深度学习卷积算法指南
convolution arithmetic介绍
- 1 简介
-
- 1.1 离散卷积
- 1.2 池化
- 1.3 卷积算法相关词汇
-
-
- 卷积核
- 步长(Stride)
- 填充(padding)
- 通道(chennel)
- Feature Map是什么
-
- 2 卷积算法
-
- 2.1 无零填充,单位跨度
- 2.2 零填充,单位跨度
-
- 2.2.1 一半(相同)的填充
- 2.2.2 完全填充
- 2.3 无零填充,无步幅
- 2.4零填充,非跨步
- 3 池化算术
- 4 转置卷积算法
-
- 4.1 卷积作为矩阵运算
- 4.2 转置卷积
- 4.3 无零填充,单位跨度,转置
- 4.4 零填充,单位跨度,转置
-
- 4.4.1一半(相同)的填充,转置
- 4.4.2 完整填充,转置
- 4.5 没有零填充,非跨步,已转置
- 4.6 零填充,非跨步,已转置
- 5 其他卷积
-
- 5.1扩展卷积
1 简介
深度卷积神经网络(CNN)一直是深度学习惊人发展的核心。尽管CNN早在90年代就已用于解决字符识别任务(Le Cun等,1997),但它们的当前广泛应用是由于最近的工作,当时使用了深层的CNN击败了现状。 ImageNet图像分类挑战中的先进技术(Krizhevsky等,2012)。因此,卷积神经网络构成了机器学习从业者非常有用的工具。但是,第一次学习使用CNN通常是一种令人生畏的经历。
卷积层的输出形状受其输入形状以及卷积核形状,零填充和步幅的选择的影响,并且这些属性之间的关系也不容易推断。这与完全连接的层形成对比,后者的输出大小与输入大小无关。此外,CNN通常还具有池化阶段,相对于完全连接的网络,又增加了另一层次的复杂性。
最后,所谓的转置卷积层(也称为分数卷积卷积层)最近已经进行了越来越多的工作((Bergstraet al.,2010;Bastienet al.,2012),Torch (Collobert et al., 2011), Tensorflow (Abadi et al., 2015) and Caffe (Jia et al., 2014)),以及它们与卷积层之间的关系已经以不同的清晰度进行了解释。本指南的目标是双重的:
1.解释卷积层和转置的卷积层之间的关系。
2.对卷积,池化和转置卷积层中的输入形状,卷积核形状,零填充,步幅和输出形状之间的关系提供直观的了解。
为了保持广泛的适用性,本指南中显示的结果与实现细节无关,并且适用于所有常用的机器学习框架,例如Theano(Bergstraet al.,2010;Bastienet al.,2012),Torch (Collobert et al., 2011), Tensorflow (Abadi et al., 2015) and Caffe (Jia et al., 2014).
本章简述了CNN的主要组成部分,即离散卷积和池化。 有关此主题的深入处理,请参阅《深度学习》教科书的第9章 (Goodfellow et al., 2016).
1.1 离散卷积
神经网络的基本原理就是转换:将向量作为输入接收,并与矩阵相乘以产生输出(通常在将结果传递给非线性之前对其添加偏置向量)。这适用于任何类型的输入,无论是图像,声音剪辑还是特征的无序集合:无论它们的维数如何,在转换之前总是可以将它们的表示形式平化为矢量。图像,声音片段和许多其他类似的数据具有固有的结构。
更正式地讲,它们共享以下重要属性:
•它们存储为多维数组。
•它们具有一个或多个需要排序的轴(例如,图像的宽度和高度轴,声音剪辑的时间轴)。
•一个轴称为通道轴,用于访问数据的不同视图(例如,彩色图像的红色,绿色和蓝色通道,或立体声音频轨道的左右通道)。
应用仿射转换时不会利用这些属性。实际上,所有轴都以相同的方式处理,并且不考虑拓扑信息。尽管如此,利用数据的隐式结构在解决某些任务(如计算机视觉和语音识别)方面可能非常方便,在这种情况下,最好将其保存下来。这就是离散卷积起作用的地方。
离散卷积是一种线性变换,可以保留这种有序的概念。它是稀疏的(只有少数输入单元构成给定的输出单元),并且会重用参数(将相同的权重应用于输入中的多个位置)。
图1.1提供了离散卷积的示例。浅蓝色网格称为输入要素图。为了使图形保持简单,只表示一个输入要素图,但是将多个要素图相互堆叠并不罕见。一个卷积核的值(阴影区域)在输入feature map上滑动。



在每个位置,卷积核的每个元素与其重叠的输入元素之间的乘积,并对结果求和,以获取当前位置的输出。该过程可以根据需要使用其他不同的卷积核来构成许多输出功能图(图1.3)。此过程的最终输出称为输出 feature maps。2如果存在多个输入 feature maps,则卷积核必须是3维的-或等效地,每个 feature maps都将与一个不同的卷积核进行卷积-并且生成的 feature maps将按元素进行求和,以生成输出 feature maps。图1.1中描述的卷积是2-D卷积的一个实例,但是可以将其推广为N-D卷积。例如,在3-D卷积中,卷积核将是长方体,并且会在输入要素图的高度,宽度和深度上滑动。定义离散卷积的卷积核集合的形状对应于(n,m,k1,…,kN)的某些置换,其中

n个输出 feature maps的数量,m个输入 feature maps的数量,kj沿轴j的卷积核大小。
以下属性会影响沿j轴的卷积层的输出大小oj:
•ij:沿j轴的输入大小,
•kj:沿j轴的卷积核大小,
•sj:沿轴的步幅(卷积核两个连续位置之间的距离) j,
•pj:沿轴j的零填充(在轴的起点和末端连接的零数)。
例如,图1.2显示了一个3×3卷积核,该卷积核使用2×2步幅应用于填充有1×1零边界的5×5输入。
注意,步幅构成了二次采样的一种形式。作为解释为多少卷积核被翻译的度量的替代方法,也可以将步幅视为保留了多少输出。例如,将卷积核移动2跳等效于将卷积核移动1跳,但仅保留奇数输出元素(图1.4)。



1.2 池化
除了离散卷积本身之外,池化操作还构成了CNN中的另一个重要组成部分。 池化操作通过使用某些功能来汇总子区域(例如取平均值或最大值)来减小要素图的大小。
通过在输入上滑动窗口并将窗口的内容提供给池化功能来进行池化。 从某种意义上讲,池的工作方式非常类似于离散卷积,但是用其他函数代替了卷积核描述的线性组合。 图1.5提供了平均池化的示例,图1.6提供了最大池化的示例。
以下属性会影响沿j轴的合并层的输出大小oj:
•ij:沿j轴的输入大小,
•kj:沿j轴的合并窗口大小,
•sj:跨度(合并窗口的两个连续位置之间的距离) 沿轴j。


1.3 卷积算法相关词汇
卷积核
用不同的滤波器对图像进行卷积,可以通过应用滤波器进行边缘检测、模糊和锐化等操作。不同类型的过滤器(卷积核)后的各种卷积图像处理提取不同的特征。
步长(Stride)
决定滑动多少步可以到边缘 ;
填充(padding)
填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
通道(chennel)
输入图像是几波段的数据;

解析:图中input 773中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道,可以看到周边有填充0; 有两个卷积核Filter w0、Filter w1,每个filter对应每个通道有一组w权重;一个filter滑动到一个位置后计算三个通道的卷积,求和,加bias,得到这个filter在该位置的最终结果;每个filter的输出是各个通道的汇总;输出的个数与filter个数相同。所以最右边能得到两个不同的输出。
1的计算过程:
第一个通道和对应权重的结果:01+01+0*(-1)+0*(-1)+00+11+0*(-1)+0*(-1)+1*0 = 1
第二个通道和对应权重的结果:0*(-1)+00+0(-1)+00+10+1*(-1)+01+0(-1)+2*0 = -1
第三个通道和对应权重的结果:00+01+00+01+20+01+00+0(-1)+0*0 = 0
偏置:1
1+(-1)+ 0 + 1 = 1
Feature Map是什么
在CNN的设定里,Feature Map是卷积核卷出来的,你用各种情况下的卷积核去乘以原图,会得到各种各样的feature map。你可以理解为你从多个角度去分析图片。,而不同的特征提取(核)会提取不同的feature,模型想要达成的目的是解一个最优化,来找到能解释现象的最佳的一组卷积核。
举例:
同一层:
Fliter1 的w1,b1 运算后提取的是 形状边缘的特征: feature map1
Fliter2 的w2,b2 运算后提取的是 颜色深浅的特征: feature map2
下一层:
Fliter3 的w3,b3 运算后提取的是 直线形状的特征: feature map3
Fliter4 的w4,b4 运算后提取的是 弧线形状的特征: feature map4
Fliter5 的w5,b5 运算后提取的是 红色深浅的特征: feature map5
Fliter6 的w6,b6 运算后提取的是 绿色深浅的特征: feature map6
同一个卷积层中的 Feature Map有什么区别?
在卷积神经网络中,我们希望用一个网络模拟视觉通路的特性,分层的概念是自底向上构造简单到复杂的神经元。楼主关心的是同一层,那就说说同一层。
我们希望构造一组基,这组基能够形成对于一个事物完备的描述,例如描述一个人时我们通过描述身高/体重/相貌等,在卷积网中也是如此。在同一层,我们希望得到对于一张图片多种角度的描述,具体来讲就是用多种不同的卷积核对图像进行卷,得到不同核(这里的核可以理解为描述)上的响应,作为图像的特征。他们的联系在于形成图像在同一层次不同基上的描述。下层的核主要是一些简单的边缘检测器(也可以理解为生理学上的simple cell)。
在每个卷积层,数据都是以三维形式存在的。你可以把它看成许多个二维图片叠在一起,其中每一个称为一个feature map。在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。层与层之间会有若干个卷积核(kernel),上一层和每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map。
2 卷积算法
卷积是从输入图像中提取特征的第一层。它是一个数学运算,需要两个输入,如图像矩阵和一个滤波器(或核)。这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,得到这些小区域的特征值,从而保持像素之间的关系。
卷积层是CNN的核心,层的参数由一组可学习 的滤波器(filter)或卷积核(kernels)组成 ,它们具有小的感受野,延伸到输入容积的整个深度。 在前馈期间,每个滤波器对输入进行卷积,计算滤波器和输入之间的点积,并产生该滤波器的二维激活图(输入一般二维向量,但可能有高度(即RGB))。 简单来说,卷积层是用来对输入层进行卷积,提取更高层次的特征。
卷积层属性不跨轴交互的事实使对卷积层属性之间关系的分析变得容易,即沿轴j的卷积核大小,步幅和零填充的选择只会影响轴j的输出大小。
因此,本章将重点介绍以下简化的设置:
•二维离散卷积(N = 2),
•平方输入(i1 = i2 = i),
•平方核大小(k1 = k2 = k),
• 沿两个轴具有相同的步幅(s1 = s2 = s),
•沿两个轴具有相同的零填充(p1 = p2 = p)。
这有助于进行分析和可视化,但请记住,此处概述的结果也适用于N-D和非正方形情况。
2.1 无零填充,单位跨度
最简单的分析情况是内核何时在输入的每个位置上滑动(即s = 1和p = 0)。 图2.1提供了i = 4和k = 3的示例。在这种情况下,定义输出大小的一种方法是通过内核在输入上的可能放置数。 让我们考虑一下宽度轴:内核从输入要素图的最左侧开始,以1的步长滑动,直到它接触到输入的右侧。 输出的大小将等于执行的步骤数加一,说明内核的初始位置(图2.8a)。 高度轴也适用相同的逻辑。 更正式地说,可以推断出以下关系:



2.2 零填充,单位跨度
要考虑零填充(即仅限制为s = 1),请考虑其对有效输入大小的影响:用p零填充将有效输入大小从i更改为i + 2p。 在一般情况下,关系1可用于推断以下关系:

图2.2提供了一个i = 5,k = 4和p = 2的示例。实际上,由于零填充的两个特定实例各自的属性,它们被广泛使用。 让我们更详细地讨论它们。


2.2.1 一半(相同)的填充
使输出大小与输入大小相同(即o = i)可能是理想的属性:



2.2.2 完全填充
虽然对内核进行卷积通常会相对于输入大小减小输出大小,但有时需要相反的操作。 这可以通过适当的零填充来实现:



有时将其称为完全填充,因为在此设置中,考虑了内核在输入要素图上的每个可能的部分或完全叠加。 图2.4提供了i = 5,k = 3和(因此)p = 2的示例。
2.3 无零填充,无步幅
到目前为止导出的所有关系仅适用于单位跨步卷积。 合并非单一的跨度需要另一个推理飞跃。 为了便于分析,我们暂时忽略零填充(即s> 1和p = 0)。 图2.5提供了一个i = 5,k = 3和s = 2的示例。再一次,可以根据内核在输入上的可能放置数量来定义输出大小。 让我们考虑一下宽度轴:内核像往常一样在输入的最左边部分启动,但是这次它以大小s的步长滑动,直到它接触到输入的右边。 输出的大小再次等于完成的步数,再加上一步,说明内核的初始位置(图2.8b)。 高度轴也适用相同的逻辑。 由此,可以推断出以下关系:

地板函数解释了这样一个事实:有时最后一个可能的步骤与内核到达输入末尾的时间不一致,即,省略了一些输入单元(这种情况的示例请参见图2.7)。

2.4零填充,非跨步
可以通过将关系5应用于大小为i + 2p的有效输入来推导最一般的情况(使用非单位跨度对零填充输入进行卷积),类似于对关系2所做的操作:

如前所述,逻辑函数意味着在某些情况下卷积将为多个输入大小生成相同的输出大小。 更具体地说,如果i + 2p-k是s的倍数,则任何输入大小j = i + a,a∈{0,…,s-1}将产生相同的输出大小。 请注意,这种歧义仅适用于s>1。


图2.6显示了i = 5,k = 3,s = 2和p = 1的示例,而图2.7提供了i = 6,k = 3,s = 1的示例。 2和p =1。有趣的是,尽管卷积具有不同的输入大小,但这些卷积共享相同的输出大小。 虽然这不会影响卷积的分析,但在转置卷积的情况下会使分析复杂化。



3 池化算术
在神经网络中,池化层为输入的小的转换提供了不变性。 最常见的池化是最大池化( max pooling),它包括将输入分成(通常是非重叠的)补丁,并输出每个补丁的最大值。 存在其他类型的合并,例如均值或平均合并,它们都具有通过对某些补丁的内容应用非线性来局部汇总输入的相同思想 (Boureau et al., 2010a,b, 2011; Saxe et al., 2011).
一些读者可能已经注意到,卷积算法的处理仅依赖于某些功能被重复应用于输入子集的假设。 这意味着在合并算法的情况下,可以重用上一章中推导的关系。 由于合并不涉及零填充,因此描述一般情况的关系如下:
此关系适用于任何类型的池。
4 转置卷积算法
转置卷积的需求通常是由于希望沿正常卷积的相反方向使用转换,即,从具有某种卷积输出形状的东西到具有其输入形状同时保持与所述卷积兼容的连通性模式的东西。例如,可以使用这种转换作为卷积自动编码器的解码层,或将特征映射投影到更高维度的空间。
再一次,卷积的情况比完全连接的情况要复杂得多,完全连接的情况只需要使用重量矩阵已转置的形状即可。但是,由于每次卷积都归结为矩阵运算的有效实现,因此从完全连通的情况中获得的见解对于解决卷积情况很有用。
像卷积算法一样,关于转置卷积算法的论述也简化了,即转置卷积属性不会跨轴交互。
本章将重点介绍以下设置:
• 2-D transposed convolutions (N = 2),
• square inputs (i1 = i2 = i),
• square kernel size (k1 = k2 = k),
• same strides along both axes (s1 = s2 = s),
• same zero padding along both axes (p1 = p2 = p).
再次,概述的结果概括了N-D和非正方形的情况。
4.1 卷积作为矩阵运算
以图2.1中所示的卷积为例。 如果要从左到右,从上到下将输入和输出展开为向量,则卷积可以表示为稀疏矩阵C,其中非零元素是卷积核的wi,j元素(其中i和j 分别是卷积核的行和列):

4.2 转置卷积
现在,让我们考虑一下需要采取的另一种方法,即从4维空间映射到16维空间,同时保持图2.1所示的卷积连接模式。
此操作称为转置卷积。转置卷积(也称为分数跨卷积或解卷积1)通过交换卷积的前进和后退路径来工作。一种表达方式是注意卷积核定义了卷积,但是它是直接卷积还是转置卷积取决于如何计算正向和反向遍历。
例如,尽管卷积核w定义了通过分别乘以C和CT来计算正向和反向通过的卷积,但是它还定义了通过分别乘以CT和(CT)T = C来计算其正向和反向通过的转置卷积.
最后,请注意,始终可以用直接卷积来模拟转置卷积。缺点是它通常涉及将许多零列和零行添加到输入中,从而导致实现效率低得多。
在到目前为止所介绍的内容的基础上,本章将在卷积算术章节的基础上进行一些后退,通过引用与卷积核共享的直接卷积来推导每个转置卷积的性质,并定义等效的直接卷积。
4.3 无零填充,单位跨度,转置
考虑给定输入上的转置卷积的最简单方法是将这样的输入想象为是应用于某些初始特征图的直接卷积的结果。然后可以将转置的卷积视为允许恢复此初始特征图的形状3的操作。
让我们考虑3×3卷积核在4×4输入上的卷积,步长为单一且无填充(即,i = 4,k = 3,s = 1和p = 0)。如图2.1所示,这将产生2×2的输出。当应用于2×2输入时,此卷积的转置将具有4×4形状的输出。获得转置卷积结果的另一种方法是应用等效的但效率不高的直接卷积。
到目前为止所描述的示例可以通过使用步幅(即i0 = 2,k0 = k,s0 = 1和p0 = 2),如图4.1所示。值得注意的是,卷积核和步幅的大小保持不变,但是转置卷积的输入现在为零填充。4了解零填充背后逻辑的一种方法是考虑转置卷积的连通性模式并用其指导设计等价卷积例如,直接卷积的输入的左上像素仅对输出的左上像素起作用,右上像素仅与右上输出像素相连,依此类推。为了在等效卷积中保持相同的连通性模式,必须对输入进行零填充,以使卷积核的第一个(左上)应用程序仅触摸左上像素,即,填充必须相等减去卷积核大小减一。以相同的方式进行操作,有可能确定其他元素软化的相似观察结果,从而产生以下关系:

有趣的是,这对应于带有单位步幅的完全填充卷积。
4.4 零填充,单位跨度,转置
知道非填充卷积的转置等效于对零填充输入进行卷积,因此合理地假设零填充卷积的转置等效于对具有较少零的填充输入进行卷积。 确实如此,如图4.2所示,i = 5,k = 4,p =2。形式上,以下关系适用于零填充卷积:



4.4.1一半(相同)的填充,转置
通过应用与以前相同的归纳推理,可以合理地预期半填充卷积的转置的等效卷积本身就是半填充卷积,因为半填充卷积的输出大小与其输入大小相同 。 因此,以下关系适用:


4.4.2 完整填充,转置
知道未填充卷积的转置的等效卷积涉及完全填充,因此完全填充卷积的转置的等效项是未填充卷积就不足为奇了:

4.5 没有零填充,非跨步,已转置
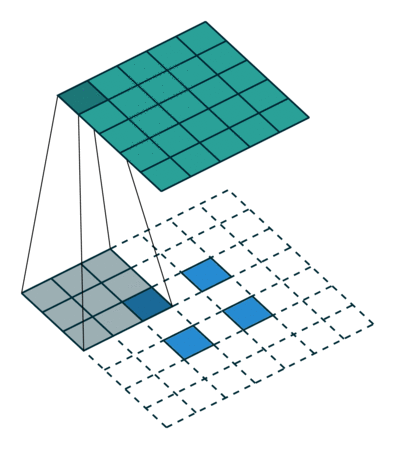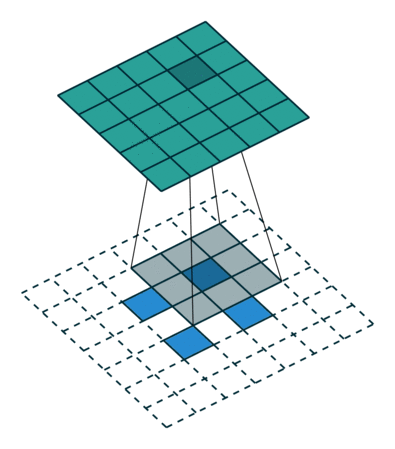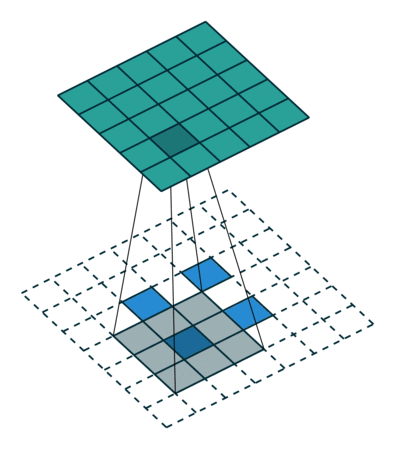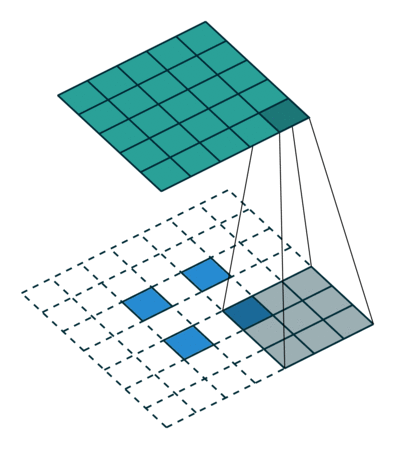
使用与零填充卷积相同的归纳逻辑,可能会期望s> 1的卷积的转置包含s <1的等效卷积。如将说明的那样,这是一个有效的直觉,这就是为什么转置的原因 卷积有时也称为分数跨步卷积。 图4.5提供了一个i = 5,k = 3和s = 2的示例,它有助于理解分数跨度:在输入单元之间插入零,这使内核以比单元跨度慢的速度运动。5 此时,将假定卷积未填充(p = 0),并且其输入大小i为,因此ik是s的倍数。 在这种情况下,以下关系成立:


4.6 零填充,非跨步,已转置
当卷积的输入大小i为i + 2p-k为s的倍数时,可以通过将关系9和关系12结合起来,将分析扩展到零填充情况:






5 其他卷积
5.1扩展卷积
熟悉深度学习文献的读者可能已经注意到术语“膨胀卷积”(或“ atrous卷积”,源于法语表达卷积)。在这里,我们尝试提供对扩张卷积的直观理解。有关更深入的描述并了解它们在什么情况下应用,请参见Chen等。 (2014); Yu和Koltun(2015)。膨胀卷积通过在内核元素之间插入空格来“填充”内核。膨胀“速率”由附加超参数d控制。可以在内核元素之间插入但通常以d-1间隔进行实现,以使d = 1对应于规则卷积。在不增加内核大小的情况下,将扩张卷积廉价地用于增加输出单位的可接受范围,这在多个扩张卷积一个接一个地堆叠时尤其有效。有关具体示例,请参见Oord等。 (2016),其中提出的WaveNet模型为原始音频实现了自动回归生成模型,该模型使用膨胀卷积在过去音频帧的大背景下调节新音频帧。为了理解与膨胀率d和输出大小o的关系,考虑d对有效内核大小的影响是有用的。大小为k且被因子d放大的核的有效大小


5.1扩展卷积
熟悉深度学习文献的读者可能已经注意到术语“膨胀卷积”(或“ atrous卷积”,源于法语表达卷积)。在这里,我们尝试提供对扩张卷积的直观理解。有关更深入的描述并了解它们在什么情况下应用,请参见Chen等。 (2014); Yu和Koltun(2015)。膨胀卷积通过在卷积核元素之间插入空格来“填充”卷积核。膨胀“速率”由附加超参数d控制。可以在卷积核元素之间插入但通常以d-1间隔进行实现,以使d = 1对应于规则卷积。在不增加卷积核大小的情况下,将扩张卷积廉价地用于增加输出单位的可接受范围,这在多个扩张卷积一个接一个地堆叠时尤其有效。有关具体示例,请参见Oord等。 (2016),其中提出的WaveNet模型为原始音频实现了自动回归生成模型,该模型使用膨胀卷积在过去音频帧的大背景下调节新音频帧。为了理解与膨胀率d和输出大小o的关系,考虑d对有效卷积核大小的影响是有用的。大小为k且被因子d放大的核的有效大小
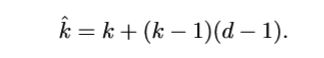
可以将其与关系6结合起来以形成用于膨胀卷积的以下关系:



本章节,是按官方帮助的英文翻译而来,其中有些是直接翻译,有些是加入自己的理解,希望大家对卷积有个直观的了解。如果理解有错误的地方,希望大家及时指正,也方便大家一起学习。
参考:
如何理解CNN中的卷积?: https://blog.csdn.net/cheneykl/article/details/79740810
A guide to convolution arithmetic for deep learning:https://arxiv.org/pdf/1603.07285.pdf