3.2.3 如何解决数据不匹配问题
在不同的划分上进行训练并测试
深度学习,对于数据的要求量很大。但有时候我们难以收集到足够的数据,可能一些其他数据要从其他办法来获得,这样就会容易出现不同数据的分布不同的情况。那么我们应该怎么办呢?

假设你在开发一个手机应用,用户会上传他们用手机拍摄的照片,你想识别用户从应用中上传的图片是不是猫。我们真正想要识别的是用户上传的图片。但是关于这些图片我们手头的数据量是不够的。我们也可以从网上下载大量的图片。但是这两种图片的分布是不一样的,比如说从网上下载的图片分辨率更高,用户上传的图片分辨率比较低。比如说我们手头只有1万张用户的图,有20万张网上下载的图片。
这里有一种选择,你可以做的一件事是将两组数据合并在一起,这样你就有21万张照片,你可以把这21万张照片随机分配到训练、开发和测试集中。为了说明观点,我们假设你已经确定开发集和测试集各包含2500个样本,所以你的训练集有205000个样本。现在这么设立你的数据集有一些好处,也有坏处。好处在于,你的训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果你观察开发集,看看这2500个样本其中很多图片都来自网页下载的图片,那并不是你真正关心的数据分布,你真正要处理的是来自手机的图片。
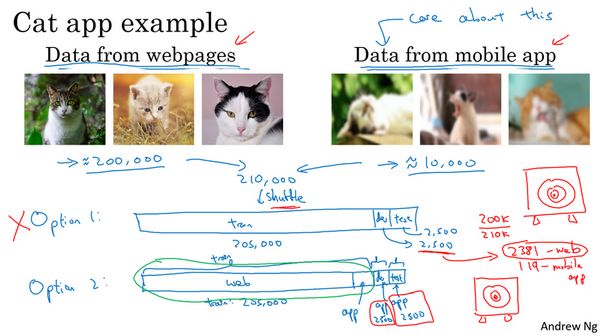
我建议你走另外一条路,就是这样,训练集,比如说还是205,000张图片,我们的训练集是来自网页下载的200,000张图片,然后如果需要的话,再加上5000张来自手机上传的图片。然后对于开发集和测试集,这数据集的大小是按比例画的,你的开发集和测试集都是手机图。而训练集包含了来自网页的20万张图片,还有5000张来自应用的图片,开发集就是2500张来自应用的图片,测试集也是2500张来自应用的图片。这样将数据分成训练集、开发集和测试集的好处在于,现在你瞄准的目标就是你想要处理的目标,你告诉你的团队,我的开发集包含的数据全部来自手机上传,这是你真正关心的图片分布。我们试试搭建一个学习系统,让系统在处理手机上传图片分布时效果良好。缺点在于,当然了,现在你的训练集分布和你的开发集、测试集分布并不一样。但事实证明,这样把数据分成训练、开发和测试集,在长期能给你带来更好的系统性能。我们以后会讨论一些特殊的技巧,可以处理 训练集的分布和开发集和测试集分布不一样的情况。
不匹配数据划分的偏差和方差
估计学习算法的偏差和方差真的可以帮你确定接下来应该优先做的方向,但是,当你的训练集来自和开发集、测试集不同分布时,分析偏差和方差的方式可能不一样,我们来看为什么。
我们之前讲过,如何在不同划分上进行训练,并测试。这里我们的训练集和测试集的分布是不一样的。因此,如果训练集的误差是1%,在测试集的误差是10%。因为两个数据集的分布不同。幽灵我们不能下结论,说该算法的泛化能力不够好。那么我们应该怎么做呢?如何分析到底是什么引起的误差?
我们要做的是随机打散训练集,然后分出一部分训练集作为训练-开发集(training-dev),就像开发集和测试集来自同一分布,训练集、训练-开发集也来自同一分布。
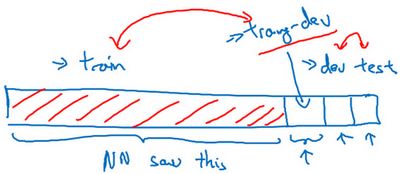
但不同的地方是,现在你只在训练集训练你的神经网络,你不会让神经网络在训练-开发集上跑后向传播。为了进行误差分析,你应该做的是看看分类器在训练集上的误差,训练-开发集上的误差,还有开发集上的误差。

比如说这个样本中,训练误差是1%,我们说训练-开发集上的误差是9%,然后开发集误差是10%,和以前一样。你就可以从这里得到结论,当你从训练数据变到训练-开发集数据时,错误率真的上升了很多。而训练数据和训练-开发数据的差异在于,你的神经网络能看到第一部分数据并直接在上面做了训练,但没有在训练-开发集上直接训练,这就告诉你,算法存在方差问题,因为训练-开发集的错误率是在和训练集来自同一分布的数据中测得的。所以你知道,尽管你的神经网络在训练集中表现良好,但无法泛化到来自相同分布的训练-开发集里,它无法很好地泛化推广到来自同一分布
我们来看一个不同的样本,假设训练误差为1%,训练-开发误差为1.5%,但当你开始处理开发集时,错误率上升到10%。现在你的方差问题就很小了,因为当你从见过的训练数据转到训练-开发集数据,神经网络还没有看到的数据,错误率只上升了一点点。但当你转到开发集时,错误率就大大上升了,所以这是数据不匹配的问题。数据集和测试集的分布不一样。
如果是训练误差是10%,训练-开发误差是11%,开发误差为12%。那就真的存在偏差问题了。存在可避免偏差问题,因为算法做的比人类水平差很多,所以这里的偏差真的很高。
最后一个例子,如果你的训练集错误率是10%,你的训练-开发错误率是11%,开发错误率是20%,那么这其实有两个问题。第一,可避免偏差相当高,因为你在训练集上都没有做得很好,而人类能做到接近0%错误率,但你的算法在训练集上错误率为10%。这里方差似乎很小,但数据不匹配问题很大。所以对于这个样本,我说,如果你有很大的偏差或者可避免偏差问题,还有数据不匹配问题。
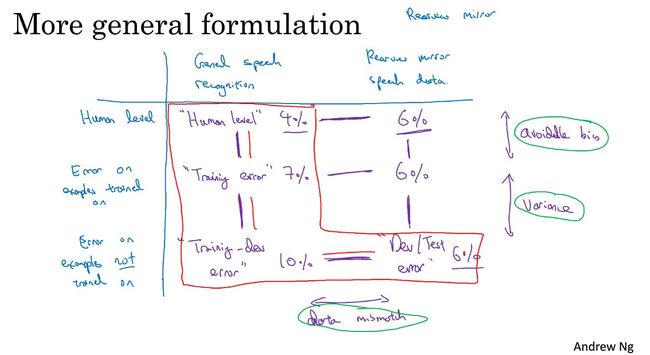
我们可以把整个分析过程,用一张图来表示。如上图所示。这张图片是以某个个语音识别任务为例的。与某些特定的语音识别任务而言。可能存在数据不够的问题。所以我们加过一些一般语音识别数据。所以,图表的左侧是一般语音识别的准确度。而右侧,是该特定语音识别任务的准确度。
从“Training-dev error”到“Dev/Test error”衡量了数据不匹配的问题。如何处理数据不匹配呢?我们下面介绍一下。
定位数据不匹配
如果您的训练集来自和开发测试集不同的分布,如果错误分析显示你有一个数据不匹配的问题该怎么办?这个问题没有完全系统的解决方案,但我们可以看看一些可以尝试的事情。如果我发现有严重的数据不匹配问题,我通常会亲自做错误分析,尝试了解训练集和开发测试集的具体差异。技术上,为了避免对测试集过拟合,要做错误分析,你应该人工去看开发集而不是测试集。
对于数据不匹配问题,最好的解决办法就是尽可能的把训练集变得和测试集是同一个分布。当然,有的时候可能不太容易实现。
有一个解决办法是人工合成。
现在我们要提醒一下,人工数据合成有一个潜在问题,比如说,你在安静的背景里录得10,000小时音频数据,然后,比如说,你只录了一小时车辆背景噪音,那么,你可以这么做,将这1小时汽车噪音回放10,000次,并叠加到在安静的背景下录得的10,000小时数据。如果你这么做了,人听起来这个音频没什么问题。但是有一个风险,有可能你的学习算法对这1小时汽车噪音过拟合。特别是,如果这组汽车里录的音频可能是你可以想象的所有汽车噪音背景的集合,如果你只录了一小时汽车噪音,那你可能只模拟了全部数据空间的一小部分,你可能只从汽车噪音的很小的子集来合成数据。

而对于人耳来说,这些音频听起来没什么问题,因为一小时的车辆噪音对人耳来说,听起来和其他任意一小时车辆噪音是一样的。但你有可能从这整个空间很小的一个子集出发合成数据,神经网络最后可能对你这一小时汽车噪音过拟合。我不知道以较低成本收集10,000小时的汽车噪音是否可行,这样你就不用一遍又一遍地回放那1小时汽车噪音,你就有10,000个小时永不重复的汽车噪音来叠加到10,000小时安静背景下录得的永不重复的语音录音。这是可以做的,但不保证能做。但是使用10,000小时永不重复的汽车噪音,而不是1小时重复学习,算法有可能取得更好的性能。人工数据合成的挑战在于,人耳的话,人耳是无法分辨这10,000个小时听起来和那1小时没什么区别,所以你最后可能会制造出这个原始数据很少的,在一个小得多的空间子集合成的训练数据,但你自己没意识到。
人工数据合成确实有效。在语音识别中。我已经看到人工数据合成显著提升了已经非常好的语音识别系统的表现,所以这是可行的。但当你使用人工数据合成时,一定要谨慎,要记住你有可能从所有可能性的空间只选了很小一部分去模拟数据。
吴教主深度学习和神经网络课程总纲