【Datawhale学习笔记】Pytorch整体框架搭建入门——MNIST时装分类02
在上一篇文章中,有关利用Pytorch完成神经网络的模型搭建已经完成了。从整体流程来看,把神经网络的学习看作是1.数据预处理 2.模型的设计 3.损失函数以及优化方案设计 4.前向传播 5.反向传播 6.更新参数 这6个步骤,其实只完成了前2步。在这篇文章中,开始真正对模型的训练。
第3步:损失函数以及优化方案设计
机器学习和深度学习中针对任务目标(回归/分类)定义了损失函数,比如回归里的最小平方偏差MSD,多分类里的交叉熵CrossEntropy。当输入的参数使得这些损失函数尽可能小的时候,任务就可以完成的越好。
神经网络“学习”的过程实际上就是去找到使得损失函数最小的参数,用到的方法就是梯度下降
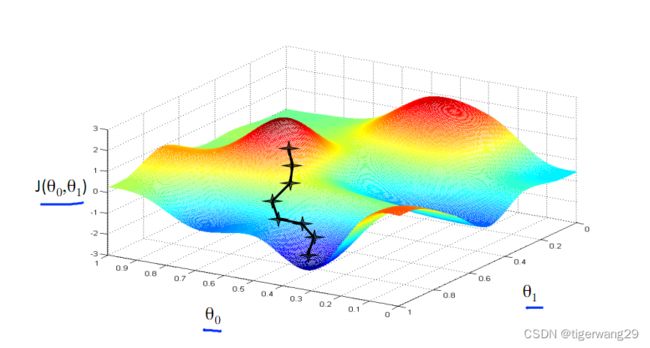
有些时候样本规模很大,梯度下降计算就非常困难,所以也可以选择随机梯度下降、批梯度下降这些优化方法。
从图上可以看出来,梯度下降是通过计算梯度让损失函数收敛到最小值。这里经常遇到几个棘手的问题:得到的最小值很可能是局域最小,而不是全局最小;收敛速度太慢,需要加速;步长太大,一不小心跨过最小值······这些问题就属于优化的范畴了,可以通过动量梯度下降、动态步长法、权重衰减等等方法来进行调整。这些是非常重要的机器学习理论基础,我也在学习过程中慢慢去推导、消化这些理论
优化方案还可以解决过拟合、欠拟合之类的问题,还有就是可以采用一些集成的策略。
在Pytorch中可以直接设置损失函数以及对优化器进行设置,非常方(sha)便(gua)
criterion = nn.CrossEntropyLoss()
optimizer = opt.Adam(model.parameters(),lr) #定义好损失函数和优化器 一切准备就绪,开始训练了:
def train(epoch):
for i in range(epoch):
model.train()
train_loss = 0
for data,label in train_loader:
data,label = data.to(device),label.to(device)
output = model(data)
loss = criterion(output,label)
loss.backward()
optimizer.step()
train_loss += loss.item()*len(data)
train_loss /= len(train_loader.dataset)
print('epoch:{},train_loss:{}'.format(i,train_loss))
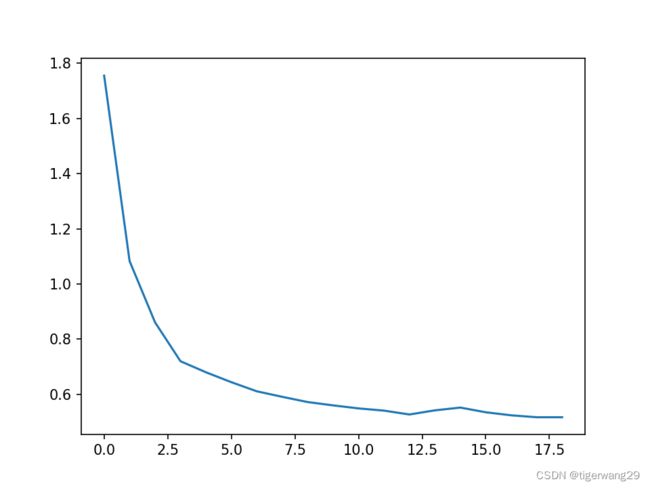
train(20)进行20个epoch的训练,把每轮的损失函数打印出来,也可以尝试用不同的参数、优化方案进行调整。下图是损失函数与epoch之间的关系
 下一步就是看模型在验证集上的表现,验证部分的代码:
下一步就是看模型在验证集上的表现,验证部分的代码:
def test(epoch):
model.eval()
test_loss = 0
get_label =[]
pred_label =[]
with torch.no_grad():#在测试集中,数据是不需要反向传播的
for data,label in test_loader:
data, label = data.to(device), label.to(device)
output = model(data)
loss = criterion(output,label)
preds = torch.argmax(output,1).numpy()
label = label.numpy() #原本输出的是tensor,要转化为numpy
for i in preds:
pred_label.append(i)
for i in label:
get_label.append(i)
test_loss += loss.item()*len(data)
test_loss /=len(test_loader.dataset)
count = 0
for i in range(len(get_label)):
if get_label[i] == pred_label[i]:
count +=1
acc = count/len(get_label)
print('loss:%f,acc:%f' % (loss,acc)) 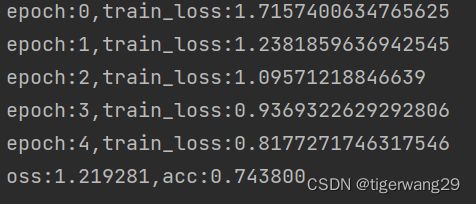
这是执行5个epoch训练后在验证集上的表现,预测准确率acc:0.743
通过调整参数,可以提高在验证集上的准确率:

总结:
用Pytorch来搭建神经网络处理分类任务不难,但真的要很细心!因为我目前是在cpu上进行训练,代码执行的速度还是偏慢,所以也不是很有耐心去一点一点调试模型了,只是初步把代码跑通、理解了在这一框架下的运行逻辑。感觉在实践之前,觉得还挺复杂,做完之后发现这其实也是一个“难者不会,会者不难”的东西
从5月份开始学习机器学习,到现在差不多3个月的时间,对这方面的兴趣真的是越来越浓厚。在8月份之前,我的学习重点主要集中在理论部分,看看书、推推公式,甚至还花了一些时间看《算法导论》补算法方面的基础(物理系学生,大学期间没有选修过任何关于计算机的课程,自觉基础很是薄弱;但数学能力还行,因此理论上的东西一点点去啃倒觉得津津有味)。时间长了就感觉这样的学习方式有点“叶公好龙”了。
一开始迟迟没有实践是因为比较懒,或者是有点畏惧比较繁琐的东西:比如Pytorch的安装和环境配置就非常新手不友好,代码的调试、debug也很有挑战。不过总归迈出了自己的第一部,当界面返回第一个结果时,内心充满了成就感!
继续努力!学以致用。