论文笔记-对话系统综述
原文出自彼得攀的小站
本文是对论文“A Survey on Dialogue Systems: Recent Advances and New Frontiers”的阅读笔记,该文章是关于对话系统的综述,最后一次修改于2018年年初,主要对2018年之前对话系统相关技术做了一个概要性总结
论文地址
文中[45]这样的编号代表论文中参考文献的编号,可以查阅原始论文
引言
深度学习技术是现在对话系统采用的主流技术,其可以通过大规模数据来学习有意义的特征表示,并得到较好的文本生成策略,该过程仅需要很少、或者完全不需要人工特征。
对话系统可以被分为task-oriented(任务导向)和non-task-oriented (非任务导向)
Introduction
面向任务的系统旨在帮助用户完成某些任务(例如查找产品,预订住宿和餐馆)。广泛应用于面向任务的对话系统的方法是将对话回复作为一个流水线来处理。系统首先理解人类给出的信息,将其表示为一个内部状态,然后根据策略和对话状态选择一些动作,最后把动作转化为自然语言的表达形式。尽管语言理解是通过统计模型来处理的,但是大多数已部署的对话系统仍然使用人工特征或人工编写的规则来处理状态和动作空间的表示,意图检测和槽填充。这不仅使得部署真正的对话系统耗费大量时间,而且还限制了其在其他领域进行使用的能力。最近,许多基于深度学习的算法通过学习高维分布式特征表示来缓解这些问题,并在一些方面取得了显著的进步。此外,还有尝试建立端到端的面向任务的对话系统,这种对话系统可以扩展传统流水线系统中的状态空间表示,并有助于生成任务特定语料库以外的对话。
非面向任务的系统在与人类交互过程中提供合理的反应和娱乐。通常,非面向任务的系统致力于在开放域与人交谈。虽然非面向任务的系统似乎在进行闲聊,但是却在许多实际的应用程序中占有一席之地。 有研究表明,近80%在线购物场景中的对话都是闲聊消息,而处理这些信息与用户体验密切相关。一般而言,针对非面向任务的系统开发了两种主要方法:
- 生成方法,例如seq2seq模型,其在对话过程中产生适当的回复;
- 基于检索的方法,学习从数据库中选择当前对话的回复。
任务导向的对话系统
这里主要介绍流水线方法(Pipline methods)和端到端方法(end-to-end methods)
流水线方法
流水线方法的示意图如下所示:
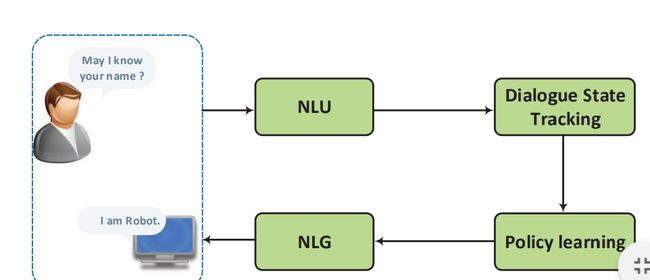
其包含四个部分:
- 语言理解:通常被认为是自然语言理解(NLU),它把用户意图解析成预定义的语义槽
- 对话状态追踪器(Dialogue State Tracking):其管理每轮对话的输入及历史状态,并输出当前的对话状态
- 对话策略学习(Dialogue policy learning):其根据当前的对话状态来学习下一步的动作
- 自然语言生成(NLG):其将学习到的动作映射到表层,生成回复
语言理解(NLU)
语言理解的任务是:给定一句话,NLU将其映射到语义槽中,这些语义槽都是根据不同的对话场景预定义的。
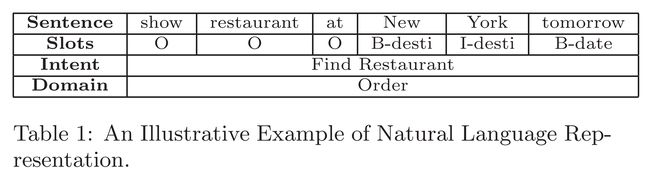
上图是一个自然语言表示的例子,"New York"被映射到了desti这一个语义槽,在映射过程中同时确定了该对话的领域:order和对话意图:预定餐馆。
通常来说, 有两种不同类型的语言表示:
- 对话级别(utterance-level):某种程度上可以理解成句子级别的表示,可以表示如用户意图、对话类别
- 词级别(word-level):即词级别的信息抽取,如命名实体识别、语义槽填充
整个NLU主要包含两个部分:
- 意图检测是用来检测用户意图的,它可以把对话分类为预定义的意图。在其中,深度学习也有着广泛应用,例如利用CNN提取查询的向量表示作为特征,从而对查询做分类。类似的方法也应用于语言主题、领域分类
- 槽填充(Slot filling)是口语语言理解中另一个具有挑战性的问题。与意图检测不同,槽填充通常被定义为序列标注问题,句子中的词被赋予语义标签。输入是由一系列单词组成的句子,输出是一个槽/概念的索引序列,每个单词一个。现有的方法使用深度信念网络(DBN),与CRF方法相比取得了优异的结果。同样也有使用RNN做槽填充。
由NLU生成的语义表示将有对话管理模型进一步处理,典型的对话管理模包括两个部分:对话状态追踪(Dialogue State Tracking)和策略学习(Policy learning)
对话状态跟踪(Dialogue State Tracking)
对话状态追踪是保证对话系统鲁棒性的核心组成部分。它会估计每轮对话中用户的意图。对话状态 H t H_t Ht表示到时刻t时,整个对话历史的表示。
这种经典的状态结构通常被称为槽填充(slot filling)和语义框架(semantic frame)。传统方法(也是迄今为止大多数商业系统选择的方法)通常采用手工制订的规则来选择最有可能的结果。然而这样的基于规则的系统很容易出现错误,其得出的最有可能的结果往往不是理想的结果。
基于统计的对话系统在有噪声的条件和不确定的情况下,维护了对真实对话状态的多重假设的分布。在对话状态跟踪中,生成结果的形式是每轮对话中每个语义槽的值的概率分布。各种统计方法,包括复杂的手工制定规则、条件随机场、最大熵模型、网络风格排名(web-style ranking)都被应用在了对话状态跟踪的共享任务中。
当前,结合了深度学习的信念追踪表现出了更好的效果。 它使用一个滑动窗口输出任意数量的可能值的一系列概率分布。虽然它是在某一个领域的训练出来的,但它可以很容易地转移到新的领域。[48]开发了多领域RNN对话状态跟踪模型。它首先使用所有可用的数据来训练一个泛化的信念跟踪模型,然后对每一个特定领域利用这个泛化模型进行领域化,从而学习领域特定的行为。[49]提出了一个神经信念跟踪器(NBT)来检测槽-值对。它将用户输入之前的系统对话行为、用户说话本身和一个候选slot-value对作为输入,然后遍历所有候选slot-value对,以确定用户刚刚表达了哪些slot-value对
策略学习(policy learning)
记忆状态跟踪器获得的状态表示,策略学习(policy learning)将产生下个可用的系统动作。无论是监督学习还是强化学习都可以被用于优化策略学习。通常,基于规则的智能体将被用于热启动系统[86],然后利用规则生成的动作进行监督学习。在在线购物场景中,如果对话状态是“推荐”,那么“推荐”动作将被触发,系统将会从产品数据库中检索产品。如果状态是“比较”,系统则会比较目标产品/品牌[98]。对话策略可以通过进一步端到端的强化学习进行训练,以引导系统朝着最终性能做出决策。[9]在对话策略中利用深度强化学习,同时学习特征表示和对话策略。该系统超过了包括随机、基于规则和基于监督学习的baseline方法。
自然语言生成(NLG)
自然语言生成将通过policy learning得到的抽象的对话动作转化为自然语言的浅层对话,在[78]中,提到一个好的生成器通常满足4个条件:
- 充分性(adequacy)
- 流利性(fluency)
- 可靠性(readability)
- 变化性(variation)
传统的NLG通常采用句子规划(sentence planning),其将输入的语义符号映射成表示对话的树状结构或模板结构等中间形式,然后通过表层实现(surface realization)将中间结构转换成最终结果。
[94]和[95]引入了基于神经网络的NLG方法,该方法采用了一个类似于RNNLM的LSTM-based 结构。其将对话动作类型和slot-value pair转化为一个one-hot词向量作为额外输入,来确保生成的对话能够准备表达我们所要表达的意图。[94]时使用了一个前向RNN生成器、一个CNN重排器、一个后向RNN重排器,所有的子模块共同作用,基于需要的对话动作来生成对话。为了解决在表层实现(surface realization)中槽信息缺失和重复的问题,[95]使用了额外的控制单元来门控对话动作。[83]通过利用对话动作来选择LSTM的输入向量,扩展了这一方法。这个问题后来通过多步调整扩展到多领域场景[96]。[123]采用基于encoder-decoder的LSTM-based的结构,结合问题信息,语义槽值和对话动作类型来生成正确答案。它使用注意力机制来关注解码器当前解码状态的关键信息。通过编码对话动作类型嵌入,基于神经网络的模型可以生成许多不同动作类型的回复答案。[20]还提出了一种基于seq2seq的自然语言生成器,可以被训练用于利用对话动作输入来产生自然语言和深度语法树。这种方法后来利用之间用户的话语和回复进行了扩展[19]。它使模型能够使用户适应(说话)的方式,从而提供适当的回复。
端到端(End-to-End)方法
传统的面向任务的对话系统有许多领域特定的人工干预(如手工编写的规则,人为提取的特征),这导致在一个领域中表现很好的方法很难适应新的领域[7];[120]进一步指出,面向任务的对话系统中,传统流水线方法还有两个主要缺陷:
- 一个是分数分配问题(credit assignment problem),最终用户的反馈很难会传到上游模块中。
- 二是处理是相互依赖。每个模块的输入都依赖于另一个模块的输出,当调整一个模块时或者用新数据进一步更新是,所有其他模块都要进行相对应的调整以保证全局的优化。槽和特征可能也会相对应的改变。这种过程需要大量的人工干预。因为过程中slots 和features都是task-specificed。
不同于传统的流水线技术,端到端的方法使用单个模块,并使用这个模块对结构化的外部数据来进行交互。
[97]和[7]引入了一个基于神经网络的端到端可训练的面向任务的对话系统。这个系统将对话系统的学习当做学习一个从对话历史到系统回复的映射,利用编码器-解码器模型训练整个系统。然而,这个系统是以监督学习方式进行训练的——不仅需要大量的训练数据,而且由于缺乏对训练数据中对话控制的探索,也很难地找到一个好的策略。
[120]首先提出了一个端到端的强化学习方法,在对话管理中共同训练对话状态跟踪和政策学习,以便更好地优化系统动作。在对话中,智能体询问用户一系列是/否问题来找到正确的答案。这种方法在任务导向的对话任务中表现良好,例如猜测用户脑海中想着的名人。
[36]将端到端系统作为task-completion neural dialogue system,其最终目标是完成一项任务,如电影票预订。
任务导向的对话系统通常还需要查询外部知识库,之前的系统通过语义分析(semantic parsing)来形成一个query,在知识库中检索,匹配得到想要的entities。这种方法有两个主要的缺点:
- 检索结果不包含语义分析中的不确定信息
- 检索的过程不可微(non differentable),由此,语义分析和对话策略只能分开训练,online end to end的模型一旦部署完成,很难从用户反馈中来学习。
为了解决这样的问题:
- [21] 提出了一种通过一个在知识库条目上可导的基于注意力机制的key-value检索机制来增强现有的循环神经网络,该方法受启发于key-value memory network [54].
- [18] 将符号化查询替换为在知识库上导出的后验概率,该概率可以表示用户感兴趣的entities。再将这个soft retrieval的过程和强化学习相结合。
- [102] 将RNN和领域特定的知识库相结合,编码为系统回复模板
非任务导向的对话系统
non-task-oriented dialogue systems也被称为聊天机器人,其关注与在开放域上与人类进行交流。一般来说,聊天机器人通过生成模型和基于检索的方法实现。
- 生成模型可以生成更加适合(即贴近上下文)的回复,这些回复可能从未出现在语料库中
- 基于检索的方法从存储库中为当前对话选择回复,由此,其回复通常含有更加丰富的信息且更为流畅
Neural Generative Models
神经生成模型在机器翻译中有着很成功的应用,这样的成功,激发了人们对于神经生成对话系统的研究。[64]提出了一种生成概率模型,其基于phrase-based统计机器翻译,它将回答问题视作一个翻译问题,一个post被翻译为response。但是生成回复的过程比翻译要更为困难:
- 一个问题可以有很多合理的回复
- 回复和问题之间,不如机器翻译中源语言语句和目标语言语句那样具备对齐关系
神经生成模型的基础是sequence-to-sequence模型,当下神经生成模型主要关注:
- 结合对话上下文,提高回复的多样性(response diversity)、建模主题(topic)和个性(personalities)
- 利用外部知识库,交互式学习和评估
sequence-to-sequence模型
Sequence-to-Sequence 模型,可以简称为seq2seq。给定一个有 T T T个词的源序列(消息): X = ( x 1 , x 2 , … , x T ) X=\left(x_{1}, x_{2}, \ldots, x_{T}\right) X=(x1,x2,…,xT), 和一个包含 T ′ T^′ T′个词的目标序列(回复): Y = ( y 1 , y 2 , … , y T ′ ) Y=\left(y_{1}, y_{2}, \dots, y_{T^{\prime}}\right) Y=(y1,y2,…,yT′)。seq2seq模型的目标是最大化,在给定X的条件下,生成Y的概率:
p ( y 1 , … , y T ′ ∣ x 1 , … , x T ) p\left(y_{1}, \ldots, y_{T^{\prime}} | x_{1}, \ldots, x_{T}\right) p(y1,…,yT′∣x1,…,xT)
Seq2seq模型是一种encoder-decoder的结构,如上图所示。相关的介绍有很多,这里就不再赘述。
Dialogue Context
可靠的对话系统应当能建立可保持的活跃对话,而考虑对话历史是建立一个这样的对话系统的关键:
-
[77] 通过连续表示 or 单词、短语嵌入来表示整个对话历史(包括当前消息),从而解决了上下文敏感的回复生成的挑战。
该方法的回复通过RNN语言模型生成,与[12]中的解码器相同 -
[68]使用层次模型,首先捕捉个别对话的含义,再将其整合在一起。[109]通过注意力机制扩展了层次模型,这样更关注句子内部和句子之间重要的部分。这里的注意力机制包括word-level和utterance-level。[82] 在现有的方法之间做了系统的比较(包括层次模型和非层次模型),并提出了一个利用查询相关度对上下文(对话历史)加权的变体。文章最后有两个结论:
- 分层循环神经网络通畅优于非分层循环神经网络
- 结合历史信息,神经网络往往会产生更长,且更有意义和多样性的回复
Response Diversity
在当前的seq2seq对话系统中,一个具有挑战性的问题是,它们倾向于产生意义不大的普通或不重要的、普适的回答,比如“I don’t know" 或者"I’m OK"这样的高频短语。
模型的这种表现可以归咎于训练数据中,这样普适的回答出现的频率很高,比如“I don’t know”。 而具有更多信息的回答相对更加稀疏。现有的减轻这种问题的有以下方法:
-
找到一个更好的目标函数,[38] 指出,模型在给定输入的情况下,优化输出的极大似然时,会倾向于给“safe response”(普适回答)赋予更高的概率。
- 基于这样的原因,[38] 使用了最大互信息(MMI)作为优化目标,MMI最开始在语音识别领域引入,它度量了输入和输出之间的相互依赖关系,并考虑了消息回复的逆向依赖性。
- [114] 则在训练过程中结合了IDF(inverse document frequency)来评估回复的多样性(在不同的文档中,出现的回复次数越多,权重越多,多样性就越差)
-
也有一些研究表明,解码过程也是候选回复冗余的一个原因。[86]、[72]、[42] 认为beam search在解码产生候选时缺乏多样性:
- [72] 引入了一个随机的beam search
- [86] 通过加入一个dissimilarity term (可以度量不同候选回复之间多样性) 来增强beam search的目标函数。
- [72] 增加了一个惩罚项,从而惩罚来自同一父节点中子节点的展开。
-
[38; 77; 72] 结合了全局特征,重新执行re-ranking,从而避免生成无聊或者普适的回复
-
PMI:[57] 猜测问题不仅仅在于解码和 respones 的频率,而且消息本身也缺乏足够的信息。 它提出使用逐点互信息(PMI)来预测名词作为关键词,反映答复的主要依据,然后生成一个包含给定关键字的答复。
-
也有一些工作通过引入随机隐变量来产生更多的不同输出。他们认为自然对话不是确定性的:对于同一消息的回答会因人而异。但是当前回复是从确定性encoder-decoder模型中采样得到。通过加入隐变量 ,这些模型可以再生成时,先对隐变量的分配采样,再确定性的解码,从分布中采样得到回复
- [11] 针对oen-shot 对话回复提出了隐变量模型,该模型在解码器
中加入随机变量z,z根据[34; 33; 75]中的自编码框架计算
- [69] 将隐变量引入到层次对话模型框架,该隐变量用于high-level的选择,如主题、情感。
- [73] 将隐变量限定在显式属性上,以使隐变量更易于解释。 这些属性可以手动分配,也可以自动检测这些主题和个性
Topic and personality
显示地学习对话的内在属性是改善对话多样性,保持对话一致性的另一种方法:
- [Topic aware neural response generation, AAAI 2017] 注意到人们经常会把他们的对话和主题相关的一些概念联系起来,并且根据这些概念来做出回复。文章中他们用Twitter LDA model 来获取输入的主题,将主题信息和输入的表示 加入一个joint attention module中,并获得主题相关的回复。[107] 通过改进解码器,实现了更好的效果。[13] 则对该问题进行了进一步的泛化,他们将对话中的每个语句分类到一个domain,并由此产生下一个语句的domain和context。
- [67] 对高层次、粗粒度的tokens sequence 和 dialogue generation进行了联合建模。其中high-level、粗粒度的tokens sequence主要用来探索high-level的语义信息,如nouns 和 activity-entitiy
- [122] 将情绪表示 加入到生成模型中,并在困惑度中取得了良好的表现。[3] 则通过三种方式来增强回复中的情感:
- 结合认知工程的情感词嵌入
- 用一个受影响约束的目标函数来增加优化目标
- 将情感差异融入到beam-search中
- [61] 为对话系统赋予了一个身份标识,从而使得系统可以回复个性化的问题,并保持一致[39] 则进一步地考虑了用户的信息,从而创建一个更加现实的聊天机器人
- 由于训练数据来自于不同的人,由此训练数据会出现不一致的情况 [119] 提出了两段式的训练策略,该方法使用大规模数据对模型进行初始化,再对模型进行微调以产生个性化的回复 [55] 使用迁移学习来消除不一致
Outside Knowledge Base
人类对话与对话系统一个重要区别是它是否与现实相结合。结合外部知识库(KB)是一种有可能弥补对话系统与人类之间背景知识差距的方法。
记忆网络是利用知识库来处理问答任务的经典方法,也有在对话生成任务上应用的相关尝试:
- [16]在此之上做了尝试,并在开放域对话中取得了不错的成绩。
- [75]也通过在多模态空间中进行CNN嵌入和RNN嵌入,在有背景知识下展开开放域对话,并在困惑度上取得了进步。
- 根据外部知识产生一个问题的答案是一个类似的任务。与一般方法中在知识库中检索元组不同,[103]将知识库中的词与生成过程中常见的词相结合。实证研究表明,所提出的模型能够通过参考知识库中的事实来产生自然而正确的答复
Interactive Dialogue learning
通过交互来学习是对话系统的一个终极目标:
- [43] 利用两个虚拟智能体来模拟对话,他们认为一个好的对话应当是有前瞻性的 [1] or 交互式的 (当前轮应当为下一轮的对话制作铺垫)且是信息丰富、连贯的。一个encoder-decoder RNN的所有参数定义了一个在无穷大的动作空间上从所有可能的话语中进行选择的策略。智能体通过策略梯度方法[104]来优化由开发者定义的长期奖励,而不是通过标准的seq2seq的MLE目标函数来学习策略。[40] 试图进一步提高机器人从交互中学习的能力,其通过对文本和数字反馈使用策略学习和前向预测,该模型可以通过(半)在线方式与人进行交互来提高自身性能。
- 由于大多数人类在对答案并不自信时通常会要求提供一些澄清或者提示,所以也希望机器人拥有这种能力。[41]定义了机器人在回答问题时遇到问题的三种情况。与不采用提问的实验结果相比,这种方法在一些情况下有了很大的改进。[37]在谈判任务中进行了探索。由于传统的seq2seq模型模拟人类的对话时没有优化具体的目标,这项工作采取了面向目标的训练和解码方法,并展示了一个有价值的方向。
Evaluation
如何评估对话系统回复的质量是一个关键问题。对于任务导向的对话系统而言,可以根据人工生成的监督信号来进行评估,比如任务完成测试或用户满意度评分。对于非任务导向的对话系统,由于回复的多样性,自动评估其回复的质量仍然没有一个可靠的方法,当前主要是以下的几种方法:
- BLEU, METEOR, and ROUGE 值,这些都主要是用来评估词汇的重叠度。[46] 在研究中发现,这些度量和由词嵌入模型导出的词嵌入度量方法和人的判断几乎没有联系。
- 利用神经网络模型来评估
- 进行图灵测试
基于检索的方法
基于检索的方法从多个候选回复中选择一个。基于检索方法的关键是message-response的匹配。匹配算法需要能克服message和response之间的语义差异
单轮回复匹配
早期的相关研究主要关注单轮对话中的回复选择 [91], 其中message仅仅用来选择一个合适的回复。典型做法是将message和response candidates 编码为语义向量,然后计算这两个向量的匹配分数。设x为message的向量,而y是response的向量,那么x和y的匹配算法可以写做一个双线性匹配:
match ( x , y ) = x T A y \operatorname{match}(x, y)=x^{T} A y match(x,y)=xTAy
其中A是一个预定义的矩阵(也可能更为复杂)。
之后[49] 提出了一个同时结合本地和隐式层次结构信息的DNN-based的短文本回复选择模型。[28] 利用深度卷积神经网络学习消息与回复的表示,或是直接学习两个句子交互的表示,再利用多层感知机计算匹配分数改进了这个模型。 [92] 提取了依存树的匹配特征,利用这些特征当做one-hot向量,作为前馈神经网络的输入,从而计算message-response的匹配。[105] 结合了Twitter LDA模型生成的topic向量,送入基于CNN的结构来利用富文本提升回复性能
多轮回复匹配
基于检索的多轮对话是在近期受到了比较多的关注。在多轮对话回复的选择中,当前消息和之前的对话都会被作为模型输入,模型会选择与整个文本最相关且自然的回复。由此,需要模型能识别出之前对话中的关键信息、并建模对话之间的关系来保持对话一致性:
- [48] 利用基于RNN/LSTM的结构编码了整个上下文(上下文来自之前所有的对话和当前消息的拼接)和候选回复的向量。然后基于这两个向量计算匹配分数。
- [110] 利用不同策略在之前出现的对话中选出一些对话,再结合当前消息生成一个重组的上下文
- [124] 不仅在word-level的上下文向量中进行上下文-回复匹配,还引入了sentence-level的上下文向量
- [106] 进一步提高了利用对话之间的关系和上下文信息来匹配回复的方法。这种方法通过卷积神经网络,得到多种不同粒度的文本,然后在时序上利用循环神经网络进行累加,来建模句子之间的相关性。
混合方法(Hybrid Methods)
将生成和检索方法结合起来能对系统性能起到显著的提升作用。通常来说:
- 基于检索的系统通常给出精确但是较为生硬的答案
- 而基于生成的系统则倾向于给出流畅但却是毫无意义的回答。
在集成模型中,被抽取的候选对象和原始消息一起被输入到基于RNN的回复生成器中。这种方法结合了检索和生成模型的优点,这在性能上具备很大的优势。[70]综合了自然语言生成,检索模型,包括基于模板的模型、词袋模型、seq2seq神经网络和隐变量神经网络,应用强化学习学习众包数据和真实世界用户的交互从而从集成模型中选择一个合适的回复。
Discuss and Conclusion
深度学习已经成为对话系统的基础技术。研究人员将神经网络应用于传统的面向任务的对话系统的不同模块,包括自然语言理解,自然语言生成,对话状态跟踪。近年来,端到端框架不仅在非面向任务的聊天对话系统中,而且在面向任务的对话框架中也变得流行起来。深度学习能够充分利用大量数据,并有望建立统一的智能对话系统。它正在模糊面向任务的对话系统和非面向任务的系统之间的界限。尤其,聊天对话由seq2seq model直接建模。Task Completion model也正朝着端到端可训练方式发展,通过强化学习表示整个状态-动作空间,并结合整个流水线。
值得注意的是,目前的端到端模型还远未完善。尽管有上述成就,但问题依然存在。接下来,我们讨论一些可能的研究方向:
- Swift Warm-Up:通常来说,对话数据的规模是较大的,然而对于特定领域而言,对话数据往往较少,在实际的对话工程中,在新领域的预热阶段,仍然需要依靠传统的流水线技术。
- Deep Understanding: 目前基于神经网络的对话系统主要依赖于大量不同类型的有标注数据、结构化的知识库和对话数据。这导致回复缺乏多样性,而且有时是没有意义的。因此,对话智能体应当通过对语言和现实世界的深度理解来更加有效地学习。比如,对话智能体能够从人的指导中学习,摆脱反复的训练。由于互联网上有大量的知识,如果对话智能体更聪明一些,就够利用这种非结构化的知识资源来理解。最后但依然很重要的一点,对话智能体应该能够做出合理的推论,找到新的东西,分享跨领域的知识,而不是像鹦鹉学舌。
- Privacy Protection:当下,对话系统服务的对象越来越多,而往往很多人使用的是同一个对话系统。对话系统会无意间存储一些用户的敏感数据。所以在构建更好的对话系统的同时,也应该注意保护用户的隐私。