OpenCV-Python——第29章:ORB(Oriented FAST and Rotated BRIEF)特征检测算法
目录
0 原理 1 OpenCV中的BRIEF 2 OpenCV中的ORB算法
特征点检测完之后的匹配可以参考:https://blog.csdn.net/yukinoai/article/details/89055860
0 原理
对于一个 OpenCV 的狂热爱好者来说 ORB 最重要的一点就是:它来自“OpenCV_Labs''。这个算法是在 2011 年提出的。在计算开支,匹配效率以 及更主要的是专利问题方面 ORB 算法是是 SIFT 和 SURF 算法的一个很好的 替代品。SIFT 和 SURF 算法是有专利保护的,如果你要使用它们,就可能要花钱。但是 ORB 不需要!!!
ORB 基本是 FAST 关键点检测和 BRIEF 关键点描述器的结合体,并通过很多修改增强了性能。首先它使用 FAST 找到关键点,然后再使用 Harris 角点检测对这些关键点进行排序找到其中的前 N 个点。它也使用金字塔从而产 生尺度不变性特征。但是有一个问题,FAST 算法步计算方向。那旋转不变性 怎样解决呢?作者进行了如下修改。
增加旋转不变性的:
ORB算法计算了以当前角点为中心所在区域的强度加权质心。那么,当前角点的方向向量就是由这个角点指向这个质心的方向。为了提高旋转不变性,还计算了以角点为圆心,半径大小为r的区域的矩(moments),坐标为x,y。
对于描述符,ORB算法使用了BRIEF算法的描述符。但是我们早就了解了BRIEF的描述符在旋转的图像下表现很差劲。所以,ORB根据特征点的方向使用了一种“可控BRIEF”描述符。对于任意特征集,例如在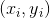 点的二进制检测,定义一个2×n的矩阵S,里面有n个之前找到的特征点,借用之前计算得到的角度,利用旋转矩阵来旋转矩阵S得到
点的二进制检测,定义一个2×n的矩阵S,里面有n个之前找到的特征点,借用之前计算得到的角度,利用旋转矩阵来旋转矩阵S得到![]() ,这样就得到了可控的BRIEF描述符。
,这样就得到了可控的BRIEF描述符。
ORB算法将角度离散化为增量12度一个单位的角度,然后构造一个预先计算BRIEF模式的查找表。只要特征点的方向θθ始终一致,那么正确的特征点的集合![]() 就会用来计算描述符。
就会用来计算描述符。
特征点匹配:BRIEF
BRIEF简介:
我们知道 SIFT 算法使用的是 128 维的描述符。由于它是使用的浮点数,所以要使用 512 个字节。同样 SURF 算法最少使用 256 个字节(64 维描述符)。创建一个包含上千个特征的向量需要消耗大量的内存,在嵌入式等资源 有限的设备上这样是合适的。匹配时还会消耗更多的内存和时间。
但是在实际的匹配过程中如此多的维度是没有必要的。我们可以使用PCA,LDA 等方法来进行降维。甚至可以使用 LSH(局部敏感哈希)将 SIFT 浮点 数的描述符转换成二进制字符串。对这些字符串再使用汉明距离进行匹配。汉 明距离的计算只需要进行 XOR 位运算以及位计数,这种计算很适合在现代的 CPU 上进行。但我们还是要先找到描述符才能使用哈希,这不能解决最初的内存消耗问题。
BRIEF 应运而生。它不去计算描述符而是直接找到一个二进制字符串。这种算法使用的是已经平滑后的图像,它会按照一种特定的方式选取一组像素点 对![]() ,然后在这些像素点对之间进行灰度值对比。例如,第一个点对的灰度值分别为 p 和 q。如果 p 小于 q,结果就是 1,否则就是 0。就这样对
,然后在这些像素点对之间进行灰度值对比。例如,第一个点对的灰度值分别为 p 和 q。如果 p 小于 q,结果就是 1,否则就是 0。就这样对![]() 个点对进行对比得到一个
个点对进行对比得到一个 ![]() 维的二进制字符串。
维的二进制字符串。
![]() 可以是 128,256,512。OpenCV 对这些都提供了支持,但在默认情况下是 256(OpenCV是使用字节表示它们的,所以这些值分别对应与 16, 32,64)。当我们获得这些二进制字符串之后就可以使用汉明距离对它们进行匹配了。
可以是 128,256,512。OpenCV 对这些都提供了支持,但在默认情况下是 256(OpenCV是使用字节表示它们的,所以这些值分别对应与 16, 32,64)。当我们获得这些二进制字符串之后就可以使用汉明距离对它们进行匹配了。
非常重要的一点是:BRIEF 是一种特征描述符,它不提供查找特征的方法。 所以我们不得不使用其他特征检测器,比如 SIFT 和 SURF 等。原始文献推荐使用 CenSurE 特征检测器(在OpenCV中称为STAR检测器),这种算法很快。而且 BRIEF 算法对 CenSurE 关键点的描述效果要比 SURF 关键点的描述更好。 简单来说 BRIEF 是一种对特征点描述符计算和匹配的快速方法。这种算 法可以实现很高的识别率,除非出现平面内的大旋转。
BRIEF算法有一个重要的性质就是每一位的特征都有很大的差异,并且差异大小的均值接近0.5。但是一旦它的方向沿着特征点的方向,它就会去掉了这个差异,并且变得更加分散。方差变大使得特征变得更加容易区分,因为它接受了不同的输入。另外一个让人满意的性质是让测试都不相关,因为这样每个测试都会贡献出影响。为了解决上面的问题,ORB使用了一个贪心搜索侧率,在所有可能的二进制测试当中去找到的一个拥有方差值高并且均值接近0.5的特征点,而且是不相关的。这个方法叫做rBRIEF算法。
对于描述符匹配,多探测局部敏感哈希(multi-probe LSH)在传统的LSH算法上有所用提高,并使用在描述符配的算法当中。论文中指出,ORB算法比SURF和SIFT算法更快速,并且ORB描述符的效果比SURF更高。ORB在低功耗设备上是一个不错的选择。
1 OpenCV中的BRIEF
创建BRIEF描述符:
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(, bytes, use_orientation)
- bytes:描述符中
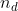 的值,用字节表示可取16, 32 (default) or 64,代表的值为 128,256,512
的值,用字节表示可取16, 32 (default) or 64,代表的值为 128,256,512 - use_orientation:使用特征点方向的示例模式,默认情况下禁用。
创建 CenSurE 特征检测器(在OpenCV中称为STAR检测器):
star = cv2.xfeatures2d.StarDetector_create(, maxSize, responseThreshold, lineThresholdProjected, lineThresholdBinarized, suppressNonmaxSize)
- maxSize:最大尺寸,默认45
- responseThreshold:响应阈值,默认30
- lineThresholdProjected:线性投影阈值,默认10
- lineThresholdBinarized:线性二值化阈值,默认8
- suppressNonmaxSize:非极大抑制参数,默认5
计算在图像中检测到的一组特征点的描述符:
keypoints, descriptors = brief.compute(image, keypoints)
- image:输入图像
- keypoints:输入特征点集合。无法计算描述符的特征点将被删除。有时可以添加新的特征点,例如:SIFT具有多个主导方向的重复特征点(对于每个方向)。
- descriptors:输出计算后的描述符,是一个矩阵,文档原文有点不懂,In the second variant of the method descriptors[i] are descriptors computed for a keypoints[i]. Row j is the keypoints (or keypoints[i]) is the descriptor for keypoint j-th keypoint.
举个小例子:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('test30.jpg', 0)
plt.subplot(131), plt.imshow(img, cmap='gray'),
plt.title('Origianl'), plt.axis('off')
# STAR检测器
star = cv2.xfeatures2d.StarDetector_create()
# BRIEF抽取器
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create()
# find the keypoints with STAR
kp = star.detect(img, None)
img2 = cv2.drawKeypoints(img, kp, None, color=(255, 0, 0))
plt.subplot(132), plt.imshow(img2, cmap='gray'),
plt.title('STAR'), plt.axis('off')
# 使用BRIEF计算描述符
kp1, des = brief.compute(img, kp)
img3 = cv2.drawKeypoints(img, kp1, None, color=(255, 0, 0))
plt.subplot(133), plt.imshow(img3, cmap='gray'),
plt.title('BRIEF'), plt.axis('off')
plt.show()
# 打印BRIEF尺寸
print(brief.descriptorSize())
# 打印计算后输出符的尺寸
print(des.shape)
2 OpenCV中的ORB算法
创建一个ORB对象:
orb = cv2.ORB_create(, nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType, patchSize, fastThreshold)
- nfeatures:要保留的特征的最大数量,默认500
- scaleFactor:金字塔抽取比,大于1,默认1.2。scaleFactor==2表示经典金字塔,每一层的像素都比上一层少4倍,但如此大的尺度因子会显著降低特征匹配得分。另一方面,过于接近1的比例因素将意味着要覆盖一定的比例范围,你将需要更多的金字塔级别,因此速度将受到影响。
- nlevels:金字塔层数,默认8。最小级别的线性大小将等于input_image_linear_size/pow(scaleFactor, nlevels - firstLevel)。
- edgeThreshold:边框阈值,这是未检测到特征的边框尺寸,默认31。它应该大致匹配patchSize参数。
- firstLevel:将源图像放置到的金字塔级别,默认0。之前的图层都是放大的源图像。
- WTA_K:产生面向对象的BRIEF描述符的每个元素的点的数量。默认值2表示取一个随机点对并比较它们的亮度,得到0/1响应。其他可能的值是3和4。例如,意味着我们需要3随机点(当然,这些点坐标是随机的,但它们产生的预定义的种子,所以每个元素的简短描述符计算确定性像素矩形),找到的赢家的最大亮度和产出指数(0、1或2)。这样的输出会占据2位,因此它需要汉明距离的一种特殊变体,指示为NORM_HAMMING2(2位/ bin)。当WTA_K=4时,我们取4个随机点来计算每个bin(它也将占用2位,可能值为0、1、2或3)。
- scoreType:默认的HARRIS_SCORE表示使用Harris算法对特征进行排序(分数写为KeyPoint::score,用于保留最佳nfeatures特征);FAST_SCORE是参数的替代值,该参数生成的键值稍微不太稳定,但是计算起来要快一些。
- patchSize:面向对象的BRIEF描述符使用的矩阵的大小,默认31。当然,在较小的金字塔层上,特征所覆盖的感知图像区域会更大。
- fastThreshold:FAST特征检测器阈值,默认20
可以使用类似于orb.getScoreType(),orb.setScoreType(ScoreType)查看和更改参数,具体可查看官网:
https://docs.opencv.org/master/db/d95/classcv_1_1ORB.html
最后举一个例子:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('test30.jpg', 0)
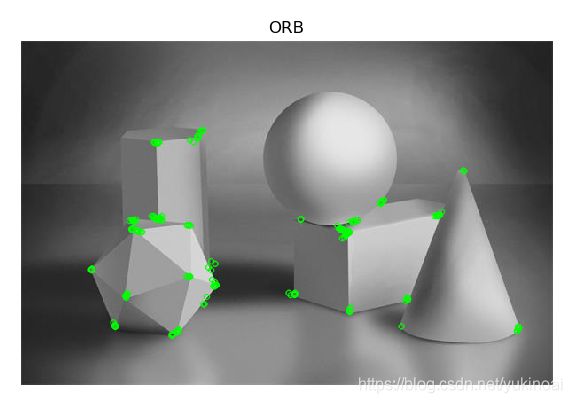
# 创建ORB,由于图比较简单,所以设置的关键点数较小,默认500
orb = cv2.ORB_create(nfeatures=200)
# 使用ORB检测特征点
kp = orb.detect(img, None)
# compute the descriptors with ORB
kp, des = orb.compute(img, kp)
# 绘制特征点
img2 = cv2.drawKeypoints(img, kp, None, color=(0, 255, 0), flags=0)
plt.imshow(img2, cmap='gray'), plt.title('ORB'), plt.axis('off')
plt.show()结果如下,可以看出所有角点基本都被检测出来了。