哪个位置,它的rotation_y都为 0,而只有当此车位于相机的Z轴上时α才为零,当此车从Z轴移开时,观察角度α将会改变。
yolo3D
参考链接
物体检测包括 2D 框 (以像素为单位),3D 真实物体尺寸 (以米为单位),障碍物类别和障碍物相对偏转角 (Alpha Angle 和 KITTI 数据集定义一致)。
给图片中目标的3D坐标可以通过内参转换为2D坐标

x0y0是原点便宜,fx,fy是像素,都是厂家给的,s是个尺度变换因子


3D转换到2D是可行的,但是只通过2D的长宽和中心点坐标想实现2D到3D是不可行的

通过约束减少参数

翻滚 - roll - 翻滚角
俯仰 - pitch - 俯仰角
绕 Z 轴左右旋转 (偏摆 - yaw - 偏航角)
从右图可以看到,现在只有 6 维 3D 信息需要预测,但没有办法避免预测中心点坐标 X 和 Y 分量。
(2) 利用成熟的 2D 障碍物检测算法,准确预测出图像上 2D 障碍物框 (以像素为单位)。
(3) 对 3D 障碍物里的 6 维描述,可以选择训练神经网络来预测方差较小的参数,例如障碍物的真实物理大小,因为一般同一类别的障碍物的物理大小不会出现量级上的偏差 (车辆的高度一般在 2-5 米之间,很少会出现大幅变化)。而 yaw 转角也比较容易预测,跟障碍物在图像中的位置关系不大,适合通用物体检测框架来训练和预测。实验中亦证明此项。
现在唯一没有训练和预测的参数就是障碍物中心点相对相机坐标系的偏移量 X 分量和 Y 分量。需要注意的是障碍物离相机的物理距离 。所以得到 X 和 Y,就可以得到障碍物离相机的真实距离,这是单目测距的最终要求之一。
(2) 利用成熟的 2D 障碍物检测算法,准确预测出图像上 2D 障碍物框 (以像素为单位)。
(3) 对 3D 障碍物里的 6 维描述,可以选择训练神经网络来预测方差较小的参数,例如障碍物的真实物理大小,因为一般同一类别的障碍物的物理大小不会出现量级上的偏差 (车辆的高度一般在 2-5 米之间,很少会出现大幅变化)。而 yaw 转角也比较容易预测,跟障碍物在图像中的位置关系不大,适合通用物体检测框架来训练和预测。实验中亦证明此项。
现在唯一没有训练和预测的参数就是障碍物中心点相对相机坐标系的偏移量 X 分量和 Y 分量。需要注意的是障碍物离相机的物理距离 所以得到 X 和 Y,就可以得到障碍物离相机的真实距离,

这是单目测距的最终要求之一。

当我们训练好相应的神经网络,输出我们需要的各个参数之后,我们需要考虑的是如何计算出障碍物离摄像头的距离。通过内参和几何学关系,可以链接起图像中 3D 障碍物大小 (单位为像素) 和真实 3D 坐标系下障碍物大小 (单位为米)。
我们采用单视图度量衡 (Single View Metrology) 来解释这个几何关系:任一物体,已知它的长宽高、朝向和距离,则它在图像上的具体形状大小唯一确定;反之亦然。

基于单视图度量衡,我们可以建立一个哈希查询表 (lookup table),去根据物体图像尺寸、物理尺寸和朝向角来查询物体的距离。
对于每种障碍物,我们根据它的平均 (或单位) 尺寸,去建立查询表,覆盖 360 度 yaw 角的变化,来映射不同的距离。(例如 2D 框的 25 像素高,yaw 角为 30 度,则它的距离为 100 米等等)。图中示例了一个小轿车在不同距离下、不同偏转角 yaw angle 情况下,在图像上的显示。
Deep3Dbox
参考链接1
参考链接2
参考链接3
参考链接4
解决什么问题
从一个单视野恢复3D bounding box,在没有额外的3D形状模型、或有着复杂的预处理通道的采样策略下,估计稳定且精准3D目标
本文创新点
1.从2D框中约束出t,从CNN中回归出方向和尺寸
2.提出用于回归方向的MultiBin
3.提出三个新度量
4.解释了在3D pose估计框架中,选择回归参数的重要性。
核心思想
用两个深度卷积神经网络回归相对稳定的3D物体属性(方向,长宽高),然后将这些属性和2D目标bounding box的几何约束结合起来,生成完整的3D bounding box。
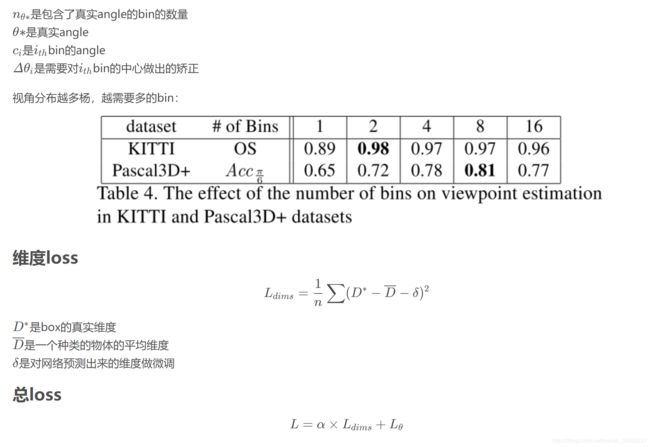
第一个网络用提出的MultiBin loss,来生成3D物体的方向,性能比L2 loss强很多
第二个网络输出回归3D目标的维度,跟回归其他的参数相比,维度的差异相对较小,并且可以利用先验知识
主要思想是3D包围盒在2D检测窗口中的透视射影,作者做出了一种假设:CNN出来的2D框就是3D盒的射影
目标
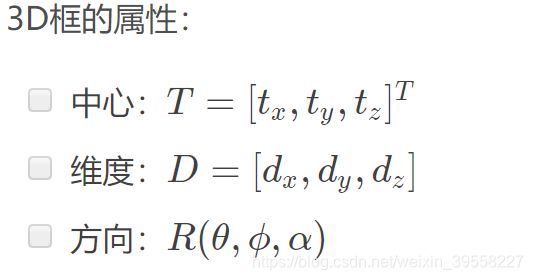
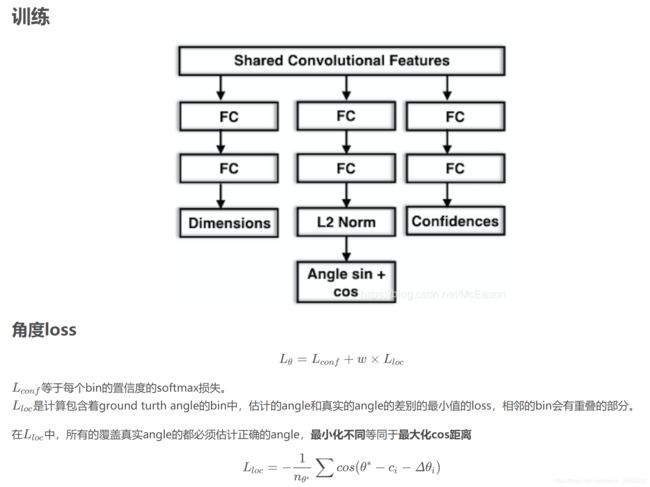
MultiBin loss

ry=theta+alpha
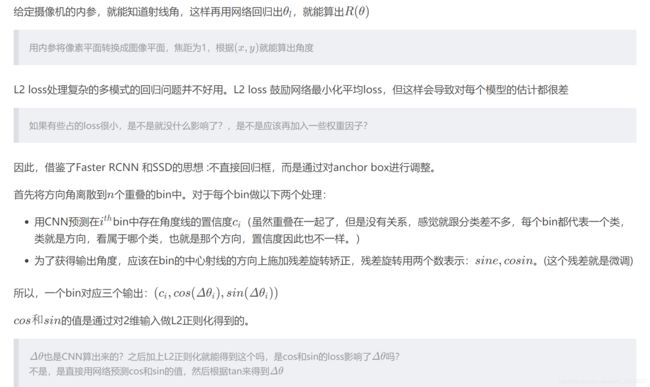
3D到2D影射的要求


注意这里约束数量的解释为:
本文它认为bbox3d应该在bbox2d内。所以建立起了联系。xmin对应的是bbox2d的坐标。另外它还假设了必有bbox3d的点落到bbox2d的边上,如图所示。所以以4为次方。当roll为0的时候,我们只需考虑四个参数,因此有256种情况。当pitch和roll都为0的时候,只需要考虑3D边界框紧密地投影到2D检测窗口中的这种约束要求2D边界框的每一侧被至少一个3Dbox的corner的投影连接。关于64,我的理解是,在kitti数据集中,只考虑yaw角,那么垂直边无需在考虑,只考虑水平边,所以再除以4,垂直边的dz加上水平边的dy dz。
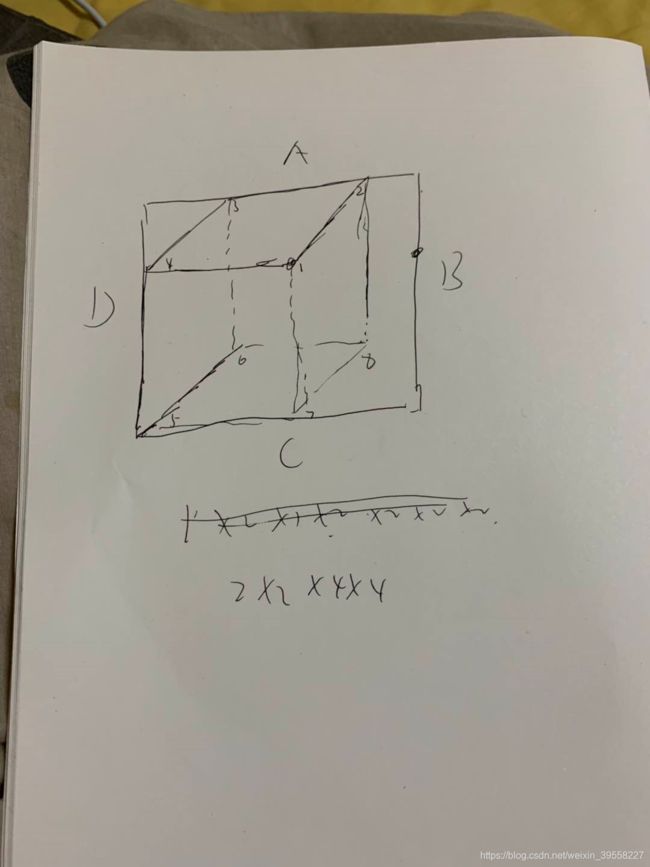
另外一种理解方式:
首先3D被包裹在2D内
8^4是4条边每条边都能对应于8个顶点
4*4*8*8是 因为场景竖直 上边和下边只能分别对应4个点 其他俩边分别对应8个点
4*4*4*4 是 考虑 roll等于0 那么左边和右边也只能对应4个点
64是加上了patch为0,即垂直边无需考虑 2*2*4*4.如下图所示:B只能对应两种可能性,D只能对应两种可能性(这里不确定)
训练和损失
姿态估计(求解T矩阵)
(1)2D图像目标检测以及大小姿态估计网络
这部分相对简单,就是在网上找个目标检测网络源码,在后面加回归分支就好了。同时在数据输入模块加上导入目标大小、朝向lable的代码。
这里需要注意一下,朝向用kitti数据集label格式里的第4个参数来表示,即alpha,不要用最后的角度参数r_y(关于这些角度的定义,大家自行查一下吧)。因为alpha与观察者的视角有关,而r_y木有,下图中车的r_y基本是相同的,但随着观察者的相对位置变化,alpha是变的,对应图像中看到车的不同“样子”,即不同特征,所以用alpha角才合理。我在复现过程中由于不仔细,一开始就直接回归r_y,效果非常差。
2)目标3D中心点解算模块
首先,求解中心点模块需要用到前面预测的H、W、L,还需要KITTI label里最后那个角度r_y。然而,我们刚才明明预测的是alpha呀,肿么办呢,木事木事,两者可以转化呀。转化过程如上面的数据解释部分。
推导过程



上面整个转换过程的代码
import numpy as np
import math
import itertools
#from sympy import *
def solve_T(points_2D, RoarNet2D_pred):
'''
:param points_2D: numpy array, POINTS ON THE IMAGE
:param points_3D: POINTS ON THE WORLD-COR, 8x3
:param RoarNet2D_pred: numpy array, PREDICTION FROM 2DNet
:return: global_T: numpy array 得出的是相机系原点到物体中心的向量
'''
global_T = []
global_iou = -1
global_norm = 100000000000
h = RoarNet2D_pred[0]
w = RoarNet2D_pred[1]
l = RoarNet2D_pred[2]
theta = RoarNet2D_pred[3]
if theta > np.pi:
theta = theta - 2 * np.pi
if theta < -np.pi:
theta = theta + 2 * np.pi
theta = -(np.pi / 2 - theta) # no -
corner = np.array([[w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2],
[-h / 2, -h / 2, -h / 2, -h / 2, h / 2, h / 2, h / 2, h / 2],
[-l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2]])
points_3D = corner.transpose()
corner2 = list(corner)
corner2.append([1, 1, 1, 1, 1, 1, 1, 1])
corner2 = np.array(corner2)
R = [[math.cos(theta), 0, math.sin(theta)],#只有绕y轴的旋转
[0, 1, 0],
[-math.sin(theta), 0, math.cos(theta)]]
R = np.array(R)
K = [[719.787081, 0., 608.463003],
[0., 719.787081, 174.545111],
[0., 0., 1.]]
K = np.array(K)
# character = list(itertools.permutations(points_3D, 4)) # permutations
for i1 in [0, 1, 2, 3]:
for i2 in [0, 1, 2, 3]:
for i3 in [4, 5, 6, 7]:
for i4 in [4, 5, 6, 7]:
p_3D = []
p_3D.append(points_3D[i1, :])
p_3D.append(points_3D[i2, :])
p_3D.append(points_3D[i3, :])
p_3D.append(points_3D[i4, :])
#for i in range(3600): # len(character)
# print(i1)
# p_3D = np.array(character[i])
'''
p_3D = []
for k in range(4):
idx = np.random.choice(range(8))
p_3D.append(points_3D[idx, :])
'''
p_3D = np.array(p_3D)
# p_3D = np.array(character[i])
# t1 = Symbol('t1')
# t2 = Symbol('t2')
# t3 = Symbol('t3')
# func = []
Matr = []
B = []
tmp1 = np.matmul(R, p_3D[0, :].T)
A1 = [[1, 0, 0, tmp1[0]],
[0, 1, 0, tmp1[1]],
[0, 0, 1, tmp1[2]]]
A1 = np.array(A1)
A1 = np.dot(K, A1)
Matr.append([A1[0, 0]-A1[2, 0]*points_2D[0], A1[0, 1]-A1[2, 1]*points_2D[0], A1[0, 2]-A1[2, 2]*points_2D[0]])
B.append(-A1[0, 3]+A1[2, 3]*points_2D[0])
#func.append((A1[0, 0]*t1+A1[0, 1]*t2+A1[0, 2]*t3+A1[0, 3])
# -(A1[2, 0]*t1+A1[2, 1]*t2+A1[2, 2]*t3+A1[2, 3])*points_2D[0])
tmp2 = np.matmul(R, p_3D[1, :].T)
A2 = [[1, 0, 0, tmp2[0]],
[0, 1, 0, tmp2[1]],
[0, 0, 1, tmp2[2]]]
A2 = np.array(A2)
A2 = np.dot(K, A2)
Matr.append([A2[1, 0] - A2[2, 0] * points_2D[1], A2[1, 1] - A2[2, 1] * points_2D[1], A2[1, 2] - A2[2, 2] * points_2D[1]])
B.append(-A2[1, 3] + A2[2, 3] * points_2D[1])
#func.append((A2[1, 0] * t1 + A2[1, 1] * t2 + A2[1, 2] * t3 + A2[1, 3])
# -(A2[2, 0] * t1 + A2[2, 1] * t2 + A2[2, 2] * t3 + A2[2, 3])*points_2D[1])
tmp3 = np.matmul(R, p_3D[2, :].T)
A3 = [[1, 0, 0, tmp3[0]],
[0, 1, 0, tmp3[1]],
[0, 0, 1, tmp3[2]]]
A3 = np.array(A3)
A3 = np.dot(K, A3)
Matr.append([A3[0, 0] - A3[2, 0] * points_2D[2], A3[0, 1] - A3[2, 1] * points_2D[2], A3[0, 2] - A3[2, 2] * points_2D[2]])
B.append(-A3[0, 3] + A3[2, 3] * points_2D[2])
#func.append((A3[0, 0] * t1 + A3[0, 1] * t2 + A3[0, 2] * t3 + A3[0, 3])
# -(A3[2, 0] * t1 + A3[2, 1] * t2 + A3[2, 2] * t3 + A3[2, 3])*points_2D[2])
tmp4 = np.matmul(R, p_3D[3, :].T)
A4 = [[1, 0, 0, tmp4[0]],
[0, 1, 0, tmp4[1]],
[0, 0, 1, tmp4[2]]]
A4 = np.array(A4)
A4 = np.dot(K, A4)
Matr.append([A4[1, 0] - A4[2, 0] * points_2D[3], A4[1, 1] - A4[2, 1] * points_2D[3], A4[1, 2] - A4[2, 2] * points_2D[3]])
B.append(-A4[1, 3] + A4[2, 3] * points_2D[3])
#func.append((A4[1, 0] * t1 + A4[1, 1] * t2 + A4[1, 2] * t3 + A4[1, 3])
# -(A4[2, 0] * t1 + A4[2, 1] * t2 + A4[2, 2] * t3 + A4[2, 3])*points_2D[3])
Matr = np.array(Matr)
B = np.array(B)
B = np.expand_dims(B, 1)
# T = np.matmul(np.linalg.pinv(Matr), B)
T, norm, _, _ = np.linalg.lstsq(Matr, B)
if (T[2, 0]<=0):
continue
M1 = np.hstack((R, T))
# P = np.matmul(K, M1)
# ------------------------------------ #
box3donimg = np.dot(M1, corner2)
box3donimg = np.dot(K, box3donimg)
# box3donimg = box3donimg.transpose()
box3donimg[0] /= (box3donimg[2] + np.finfo(np.float32).eps)
box3donimg[1] /= (box3donimg[2] + np.finfo(np.float32).eps)
F = True
imgwid = (points_2D[2] - points_2D[0])
imghei = (points_2D[3] - points_2D[1])
for iii in range(8):
if (box3donimg[0, iii] < points_2D[0] - 0.2 * imgwid or box3donimg[0, iii] > points_2D[2] + 0.2 * imgwid):
F = False
if (box3donimg[1, iii] < points_2D[1] - 0.2 * imghei or box3donimg[1, iii] > points_2D[3] + 0.2 * imghei):
F = False
if (norm[0] < global_norm and F == True):
global_T = T
global_norm = norm[0]
'''
xmax = np.max(box3donimg[0, :])
xmin = np.min(box3donimg[0, :])
ymax = np.max(box3donimg[1, :])
ymin = np.min(box3donimg[1, :])
if(xmin<0 or ymin<0 or xmax>1224 or ymax>370):
continue
rec = np.array([ymin, xmin, ymax, xmax])
iou = cal_IOU(np.array([points_2D[1], points_2D[0], points_2D[3], points_2D[2]]), rec)
if(iou>global_iou):
global_T = T
global_iou = iou
# print('success ! ')
'''
return np.array(global_T), global_norm
def cal_IOU(rec1, rec2):
# computing area of each rectangles
ttt = rec2[2] - rec2[0]
S_rec1 = (rec1[2] - rec1[0]) * (rec1[3] - rec1[1])
S_rec2 = (rec2[2] - rec2[0]) * (rec2[3] - rec2[1])
# computing the sum_area
sum_area = S_rec1 + S_rec2
# find the each edge of intersect rectangle
left_line = max(rec1[1], rec2[1])
right_line = min(rec1[3], rec2[3])
top_line = max(rec1[0], rec2[0])
bottom_line = min(rec1[2], rec2[2])
# judge if there is an intersect
if left_line >= right_line or top_line >= bottom_line:
return 0
else:
intersect = (right_line - left_line) * (bottom_line - top_line)
return intersect / (sum_area - intersect)
if __name__ == '__main__':
points_2D = np.array([390.79803, 164.44536, 450.4052, 198.81921])
RoarNet2D_pred = [3.6077675533691407, 2.7363950778683472, 35.063437587495116, 1.6609269701170407]
T, _ = solve_T(points_2D, RoarNet2D_pred)
T[1, 0] = T[1, 0] + 3.6077675533691407/2
print(T)
centernet 3D检测部分
相比上面的deep3d centernet还多了直接回归出来的深度,对每个属性都添加单独的head,depth d对每个中心点都要求,但很难直接回归。 论文中做了转换,3dim直接用原始的3dim属性回归 。oritation很难直接回归,方式和deep3d类似,用两个bins的方法回归 一个bins包含了4个scalars,其中两个scalars用softmax分类(属于哪一个bin)标记为bi,另外两个scalars是ai,在每个bin中回归一个角度,一个sin一个cos,一个bin的范围是[-7π/6,π/6],另一个是[-π/6,7π/6]