YOLOv2学习笔记
YOLOv2的改进:
1.Batch Normalization(批量归一化)
批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。
2.High resolution classifier(高分辨率图像分类器)
图像分类的训练样本很多,而标注了边框的用于训练对象检测的样本相比而言就比较少了,因为标注边框的人工成本比较高。所以对象检测模型通常都先用图像分类样本训练卷积层,提取图像特征。但这引出的另一个问题是,图像分类样本的分辨率不是很高。所以YOLO v1使用ImageNet的图像分类样本采用 224*224 作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448*448 的图像作为输入。但这样切换对模型性能有一定影响。
所以YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
3.Convolution with anchor boxes(使用先验框)
YOLO使用卷积特征提取器顶部的全连接层直接预测边界框的坐标。与直接预测坐标不同,Faster R-CNN使用先验框预测边界框的速度更快。仅使用卷积层,Faster R-CNN中的区域建议网络(RPN)预测锚箱的偏移量和置信度。由于预测层是卷积的,所以RPN在特征图中的每个位置预测这些偏移。预测偏移量而不是坐标简化了问题,使网络更容易学习。
我们从YOLO中移除全连接层,并使用锚定框来预测边界框。首先,我们消除一个池化层,以使网络卷积层的输出具有更高的分辨率。我们还将网络缩小到416个输入图像,而不是448×448。我们这样做是因为我们希望在特征图中有奇数个位置,所以只有一个中心单元。对象,尤其是大型对象,往往占据图像的中心,因此最好在中心有一个位置来预测这些对象,而不是四个位置都在附近。YOLO的卷积层将图像向下采样32倍,因此通过使用416的输入图像,我们得到13×13的输出特征图。
使用锚箱,我们得到了一个小的精度下降。YOLO只预测每张图片有98个盒子,但我们的模型预测的锚盒超过1000个。YOLO2如果每个grid采用9个先验框,总共有13*13*9=1521个先验框。如果没有锚箱,我们的中间车型的mAP为69.5,召回率为81%。使用锚箱,我们的模型得到69.2 mAP,召回率为88%。尽管mAP下降了,但召回率的增加意味着我们的模型还有更多的改进空间。
4.Dimension clusters(聚类提取先验框的尺度信息)
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。 YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行K-mean聚类分析,以寻找尽可能匹配样本的边框尺寸。
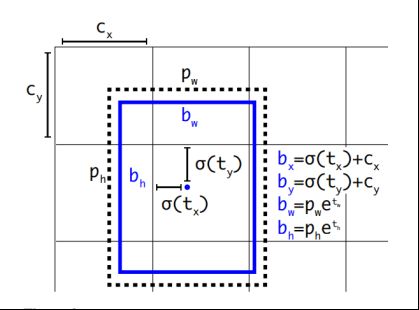
5.Direct location prediction(约束预测边框的位置)
借鉴于Faster RCNN的先验框方法,在训练的早期阶段,其位置预测容易不稳定。其位置预测公式为:
6.Fine-Grained Features(passthrough层检测细粒度特征)
这种改进的YOLO预测13×13特征图上的检测。虽然这对于大型对象来说已经足够了,但它可能会受益于用于定位较小对象的细粒度特性。更快的R-CNN和SSD都在网络中的不同功能地图上运行他们的提案网络,以获得一系列分辨率。我们采用了一种不同的方法,只需添加一个直通层,以26×26的分辨率提供早期层的特征。与ResNet中的标识映射类似,通过将相邻特征堆叠到不同通道(而不是空间位置)来连接高分辨率特征和低分辨率特征。 将26×26×512要素图转换为13×13×2048要素图,可与原始要素连接。我们的检测器运行在这个扩展的特征映射之上,因此它可以访问细粒度特征。这将使性能略微提高1%。
7.Multi-ScaleTraining(多尺度图像训练)
作者希望YOLO v2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。区别于之前的补全图片的尺寸的方法,YOLO v2每迭代几次都会改变网络参数。每10个Batches,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320*320,最大608*608,网络会自动改变尺寸,并继续训练的过程。这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在YOLO v2的速度和精度上进行权衡。
8.Darknet-19(backbone网络)
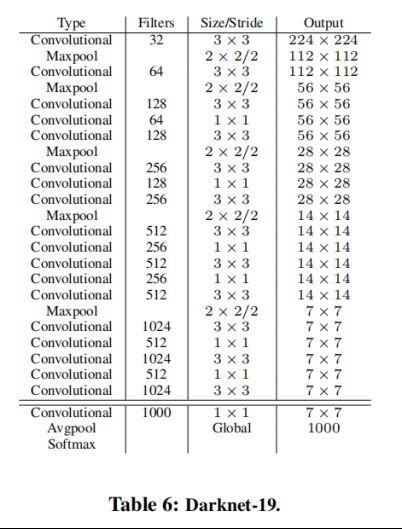
Darknet-19仅需55.8亿次操作即可处理图像,但在ImageNet上可实现72.9%的top-1精度和91.2%的top-5精度。
9.Hierarchical classification(分层分类)
作者提出了一种在分类数据集和检测数据集上联合训练的机制。使用检测数据集的图片去学习检测相关的信息,例如bounding boxes 坐标预测,是否包含物体以及属于各个物体的概率。使用仅有类别标签的分类数据集图片去扩展可以检测的种类。通过ImageNet训练分类、COCO和VOC数据集来训练检测,这是一个很有价值的思路,可以让我们达到比较优的效果。通过将两个数据集混合训练,如果遇到来自分类集的图片则只计算分类的Loss,遇到来自检测集的图片则计算完整的Loss。